






导论
η
(
π
)
\eta(\pi)
η(π)代表在策略
π
\pi
π下产生一系列的回报函数
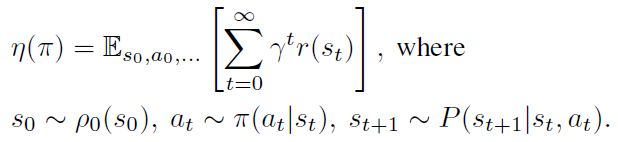
动作值函数,值函数,优势函数定义如下,这里的优势函数
A
π
A_\pi
Aπ表示采用某个动作的优劣

对于新的策略
π
~
\tilde{\pi}
π~,其回报函数
η
(
π
~
)
\eta(\tilde{\pi})
η(π~)可以写为旧策略的回报函数加一个其他项,写作
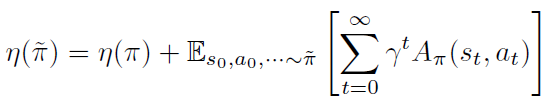
######证明分割线######
上式证明过程不难,原文可见,首先优势函数可写作
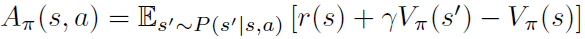
因此得证

######证明分割线######
进一步的,新策略的回报函数
η
(
π
~
)
\eta(\tilde{\pi})
η(π~)可以展开写作

其中,
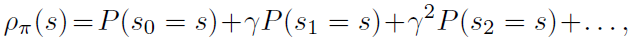
对于一个改进策略
π
~
\tilde{\pi}
π~,如果能做到
∑
a
π
~
(
a
∣
s
)
A
π
(
s
,
a
)
≥
0
\sum_a\tilde{\pi}(a|s)A_\pi(s,a)\ge0
∑aπ~(a∣s)Aπ(s,a)≥0,那么就说明改进策略的回报函数在递增,
π
~
\tilde{\pi}
π~比原策略
π
\pi
π更优秀,然而由于一些估计和近似误差,可能会导致
∑
a
π
~
(
a
∣
s
)
A
π
(
s
,
a
)
<
0
\sum_a\tilde{\pi}(a|s)A_\pi(s,a)<0
∑aπ~(a∣s)Aπ(s,a)<0,很难优化
η
(
π
~
)
\eta(\tilde{\pi})
η(π~),因此引入一个近似值
L
π
(
π
~
)
L_\pi(\tilde{\pi})
Lπ(π~)
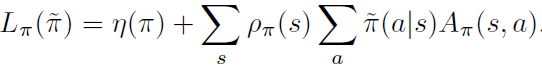
L
π
(
π
~
)
L_\pi(\tilde{\pi})
Lπ(π~)是
η
(
π
~
)
\eta(\tilde{\pi})
η(π~)的一阶近似,证明见Kakade & Langford (2002),原文链接,所以当
π
\pi
π变化不大时,偏差不会特别大。其具有以下性质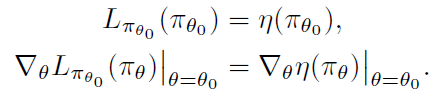
定理1

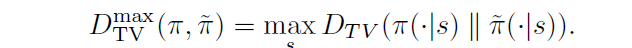
该定理的证明过程见原文proofB。在以上定理中,
α
\alpha
α代表
π
o
l
d
\pi_{old}
πold和
π
n
e
w
\pi_{new}
πnew之间的最大KL散度,用来衡量二者的区别,当二者区别不大时,由
ρ
\rho
ρ近似带来的误差不会太大,
η
\eta
η和
L
L
L相对比较接近。所以以优化
η
\eta
η的下界为目标,可以得到以下策略优化算法
算法1

TRPO算法相对于PG的优势由此可以体现,PG的更新步长选择不合适会无法找到全局最优点,不一定会让策略变好。但按照TRPO的策略更新公式,我们可以保证
η
\eta
η单调递增,从而得到一个单调递增的策略序列,这种算法也叫做 minorization-maximization (MM) 算法。由于
L
−
C
D
L-CD
L−CD的表达式很难直接优化,原文也提出了一些近似优化方法。
近似优化方法
- 惩罚转化为约束
首先 C C C作为惩罚项,可能会导致更新步长非常小,故原文首先将惩罚项转化为新旧策略KL散度的约束项

δ \delta δ应该是精确的常数,即 C C C的对偶,但无法精确计算,所以只能人为设定一个值。 - 平均散度替代最大散度
上式的约束项给状态空间的每个状态都增加了约束,这意味着给新旧策略的KL散度增加了大量的约束,这是很难求解的。所以原文用平均KL散度替代
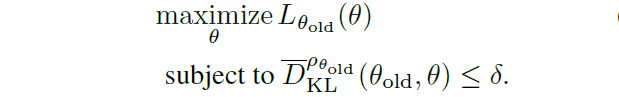

- 一些近似
根据以上两点,此时优化目标如下
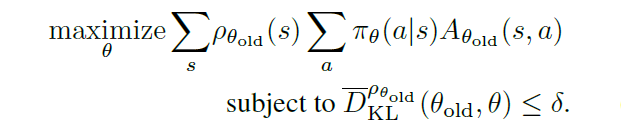
为了让这个问题更加数值可解,做出如下近似
(1) ∑ s ρ θ o l d ( s ) [ . . . ] \sum_s\rho\theta_{old}(s)[...] ∑sρθold(s)[...]由期望 1 / ( γ − 1 ) E s ∼ ρ θ o l d [ . . . ] 1/(\gamma-1)E_{s\sim\rho_{\theta{old}}}[...] 1/(γ−1)Es∼ρθold[...]代替
(2) A θ o l d A_{\theta_{old}} Aθold由 Q θ o l d Q_{\theta_{old}} Qθold代替
(3)采用重要性采样代替对 a a a的求和
于是优化目标变为

动作采样
原文提出了两种动作采样的方法
1. single path
2. vine















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









