






 本文详细解读了Trust Region Policy Optimization (TRPO)算法,重点讲解了其单调递增保证、策略优化过程中的理论与实践应用,以及与PPO的关系。TRPO通过约束策略更新,确保学习过程的稳健,尤其适合连续动作空间。
本文详细解读了Trust Region Policy Optimization (TRPO)算法,重点讲解了其单调递增保证、策略优化过程中的理论与实践应用,以及与PPO的关系。TRPO通过约束策略更新,确保学习过程的稳健,尤其适合连续动作空间。
TRPO、PPO是强化学习里比较重要的2种RL算法,由OpenAI于2015年发表,后来DeepMind于2017年基于TRPO发表了一篇DPPO(Distributed PPO),没过多久,OpenAI发表了PPO算法。
TRPO是PPO的前身,因此学习TRPO是必须的。
论文地址,点这里
其中一篇比较重要的Reference:Approximately optimal approximate reinforcement learning
论文参考:
《强化学习进阶 第七讲 TRPO》
《个人认为写得最好的TRPO讲解》
《TRPO和PPO(上)》
《深度强化学习之PG系算法笔记(二)TRPO算法》
《TRPO论文推导》
《深度强化学习之TRPO》
《深度强化学习–TRPO与PPO实现》
实战参考:莫凡python教学
TRPO:Trust Region Policy Optimization,即信任区域策略优化,我刚开始看到这个算法的时候,第一个疑问就是这个信任区域指的是什么?
- 这个信任区域本质上就是由一个约束条件产生的,其中的
δ
\delta
δ限定了我们策略参数
θ
\theta
θ的更新在一个范围内,这样的话就能避免传统RL算法那样,因为步长太大,导致参数
θ
\theta
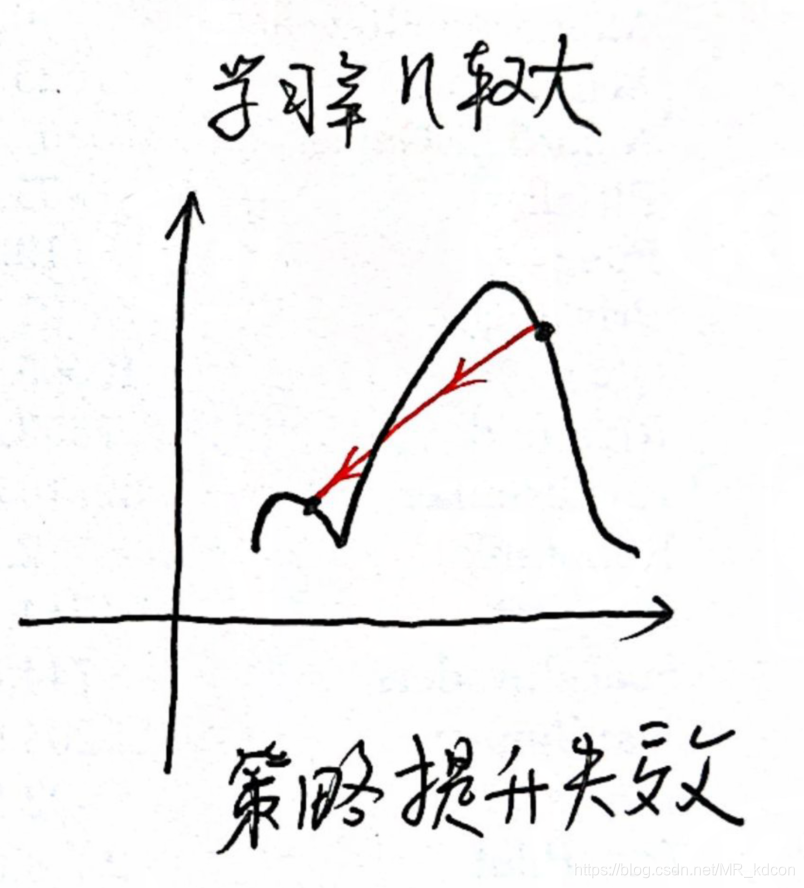
θ更新到一个比较糟糕的值。如下图所示:
 相反,如果
θ
\theta
θ的更新被我们限制在一个范围
θ
\theta
θ之内,那么新的策略参数
θ
\theta
θ就不至于更新幅度过大。因此这种被限定了的区域就值得我们去更新参数,我们就不用担心会出现策略提升失效的情况,即策略参数在这个区域内的更新是值得信赖的。
相反,如果
θ
\theta
θ的更新被我们限制在一个范围
θ
\theta
θ之内,那么新的策略参数
θ
\theta
θ就不至于更新幅度过大。因此这种被限定了的区域就值得我们去更新参数,我们就不用担心会出现策略提升失效的情况,即策略参数在这个区域内的更新是值得信赖的。 - 用一个形象的图片来说明上面所述:具体如下图所示:

TRPO论文的意义在于其背后的理论,对于实践而言更推荐PPO而非TRPO,所以TRPO要着重理解其背后的思想。
TRPO最难得部分在于其优化部分,再加上篇幅原因,我将其放在了另一篇里,文章地址在本篇论文解读的末端部分。
TRPO其实是为了解决策略梯度算法中学习率大小的问题,学习率的大小在PG定理中起着非常重要的作用。
Trust Region Policy Optimization
Abstract
- 个人认为TRPO最吸引人的地方在于策略的单调递增特性。也就是说策略的每一个step的对于值函数的提升是单调的增加的(严谨的说法是保证不减)。有的同学可能就会有疑问,我们之前的RL算法基于策略提升不都是递增的嘛。比如policy-based的算法中使用的策略梯度上升算法:
θ
←
θ
+
η
⋅
Δ
θ
\theta\gets\theta+\eta\cdot\Delta\theta
θ←θ+η⋅Δθ,其中性能度量
J
(
θ
)
J(\theta)
J(θ)我们一般采用值函数,那么根据梯度上升,我们的值函数应该是递增的,那么问题出在哪了呢?关键在于这个学习率
η
\eta
η。由于这个是个超参数,实践中需要我们进行调节,
η
\eta
η过大或者过小都会引起策略向着不好的方向发展,具体如下图所示:
 TRPO也无法做到避免第一种情况——局部最优。但是它可以避免传统RL算法因为
η
\eta
η过大导致策略提升失效。对于不同的task,多大的
η
\eta
η才是大的学习率呢?因此传统的RL算法就需要不断的调整学习率,总的来说不是个容易的事。但是TRPO可以避免这个情况,从而不用费劲去调节
η
\eta
η。因为TRPO保证了策略的每一次更新
π
→
π
∗
\pi\to\pi^*
π→π∗都使得值函数是单调不减的。
TRPO也无法做到避免第一种情况——局部最优。但是它可以避免传统RL算法因为
η
\eta
η过大导致策略提升失效。对于不同的task,多大的
η
\eta
η才是大的学习率呢?因此传统的RL算法就需要不断的调整学习率,总的来说不是个容易的事。但是TRPO可以避免这个情况,从而不用费劲去调节
η
\eta
η。因为TRPO保证了策略的每一次更新
π
→
π
∗
\pi\to\pi^*
π→π∗都使得值函数是单调不减的。 - TRPO是一种On-policy的随机性策略算法。
- TRPO属于Policy-based系列算法。
- TRPO还有一个优点是不需要调节超参数。
- 为了便于实践,TRPO进行了一系列的近似手法。
1 Introduction
TRPO有2种变体:
- single-path:就是我们用来学习非线性策略 π \pi π的model-free算法。
- vine:仅仅用于仿真。
2 Preliminaries
这篇论文中开始将RL的目标——期望累计奖励,用符号 η ( π ) \eta(\pi) η(π)表示: η ( π ) = E s 0 , a 0 , ⋯ ∼ π [ ∑ t = 0 ∞ γ t r ( s t ) ] \eta(\pi)=\mathbb{E}_{s_0,a_0,\cdots\sim\pi}[\sum^\infty_{t=0}\gamma^tr(s_t)] η(π)=Es0,a0,⋯∼π[t=0∑∞γtr(st)]我们通常用值函数来表示目标: Q π ( s t , a t ) = E s t + 1 , a t + 1 , ⋯ [ ∑ l = 0 ∞ γ l r ( s t + l ) ] V π ( s t ) = E a t , s t + 1 , ⋯ [ ∑ l = 0 ∞ γ l r ( s t + l ) ] Q^\pi(s_t,a_t)=\mathbb{E}_{s_{t+1},a_{t+1},\cdots}[\sum^\infty_{l=0}\gamma^lr(s_{t+l})]\\ V^\pi(s_t)=\mathbb{E}_{a_t,s_{t+1},\cdots}[\sum^\infty_{l=0}\gamma^lr(s_{t+l})] Qπ(st,at)=Est+1,at+1,⋯[l=0∑∞γlr(st+l)]Vπ(st)=Eat,st+1,⋯[l=0∑∞γlr(st+l)]TRPO算法的核心就是去考虑如何学习一个策略从而让性能度量 J J J单调不减。那么一个很直观的思想就是将新策略的性能度量 J ( π ~ ) J(\tilde{\pi}) J(π~)拆成前一个时间步旧的性能度量 J ( θ ) J(\theta) J(θ)加上某个东西 G G G。即 J ( π ~ ) = J ( π ) + G J(\tilde{\pi})=J(\pi)+G J(π~)=J(π)+G。那么如果每次更新都能保证 G G G非负,就能保证策略的单调性。那么其实这个等式是存在的: η ( π ~ ) = η ( π ) + E s 0 , a 0 , ⋯ ∼ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] (1) \eta(\tilde{\pi})=\eta(\pi)+\mathbb{E}_{s_0,a_0,\cdots\sim\tilde{\pi}}[\sum^\infty_{t=0}\gamma^tA^\pi(s_t,a_t)]\tag{1} η(π~)=η(π)+Es0,a0,⋯∼π~[t=0∑∞γtAπ(st,at)](1)Note:
- A A A为优势函数,我们在A2C、Dueling-network中都遇到过,满足: A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t , a t ) A^\pi(s_t,a_t)=Q^\pi(s_t,a_t)-V^\pi(s_t,a_t) Aπ(st,at)=Qπ(st,at)−Vπ(st,at)。
- 证明如下:

- 上述式子还有
2个特性,根据《Sutton强化学习》有 Q π ( s t , π ( a t ∣ s t ) ) = V π ( s t ) Q^\pi(s_t,\pi(a_t|s_t))=V^\pi(s_t) Qπ(st,π(at∣st))=Vπ(st),故有 E s t , a t ∼ π [ γ t A π ( s t , a t ) ] = 0 E s 0 , a 0 , ⋯ ∼ π [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] = 0 \mathbb{E}_{s_t,a_t\sim\pi}[\gamma^tA^\pi(s_t,a_t)]=0\\\mathbb{E}_{s_0,a_0,\cdots\sim\pi}[\sum^\infty_{t=0}\gamma^tA^\pi(s_t,a_t)]=0 Est,at∼π[γtAπ(st,at)]=0Es0,a0,⋯∼π[t=0∑∞γtAπ(st,at)]=0 - 式(1)告诉我们:新旧策略的回报差是存在的,它等于 E s 0 , a 0 , ⋯ ∼ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] \mathbb{E}_{s_0,a_0,\cdots\sim\tilde{\pi}}[\sum^\infty_{t=0}\gamma^tA^\pi(s_t,a_t)] Es0,a0,⋯∼π~[∑t=0∞γtAπ(st,at)],显然这个回报差可能正也可能负。
将新旧策略回报差利用“多变量展开”:
E
s
0
,
a
0
,
⋯
∼
π
~
[
∑
t
=
0
∞
γ
t
A
π
(
s
t
,
a
t
)
]
=
∑
s
∑
t
=
0
∞
γ
t
P
(
s
t
=
s
∣
π
~
)
∑
a
π
~
(
a
∣
s
t
)
A
π
(
s
t
,
a
)
\mathbb{E}_{s_0,a_0,\cdots\sim\tilde{\pi}}[\sum^\infty_{t=0}\gamma^tA^\pi(s_t,a_t)]=\sum_s\sum^\infty_{t=0}\gamma^tP(s_t=s|\tilde{\pi})\sum_a\tilde{\pi}(a|s_t)A^\pi(s_t,a)
Es0,a0,⋯∼π~[t=0∑∞γtAπ(st,at)]=s∑t=0∑∞γtP(st=s∣π~)a∑π~(a∣st)Aπ(st,a)定义
ρ
π
(
s
)
=
P
(
s
0
=
s
)
+
γ
P
(
s
1
=
s
)
+
γ
2
P
(
s
2
=
s
)
+
⋯
\rho_\pi(s)=P(s_0=s)+\gamma P(s_1=s)+\gamma^2P(s_2=s)+\cdots
ρπ(s)=P(s0=s)+γP(s1=s)+γ2P(s2=s)+⋯,则新旧策略回报差=
∑
s
ρ
π
~
(
s
)
∑
a
π
~
(
a
∣
s
)
A
π
(
s
,
a
)
(2)
\sum_s\rho_{\tilde{\pi}}(s)\sum_a\tilde{\pi}(a|s)A^\pi(s,a)\tag{2}
s∑ρπ~(s)a∑π~(a∣s)Aπ(s,a)(2)Note:
- 式(2)还可以用“双变量期望”合起来: E s ∼ ρ π ~ , a ∼ π ~ [ A π ( s , a ) ] \mathbb{E}_{s\sim\rho_{\tilde{\pi}},a\sim\tilde{\pi}}[A^\pi(s,a)] Es∼ρπ~,a∼π~[Aπ(s,a)]。
- ρ π ( s ) \rho_\pi(s) ρπ(s)并不是我们常见的同轨策略分布 ρ π ( s ) \rho^\pi(s) ρπ(s),两者是有区别的。并且 ρ π \rho_\pi ρπ没有经过归一化,如果要进行归一化,需要除以 1 1 − γ \frac{1}{1-\gamma} 1−γ1。
- 从式(2)可以看出,当我们保证 ∑ a π ~ ( a ∣ s ) A π ( s , a ) ≥ 0 \sum_a\tilde{\pi}(a|s)A^\pi(s,a)\ge0 ∑aπ~(a∣s)Aπ(s,a)≥0的时候,就可以保证新策略是比就策略好的。
第一处近似
作者指出,式(2)中带有的
ρ
π
~
\rho_{\tilde{\pi}}
ρπ~或造成整个式子难以直接优化,个人认为是我们在写代码的时候,更容易去实现旧策略
ρ
π
\rho_\pi
ρπ(
π
\pi
π为当前策略,下个step就要更新)而不是新策略
ρ
π
~
\rho_{\tilde{\pi}}
ρπ~,所以要做这个近似。并且用一个新的符号
L
π
(
π
~
)
L_\pi(\tilde{\pi})
Lπ(π~)来表示相对旧策略的新策略产生的回报。因此式(2)更新为:
L
π
(
π
~
)
=
η
(
π
)
+
∑
s
ρ
π
(
s
)
∑
a
π
~
(
a
∣
s
)
A
π
(
s
,
a
)
(3)
L_\pi(\tilde{\pi})=\eta(\pi)+\sum_s\rho_\pi(s)\sum_a\tilde{\pi}(a|s)A^\pi(s,a)\tag{3}
Lπ(π~)=η(π)+s∑ρπ(s)a∑π~(a∣s)Aπ(s,a)(3)接下来作者参考Kakade在2002年发表的一篇论文,给出了以下结论:当策略网络
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s)可微的时候,将
L
π
θ
0
(
π
θ
)
L_{\pi_{\theta_0}}(\pi_\theta)
Lπθ0(πθ)和
η
(
π
θ
)
\eta(\pi_\theta)
η(πθ)看成关于变量
π
θ
\pi_\theta
πθ的函数,那么对于
∀
θ
0
\forall \theta_0
∀θ0有
L
π
θ
0
(
π
θ
0
)
=
η
(
π
θ
0
)
,
∇
θ
L
π
θ
0
(
π
θ
)
∣
θ
=
θ
0
=
∇
θ
η
(
π
θ
)
∣
θ
=
θ
0
(4)
L_{\pi_{\theta_0}}(\pi_{\theta_0})=\eta(\pi_{\theta_0}),\\ \nabla_\theta L_{\pi_{\theta_0}}(\pi_\theta)|_{\theta=\theta_0}=\nabla_\theta\eta(\pi_\theta)|_{\theta=\theta_0}\tag{4}
Lπθ0(πθ0)=η(πθ0),∇θLπθ0(πθ)∣θ=θ0=∇θη(πθ)∣θ=θ0(4)用图可以表示成: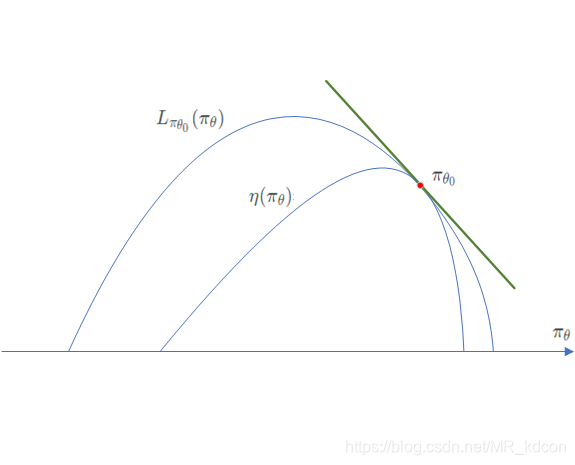 Note:
Note:
- 其中第一个式子用式(1)的2个特性即可解决,对于第二个式子的证明可参考这位博主写的笔记。
- 式(4)告诉我们在一个很小的步伐 π θ 0 → π ~ \pi_{\theta_0}\to\tilde{\pi} πθ0→π~上( π θ 0 \pi_{\theta_0} πθ0就相当于旧策略,或者说当前策略,还未更新),提升 L π 0 L_{\pi_0} Lπ0就会提升 η \eta η(导数的定义)。
- 式(4)提供了一个思路,就是想办法在旧策略的邻域 ( − δ , δ ) (-\delta,\delta) (−δ,δ)内去提升 L L L,但问题就是这个 δ \delta δ无法得知是多少。为了解决这个问题,Kakada提出了一种叫Conservative policy iteration的算法,它给出了关于 η \eta η的下界。
定义
π
′
=
arg max
π
L
π
o
l
d
(
π
)
\pi'=\argmax_\pi L_{\pi_{old}}(\pi)
π′=πargmaxLπold(π),则新策略
π
n
e
w
\pi_{new}
πnew表示成当前策略和贪婪策略的混合:
π
n
e
w
(
a
∣
s
)
=
(
1
−
α
)
π
o
l
d
(
a
∣
s
)
+
α
π
′
(
a
∣
s
)
(5)
\pi_{new}(a|s)=(1-\alpha)\pi_{old}(a|s)+\alpha\pi'(a|s)\tag{5}
πnew(a∣s)=(1−α)πold(a∣s)+απ′(a∣s)(5),接下来Kakada就导出了一个不等式:
η
(
π
n
e
w
)
≥
L
π
o
l
d
(
π
n
e
w
)
−
2
ϵ
γ
(
1
−
γ
)
2
α
2
ϵ
=
max
s
∣
E
a
∼
π
′
[
A
π
(
s
,
a
)
]
∣
(6)
\eta(\pi_{new})\ge L_{\pi_{old}}(\pi_{new})-\frac{2\epsilon\gamma}{(1-\gamma)^2}\alpha^2\\ \epsilon=\max_s|\mathbb{E}_{a\sim\pi'}[A^\pi(s,a)]|\tag{6}
η(πnew)≥Lπold(πnew)−(1−γ)22ϵγα2ϵ=smax∣Ea∼π′[Aπ(s,a)]∣(6)Note:
- π o l d \pi_{old} πold在其他论文可能只带Target策略,在这里指代的是当前策略。
- 式(6)只适用于式(5)这种混合策略。作者指出式(5)是实践中还是很难去处理的,因此接下来作者将会做一些处理使得从适用于混合策略延展到适用于普遍的策略。
- 式(6)的意义在于如果策略的更新 π o l d → π n e w \pi_{old}\to\pi_{new} πold→πnew使得式(6)右边的提升,那么就保证了 η \eta η的提升,这就是我们想要的。
3 Monotonic Improvement Guarantee for General Stochastic Policies

式(6)提供了策略单调不减的框架,但是其不适用于普遍的策略,因此这一节的目的就是创造式(6)的普适性。
改变
α
\alpha
α
定义
D
T
V
(
p
∣
∣
q
)
=
1
2
∑
i
∣
p
i
−
q
i
∣
D_{TV}(p||q)=\frac{1}{2}\sum_i|p_i-q_i|
DTV(p∣∣q)=21∑i∣pi−qi∣,则
α
=
D
T
V
m
a
x
(
π
,
π
~
)
=
max
s
D
T
V
(
π
(
⋅
∣
s
)
,
π
~
(
⋅
∣
s
)
)
(7)
\alpha=D_{TV}^{max}(\pi,\tilde{\pi})=\max_sD_{TV}(\pi(\cdot|s),\tilde{\pi}(\cdot|s))\tag{7}
α=DTVmax(π,π~)=smaxDTV(π(⋅∣s),π~(⋅∣s))(7)
改变
ϵ
\epsilon
ϵ
ϵ
=
max
s
,
a
∣
A
π
(
s
,
a
)
∣
\epsilon=\max_{s,a}|A^\pi(s,a)|
ϵ=s,amax∣Aπ(s,a)∣
接下来给出定理1:
Theorem 1.
令
α
=
D
T
V
m
a
x
(
π
o
l
d
∣
∣
π
n
e
w
)
,
ϵ
=
max
s
,
a
∣
A
π
(
s
,
a
)
∣
\alpha=D_{TV}^{max}(\pi_{old}||\pi_{new}),\epsilon=\max_{s,a}|A^\pi(s,a)|
α=DTVmax(πold∣∣πnew),ϵ=maxs,a∣Aπ(s,a)∣,则:
η
(
π
n
e
w
)
≥
L
π
o
l
d
(
π
n
e
w
)
−
4
ϵ
γ
(
1
−
γ
)
2
α
2
(8)
\eta(\pi_{new})\ge L_{\pi_{old}}(\pi_{new})-\frac{4\epsilon\gamma}{(1-\gamma)^2}\alpha^2\tag{8}
η(πnew)≥Lπold(πnew)−(1−γ)24ϵγα2(8)Note:
- 作者提供了2种证明方式,具体见附录部分。
进一步地,因为 D T V ( p ∣ ∣ q ) 2 ≤ D K L ( p ∣ ∣ q ) D_{TV}(p||q)^2\leq D_{KL}(p||q) DTV(p∣∣q)2≤DKL(p∣∣q),并定义 D K L m a x ( π , π ~ ) = max s D K L ( π ( ⋅ ∣ s ) , π ~ ( ⋅ ∣ s ) ) D_{KL}^{max}(\pi,\tilde{\pi})=\max_sD_{KL}(\pi(\cdot|s),\tilde{\pi}(\cdot|s)) DKLmax(π,π~)=maxsDKL(π(⋅∣s),π~(⋅∣s)),那么式(8)可改为 η ( π ~ ) ≥ L π ( π ~ ) − C D K L m a x ( π , π ~ ) C = 4 ϵ γ ( 1 − γ ) 2 (9) \eta(\tilde{\pi})\ge L_\pi(\tilde{\pi})-CD^{max}_{KL}(\pi,\tilde{\pi})\\C=\frac{4\epsilon\gamma}{(1-\gamma)^2}\tag{9} η(π~)≥Lπ(π~)−CDKLmax(π,π~)C=(1−γ)24ϵγ(9)
接下来就是全文最重要的部分了,作者给出了如何使得策略得到单调提升,即
η
(
π
0
)
≤
η
(
π
1
)
≤
η
(
π
2
)
≤
⋯
\eta(\pi_0)\leq\eta(\pi_1)\leq\eta(\pi_2)\leq\cdots
η(π0)≤η(π1)≤η(π2)≤⋯。证明如下:
Note:
- 上述证明告诉我们,想要获取单调递增的回报,只需要对 M i M_i Mi进行优化,即 π i + 1 = arg max π [ L π i ( π ) − C D K L m a x ( π i , π ) ] \pi_{i+1}=\argmax_\pi[L_{\pi_i}(\pi)-CD^{max}_{KL}(\pi_i,\pi)] πi+1=πargmax[Lπi(π)−CDKLmax(πi,π)],因此我们再返回来看式(9),就可以发现TRPO其实是一种MM算法,我们已知 η ( π ~ ) \eta(\tilde{\pi}) η(π~)的下界,然后对下界求最大,从而优化出一个符合我们目标的 π ~ \tilde{\pi} π~。
综上所述,就产生了Algorithm 1: Note:
Note:
- K L KL KL散度在Algorithm 1中是以奖惩项(正则项)的形式出现的,下一节作者将该项以约束的形式进行转化。这种转换在其他算法中也很常见,比如SAC的提升版本就是将熵项放到了约束里面。
- Algorithm 1还只是
理论层面的,距离实践还需要接下来的一些处理。
4 Optimization of Parameterized Policies
这一节的主要目的就是将上述Theorem 1通过一些手段转变为实用的算法。
首先第一步就是将策略参数化,常见的就是用神经网络
θ
\theta
θ来表示
π
θ
(
a
t
∣
s
t
)
\pi_\theta(a_t|s_t)
πθ(at∣st)。
于是我们的核心优化公式就变成了:
m
a
x
i
m
i
z
e
θ
[
L
θ
o
l
d
(
θ
)
−
C
D
K
L
m
a
x
(
θ
o
l
d
,
θ
)
]
\mathop{maximize}\limits_{\theta}[L_{\theta_{old}}(\theta)-CD^{max}_{KL}(\theta_{old},\theta)]
θmaximize[Lθold(θ)−CDKLmax(θold,θ)]Note:
- θ o l d \theta_{old} θold在这里不是Target策略参数,而是指代当前策略,指未更新前的,或者说相对于新策略 θ \theta θ的旧策略。
第二步就是将最大
K
L
KL
KL散度这个奖惩项拉到约束里去。之所以要这么做,是因为惩罚系数
C
=
4
ϵ
γ
(
1
−
γ
)
2
C=\frac{4\epsilon\gamma}{(1-\gamma)^2}
C=(1−γ)24ϵγ值太大了(通常
γ
=
0.95
∼
0.995
\gamma=0.95\sim0.995
γ=0.95∼0.995之间),从而在优化过程中会加大对
K
L
KL
KL散度的偏倚,又因为优化是求最大值,因此奖惩项会变得很小很小,根据
K
L
KL
KL散度的特点,策略的更新步伐就会很小,训练速度很缓慢,因此显然将最大KL散度当成奖惩项不是很合适,那么自然地做法就是将其转变为约束。
具体做法:
m
a
x
i
m
i
z
e
θ
L
θ
o
l
d
(
θ
)
s
.
t
.
D
K
L
m
a
x
(
θ
o
l
d
,
θ
)
≤
δ
(11)
\mathop{maximize}\limits_\theta L_{\theta_{old}}(\theta)\\ s.t.\,D^{max}_{KL}(\theta_{old},\theta)\leq\delta\tag{11}
θmaximizeLθold(θ)s.t.DKLmax(θold,θ)≤δ(11)Note:
-
式(11)的约束就是策略参数的置信区域,也就是TRPO名称的由来,它约束了参数 θ \theta θ的值不会更新幅度太大,从而造成策略提升失效的现象,也就是说在 δ \delta δ约束范围之内,可以放心的去按照目标函数去优化参数 θ \theta θ。对于每一个step,都会在安全的区域内进行更新,可以用下图直观的表示Algorithm 1每一步的策略更新:

-
最大 K L KL KL散度转为约束之后,取消了奖惩系数,就不存在更新步伐过小的现象了。
第二处近似
第三步就是用平均
K
L
KL
KL散度代替最大
K
L
KL
KL散度。之所以这么做,是因为最大
K
L
KL
KL散度需要遍历每一个状态
s
s
s,从而在实际中变得计算量过大。平均
K
L
KL
KL散度通过期望的形式可以用批量样本的方式去近似,类似于TD算法之于贝尔曼等式的关系。定义:
D
ˉ
K
L
ρ
(
θ
1
,
θ
2
)
=
E
s
∼
ρ
[
D
K
L
(
π
θ
1
(
⋅
∣
s
)
∣
∣
π
θ
2
(
⋅
∣
s
)
)
]
\bar{D}^\rho_{KL}(\theta_1,\theta_2)=\mathbb{E}_{s\sim\rho}[D_{KL}(\pi_{\theta_1}(\cdot|s)||\pi_{\theta_2}(\cdot|s))]
DˉKLρ(θ1,θ2)=Es∼ρ[DKL(πθ1(⋅∣s)∣∣πθ2(⋅∣s))],那么我们的优化目标进一步改为:
m
a
x
i
m
i
z
e
θ
L
θ
o
l
d
(
θ
)
s
.
t
.
D
ˉ
K
L
ρ
θ
o
l
d
(
θ
o
l
d
,
θ
)
≤
δ
(12)
\mathop{maximize}\limits_\theta L_{\theta_{old}}(\theta)\\ s.t.\,\bar{D}_{KL}^{\rho_{\theta_{old}}}(\theta_{old},\theta)\leq\delta\tag{12}
θmaximizeLθold(θ)s.t.DˉKLρθold(θold,θ)≤δ(12)
5 Sample-Based Estimation of the Objective and Constraint
这一节主要是将上一节推演的目标和约束进行近似处理,从而产生最终用于实践的算法。
第三处近似
我们将式(12)进行展开,故式(12)的优化等效于:
m
a
x
i
m
i
z
e
θ
∑
s
ρ
θ
o
l
d
(
s
)
∑
a
π
θ
(
a
∣
s
)
A
θ
o
l
d
(
s
,
a
)
s
.
t
.
D
ˉ
K
L
ρ
θ
o
l
d
(
θ
o
l
d
,
θ
)
≤
δ
(13)
\mathop{maximize}\limits_\theta\sum_s\rho_{\theta_{old}}(s)\sum_a\pi_\theta(a|s)A_{\theta_{old}}(s,a)\\ s.t.\,\bar{D}_{KL}^{\rho_{\theta_{old}}}(\theta_{old},\theta)\leq\delta\tag{13}
θmaximizes∑ρθold(s)a∑πθ(a∣s)Aθold(s,a)s.t.DˉKLρθold(θold,θ)≤δ(13)第三处近似包括了3个小近似点:
- 用 1 1 − γ E s ∼ ρ θ o l d [ ⋯ ] \frac{1}{1-\gamma}\mathbb{E}_{s\sim\rho_{\theta_{old}}}[\cdots] 1−γ1Es∼ρθold[⋯]去取代 ∑ s ρ θ o l d ( s ) [ ⋯ ] \sum_s\rho_{\theta_{old}}(s)[\cdots] ∑sρθold(s)[⋯]。至于这里为啥要多个 1 1 − γ \frac{1}{1-\gamma} 1−γ1呢?是因为你变期望的时候,下标 ρ θ o l d \rho_{\theta_{old}} ρθold必须是经过归一化的概率,他们必须满足和为1,而在第二节中我们提及 ρ \rho ρ如果要归一化必须除以 1 1 − γ \frac{1}{1-\gamma} 1−γ1,也就是说当你写成期望的形式,就默认 ρ \rho ρ是经过归一化的了,而我们式(13)的 ρ \rho ρ是没有经过归一化的,因此需乘以一个 1 1 − γ \frac{1}{1-\gamma} 1−γ1来进行抵消。
- 优势函数
A
A
A里面包含了
Q
(
s
,
a
)
−
V
(
s
)
Q(s,a)-V(s)
Q(s,a)−V(s),显然我们的目标是
θ
\theta
θ,关于
V
V
V这部分相当于一个
常数,故在优化过程中会消失,因此我们可以直接用 Q θ o l d ( s , a ) Q_{\theta_{old}}(s,a) Qθold(s,a)来取代 A θ o l d ( s , a ) A_{\theta_{old}}(s,a) Aθold(s,a)。 - 第三个近似点使用了
重要性采样技术,因为无法从策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s)中进行采样,毕竟 π θ \pi_\theta πθ是个未来的分布,是未知的,但可以进行计算、求梯度。因此需要一个容易采样的分布 q q q,给出式子: ∑ a π θ ( a ∣ s n ) A θ o l d ( s n , a ) = E a ∼ q [ π θ ( a ∣ s n ) q ( a ∣ s n ) A θ o l d ( s n , a ) ] \sum_a\pi_\theta(a|s_n)A_{\theta_{old}}(s_n,a)=\mathbb{E}_{a\sim q}[\frac{\pi_\theta(a|s_n)}{q(a|s_n)}A_{\theta_{old}}(s_n,a)] a∑πθ(a∣sn)Aθold(sn,a)=Ea∼q[q(a∣sn)πθ(a∣sn)Aθold(sn,a)]通过优化这个式子去更新参数 θ \theta θ。
结合上述3个实践处理点以及3处近似(第三处近似包括3个小近似),我们可以得到最终用于实践的优化目标:
m
a
x
i
m
i
z
e
θ
E
s
∼
ρ
θ
o
l
d
,
a
∼
q
[
π
θ
(
a
∣
s
)
q
(
a
∣
s
)
Q
θ
o
l
d
(
s
,
a
)
]
s
.
t
.
E
s
∼
ρ
θ
o
l
d
[
D
K
L
(
π
θ
o
l
d
(
⋅
∣
s
)
∣
∣
π
θ
(
⋅
∣
s
)
)
]
≤
δ
(14)
\mathop{maximize}\limits_\theta\mathbb{E}_{s\sim\rho_{\theta_{old}},a\sim q}[\frac{\pi_\theta(a|s)}{q(a|s)}Q_{\theta_{old}}(s,a)]\\ s.t.\,\mathbb{E}_{s\sim\rho_{\theta_{old}}}[D_{KL}(\pi_{\theta_{old}}(\cdot|s)||\pi_\theta(\cdot|s))]\leq\delta\tag{14}
θmaximizeEs∼ρθold,a∼q[q(a∣s)πθ(a∣s)Qθold(s,a)]s.t.Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ(14)Note:
- 和TD算法之于贝尔曼等式一样,对于式(14),我们要做的就是采样,然后求和取平均。对于 Q Q Q值,通过MC方法进行估计得到。
接下来作者将介绍2种采样方式——Single Path和Vine。
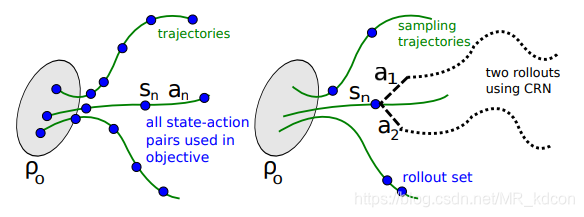
5.1 Single Path
Single-Path就像我们普通算法产生样本一样:
s
0
∼
ρ
0
,
q
(
a
∣
s
)
=
π
θ
o
l
d
(
a
∣
s
)
s_0\sim\rho_0,\\q(a|s)=\pi_{\theta_{old}}(a|s)
s0∼ρ0,q(a∣s)=πθold(a∣s)从而产生一条条轨迹:
s
0
,
a
0
,
s
1
,
a
1
,
⋯
s
T
−
1
,
a
T
−
1
,
s
T
s
0
,
a
0
,
s
1
,
a
1
,
⋯
s
T
−
1
,
a
T
−
1
,
s
T
⋯
s
0
,
a
0
,
s
1
,
a
1
,
⋯
s
T
−
1
,
a
T
−
1
,
s
T
s_0,a_0,s_1,a_1,\cdots s_{T-1},a_{T-1},s_T\\ s_0,a_0,s_1,a_1,\cdots s_{T-1},a_{T-1},s_T\\ \cdots\\ s_0,a_0,s_1,a_1,\cdots s_{T-1},a_{T-1},s_T
s0,a0,s1,a1,⋯sT−1,aT−1,sTs0,a0,s1,a1,⋯sT−1,aT−1,sT⋯s0,a0,s1,a1,⋯sT−1,aT−1,sT
Note:
- MC方法的缺陷在于
方差较大。 - 具体的示意图如下:

- 每一个 Q θ o l d ( s , a ) Q_{\theta_{old}}(s,a) Qθold(s,a)通过该条轨迹上的累积衰减奖励之和可得。
- 接下来利用样本求平均去估计式(14)的目标与约束。然后进行优化。
5.2 Vine(藤蔓)
这个方法就和Vine的中文名——藤蔓一样,会产生很多分支。
具体来说:
①初始状态
s
0
∼
ρ
0
s_0\sim\rho_0
s0∼ρ0,然后会产生很多条轨迹。
②在这么多轨迹上选取
N
N
N个状态
s
0
,
s
1
,
s
2
,
⋯
,
s
N
s_0,s_1,s_2,\cdots,s_N
s0,s1,s2,⋯,sN。
③然后对每个状态取
K
K
K个动作,即
K
K
K条roll-out,因此Vine应该算Roll-out算法,是一种只估计每一个当前状态的值函数的在仿真轨迹上学习的方法。如下图所示:
在实践中,
a
n
,
k
∼
q
(
⋅
∣
s
n
)
=
π
θ
i
(
⋅
∣
s
n
)
a_{n,k}\sim q(\cdot|s_n)=\pi_{\theta_i}(\cdot|s_n)
an,k∼q(⋅∣sn)=πθi(⋅∣sn)适用于连续动作空间环境;
q
(
⋅
∣
s
n
)
=
u
n
i
f
o
r
m
q(\cdot|s_n)=uniform
q(⋅∣sn)=uniform策略适用于离散动作空间环境。
Note:
- 每一个 Q θ i ( s n , a n , k ) Q_{\theta_i}(s_n,a_{n,k}) Qθi(sn,an,k)通过该条roll-out上的累积衰减奖励之和来计算。
- 对于同一个状态
s
n
s_n
sn的不同roll-out使用common random numbers(CRN)可以有效减少不同roll-out之间的方差。关于CRN:

④对于较小的动作空间环境
A
=
{
a
1
,
a
2
,
⋯
,
a
K
}
\mathcal{A}=\{a_1,a_2,\cdots,a_K\}
A={a1,a2,⋯,aK},
L
θ
o
l
d
L_{\theta_{old}}
Lθold在单个
s
n
s_n
sn上的回报为:
L
n
(
θ
)
=
∑
k
=
1
K
π
θ
(
a
k
∣
s
n
)
Q
(
s
n
,
a
k
)
(15)
L_n(\theta)=\sum^K_{k=1}\pi_\theta(a_k|s_n)Q(s_n,a_k)\tag{15}
Ln(θ)=k=1∑Kπθ(ak∣sn)Q(sn,ak)(15)然后在
s
n
∼
ρ
s_n\sim\rho
sn∼ρ采样取平均,就可以得到
L
θ
o
l
d
L_{\theta_{old}}
Lθold。
⑤对于较大的动作空间环境,
L
θ
o
l
d
L_{\theta_{old}}
Lθold在单个
s
n
s_n
sn上的回报为:
L
n
(
θ
)
=
∑
k
=
1
K
π
θ
(
a
n
,
k
∣
s
n
)
π
θ
o
l
d
(
a
n
,
k
∣
s
n
)
Q
(
s
n
,
a
n
,
k
)
∑
k
=
1
K
π
θ
(
a
n
,
k
∣
s
n
)
π
θ
o
l
d
(
a
n
,
k
∣
s
n
)
(16)
L_n(\theta)=\frac{\sum^K_{k=1}\frac{\pi_\theta(a_{n,k}|s_n)}{\pi_{\theta_{old}}(a_{n,k}|s_n)}Q(s_n,a_{n,k})}{\sum^K_{k=1}\frac{\pi_\theta(a_{n,k}|s_n)}{\pi_{\theta_{old}}(a_{n,k}|s_n)}}\tag{16}
Ln(θ)=∑k=1Kπθold(an,k∣sn)πθ(an,k∣sn)∑k=1Kπθold(an,k∣sn)πθ(an,k∣sn)Q(sn,an,k)(16)Note:
- 使用了
IS技术,个人认为是大动作空间环境 ∣ A ∣ > K |\mathcal{A}|> K ∣A∣>K,当我们需要选 K K K个动作的时候,需要有一个分布来进行采样,而 π θ \pi_\theta πθ带有参数,是未知的,无法进行动作采样。 - 然后在 s n ∼ ρ s_n\sim\rho sn∼ρ采样取平均,就可以得到 L θ o l d L_{\theta_{old}} Lθold。
- 式(16)进行了
归一化处理,因为 K < ∣ A ∣ K<|\mathcal{A}| K<∣A∣,所以想要化成期望的话必须是的概率之和为1.
综上所述:
- Vine方法因为可以使用CRN技术,故拥有更低的方差。
- 2种方法都通过MC去估计 Q Q Q值。
- Vine方法无法像Single-Path那样,可以从任意状态
s
s
s出发去产生轨迹,相反,Vine只能用于
仿真,在仿真中选择一些状态。
6 Practical Algorithm
这一节主要是讲如何去优化经过采样之后式(14)。
先来总结一下算法流程:
- 使用Single-Path或者Vine方法进行采样并用MC估计出 Q θ o l d Q_{\theta_{old}} Qθold。
- 利用采样平均去估计(计算)式(14)。
- 优化第二步的目标函数,更新 θ \theta θ。作者采用共轭梯度法+线性搜索进行优化处理。
共轭梯度法(CG)是最速下降法(可以看成是学习率不固定的梯度下降法)的改进。理论上共轭梯度法产生的参数更新方向应该是使得式(14)最大化的合适方向
ϕ
\phi
ϕ,但由于约束的存在,使得这个理论方向会做出更改,因此接下去会使用线性搜索,尝试
ϕ
、
1
2
ϕ
、
1
4
ϕ
、
1
8
ϕ
⋯
\phi、\frac{1}{2}\phi、\frac{1}{4}\phi、\frac{1}{8}\phi\cdots
ϕ、21ϕ、41ϕ、81ϕ⋯,知道目标得到了提升。
具体的优化流程如下:
Note:
- 最后一步的 α \alpha α取决于线性搜索。
- 本文的目标函数是求最大,所以是梯度上升。
- 对于 θ \theta θ的每一次迭代,用Hessian-Free处理的共轭梯度法算出方向之后,都要用约束条件去修正这个方向。
由于篇幅原因,上述只是简单的描述了下大致优化过程,关于TRPO的具体优化部分,可以参考我的另一篇强化学习算法TRPO之共轭梯度优化。
7 Connections with Prior Work
略
8 Experiments
略
9 Discussion
略
10 总结
- TRPO最重要的地方在于它提供了一种
策略单调不减的算法,每一个step得更新都可以保证回报单调不减。 - TRPO将Kakada的一个重要
不等式(6)中的 α 、 ϵ \alpha、\epsilon α、ϵ进行改变,从而证明出适用于普遍策略的式(8)。 - 本文一共使用了3处近似(其中第三处中包含3个小近似点)。
从理论算法到实践算法经历了3步:参数化、奖惩项转约束项、最大 K L KL KL散度替换成平均 K L KL KL散度。- 介绍了2种采样方式Single-Path和Vine。
- TRPO使用
共轭梯度进行优化更新参数 θ \theta θ,也是本文最难理解的地方。 - 在AC框架中,我们往往把Actor部分看成是策略提升的一种方式,那么如何将TRPO理论上的策略提升与标准的策略提升定理对应起来呢?
首先我们回顾下标准的策略提升是怎么样的:
策略提升定理:如果 π 、 π ′ \pi、\pi' π、π′是两个不同的策略,如果对于 ∀ s ∈ S \forall\,s\in\mathcal{S} ∀s∈S,有: q π ( s , π ′ ( s ) ) ≥ v π ( s ) q^\pi(s,\pi'(s))\ge v^\pi(s) qπ(s,π′(s))≥vπ(s),则新策略 π ′ \pi' π′比旧策略 π \pi π一样好或更好,即:
v π ′ ( s ) ≥ v π ( s ) v^{\pi'}(s)\ge v^\pi(s) vπ′(s)≥vπ(s)然后再来看TRPO的提升方式:
关键在于三个式子
①: η ( π ) = E s 0 , a 0 , ⋯ ∼ π [ ∑ t = 0 ∞ γ t r ( s t ) ] , s 0 ∼ ρ 0 ( s 0 ) , a t ∼ π ( a t ∣ s t ) \eta(\pi)=\mathbb{E}_{s_0,a_0,\cdots\sim\pi}[\sum^\infty_{t=0}\gamma^tr(s_t)],s_0\sim\rho_0(s_0),a_t\sim\pi(a_t|s_t) η(π)=Es0,a0,⋯∼π[∑t=0∞γtr(st)],s0∼ρ0(s0),at∼π(at∣st)
②: η ( π ~ ) ≥ L π ( π ~ ) − C D K L m a x ( π , π ~ ) \eta(\tilde{\pi})\ge L_\pi(\tilde{\pi})-CD^{max}_{KL}(\pi,\tilde{\pi}) η(π~)≥Lπ(π~)−CDKLmax(π,π~)
③: m a x i m i z e θ E s ∼ ρ θ o l d , a ∼ q [ π θ ( a ∣ s ) q ( a ∣ s ) Q θ o l d ( s , a ) ] s . t . E s ∼ ρ θ o l d [ D K L ( π θ o l d ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ] ≤ δ \mathop{maximize}\limits_\theta\mathbb{E}_{s\sim\rho_{\theta_{old}},a\sim q}[\frac{\pi_\theta(a|s)}{q(a|s)}Q_{\theta_{old}}(s,a)]\\ s.t.\,\mathbb{E}_{s\sim\rho_{\theta_{old}}}[D_{KL}(\pi_{\theta_{old}}(\cdot|s)||\pi_\theta(\cdot|s))]\leq\delta θmaximizeEs∼ρθold,a∼q[q(a∣s)πθ(a∣s)Qθold(s,a)]s.t.Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
从式③可以看出,理论上对于式①下标这样的轨迹中的每一个状态 s s s,都可以对式(14)的提升做出贡献。再看式②,因为式③就相当于式②的右边部分的优化,所以式③的更新使得新的策略 π ~ \tilde{\pi} π~让右边提升,那么左边 η ( π ~ ) \eta(\tilde{\pi}) η(π~)也得到了提升,我们将左边看成 v π ~ ( s ) v^{\tilde{\pi}}(s) vπ~(s),就可以得出一个结论:对于参与过式③提升的每一个状态 s s s,都有 v π ~ ( s ) ≥ v π ( s ) v^{\tilde{\pi}}(s)\ge v^\pi(s) vπ~(s)≥vπ(s),看到这个式子就很熟悉了吧!这里的理解你可以把式③的更新看成是单样本更新,因为式②不等式告诉我们更新的结果是 η ( π ~ ) ≥ η ( π ) \eta(\tilde{\pi})\ge\eta(\pi) η(π~)≥η(π),这里我们假如说这个单样本是状态 s i s_i si,而 e t a eta eta是可以写成状态 s i s_i si之前的奖励和加上状态 s i s_i si的值函数的形式的,因此很容易得出 v π ~ ( s i ) ≥ v π ( s i ) v^{\tilde{\pi}}(s_i)\ge v^\pi(s_i) vπ~(si)≥vπ(si)。
再来看式①, η ( π ) \eta(\pi) η(π)到 η ( π ~ ) \eta(\tilde{\pi}) η(π~)的转变相当于是 a t ∼ π a_t\sim\pi at∼π到 a t ∼ π ~ ( a t ∣ s t ) a_t\sim\tilde{\pi}(a_t|s_t) at∼π~(at∣st)的改变。把上述结论用在式①上,对于轨迹上 < s 0 , a 0 . s 1 , a 1 ⋯ > <s_0,a_0.s_1,a_1\cdots> <s0,a0.s1,a1⋯>的每一个状态 s s s,新的策略产生的动作会比旧的更好,好在哪?—— v π ~ ( s ) ≥ v π ( s ) v^{\tilde{\pi}}(s)\ge v^\pi(s) vπ~(s)≥vπ(s)。我们将式①看成 Q Q Q函数,那么 ∀ s ∈ ρ π ( s ) \forall\,s \in\rho_\pi(s) ∀s∈ρπ(s), q π ( s , π ′ ( s ) ) ≥ q π ( s , π ( s ) ) = v π ( s ) q^\pi(s,\pi'(s))\ge q^\pi(s,\pi(s))=v^\pi(s) qπ(s,π′(s))≥qπ(s,π(s))=vπ(s)这样一来,TRPO的策略提升就和标准的策略提升定理对应起来了。

















 3258
3258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









