






 本文解析了TRPO中的优化过程,涉及目标函数的二次型转换、学习率修正、线性搜索及Hessian-Free技术的应用。通过泰勒展开和拉格朗日乘子法,将非线性约束转化为无约束问题,利用共轭梯度算法和一维搜索求解最优解,降低计算复杂度。
本文解析了TRPO中的优化过程,涉及目标函数的二次型转换、学习率修正、线性搜索及Hessian-Free技术的应用。通过泰勒展开和拉格朗日乘子法,将非线性约束转化为无约束问题,利用共轭梯度算法和一维搜索求解最优解,降低计算复杂度。
TRPO是OpenAI提出的一种策略单调提升的算法,关于其论文以及解读见我的另一篇论文笔记之TRPO这篇文论文解读将TRPO的重点以及细节都指明了,但是关于目标函数的优化部分由于篇幅原因只是简单说明了以下,具体细节将放在这里进行说明。
参考目录:
①优化理论相关书籍
②TRPO论文
③TRPO论文推导
④TRPO的补充
⑤TRPO讲解
⑥TRPO与NPG的联系或英文原版
TRPO论文优化部分理解
看过TRPO论文的都知道作者采用共轭梯度+线性搜索来迭代求出关于目标函数的最优解
θ
∗
\theta^*
θ∗。
因此接下来我将详细分析作者是如何利用CG和一维搜索来应用于RL算法的。
Note:
- 关于共轭梯度下降和线性搜索的基础知识就不讲解了,这部分内容不清楚的最好去参考优化理论的书籍,做个详细的了解。
首先给出整个优化过程的伪代码,有2个版本,一个是简化版,一个是基于共轭梯度下降的版本:
- 简化版:

- 基于CG版:

为了便于分析,接下来基于CG版本进行讲解。2个红框中标出的是TRPO论文算法比标准CG算法多出来的地方,分别是对学习率
α
k
\alpha_k
αk进行修正且进行一维搜索得到最佳学习率;另一部分是利用Hessian-Free技术去避免求解Hessian矩阵的问题。
面对以上伪代码,应该有四个问题,接下来将一一解答:
- Q 1 Q1 Q1:如何将RL目标函数转成共轭梯度算法需要的二次型问题。
- Q 2 Q2 Q2:为何要修正 α \alpha α?如何去修正呢?
- Q 3 Q3 Q3:如何进行线性搜索呢?
- Q 4 Q4 Q4:如何使用Hessian-Free技术。
首先给出我们要优化的目标,也就是TRPO论文中的公式(14):
m
a
x
i
m
i
z
e
θ
E
s
∼
ρ
θ
o
l
d
,
a
∼
q
[
π
θ
(
a
∣
s
)
q
(
a
∣
s
)
Q
θ
o
l
d
(
s
,
a
)
]
s
.
t
.
E
s
∼
ρ
θ
o
l
d
[
D
K
L
(
π
θ
o
l
d
(
⋅
∣
s
)
∣
∣
π
θ
(
⋅
∣
s
)
)
]
≤
δ
.
\mathop{maximize}\limits_\theta\mathbb{E}_{s\sim\rho_{\theta_{old}},a\sim q}[\frac{\pi_\theta(a|s)}{q(a|s)}Q_{\theta_{old}}(s,a)]\\ s.t.\,\,\,\mathbb{E}_{s\sim\rho_{\theta_{old}}}[D_{KL}(\pi_{\theta_{old}}(\cdot|s)||\pi_\theta(\cdot|s))]\leq\delta.
θmaximizeEs∼ρθold,a∼q[q(a∣s)πθ(a∣s)Qθold(s,a)]s.t.Es∼ρθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ.我们将其简化成:
m
a
x
i
m
i
z
e
θ
f
(
θ
)
s
.
t
.
−
k
l
(
θ
)
≥
−
δ
.
\mathop{maximize}\limits_\theta f(\theta)\\ s.t.\,\,\,-kl(\theta)\ge-\delta.
θmaximizef(θ)s.t.−kl(θ)≥−δ.
二次型转换
Q
1
Q1
Q1:如何将RL目标函数转成共轭梯度算法需要的二次型问题?
共轭梯度下降算法的目标函数是二次型函数,但对于一般非线性函数,我们是通过泰勒定理将其转为近似二次型。在这里我将分两步走来解决这个问题。
泰勒展开
首先我们要做的就是在
θ
o
l
d
\theta_{old}
θold处对
f
(
θ
)
、
k
l
(
θ
)
f(\theta)、kl(\theta)
f(θ)、kl(θ)做泰勒展开。
对于目标函数,省去二阶项以及后面的高阶项:
f
(
θ
)
≈
f
(
θ
o
l
d
)
+
g
T
⋅
(
θ
−
θ
o
l
d
)
f(\theta)\approx f(\theta_{old})+g^T\cdot(\theta-\theta_{old})
f(θ)≈f(θold)+gT⋅(θ−θold)对于约束条件,同样省去常数项、一阶项以及后面的高阶项:
k
l
(
θ
)
≈
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
kl(\theta)\approx\frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})
kl(θ)≈21(θ−θold)TF(θold)(θ−θold)Note:
- g = ( ∂ f ∂ θ ) T ∣ θ = θ o l d g=(\frac{\partial{f}}{\partial{\theta}})^T|_{\theta=\theta_{old}} g=(∂θ∂f)T∣θ=θold。
- 目标函数第一项为常数项,我们将其忽略,故 f ( θ ) ≈ g T ⋅ ( θ − θ o l d ) f(\theta)\approx g^T\cdot(\theta-\theta_{old}) f(θ)≈gT⋅(θ−θold)。约束条件第一项为0,第二项通过展开进行一定数学推算也可以化为0(具体可见这里)。
-
F
F
F为
Hessian矩阵(在这里也可以叫费雪信息矩阵FIM),展开为 ∂ 2 k l ( θ ) ∂ θ 2 ∣ θ = θ o l d \frac{\partial^2{kl(\theta)}}{\partial{\theta^2}}|_{\theta=\theta_{old}} ∂θ2∂2kl(θ)∣θ=θold。黑塞矩阵在二次项函数中是常数矩阵,但是在非线性函数中对于每一次迭代都需要计算一次,计算量和存储量都很大,因此后续我们才要去消除它的计算。 - 可以看到再TRPO里面,我们将目标函数做了一阶近似,对约束条件做了二阶近似。
因此我们的优化目标就变成了:
m
a
x
i
m
i
z
e
θ
g
T
⋅
(
θ
−
θ
o
l
d
)
s
.
t
.
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
≤
δ
\mathop{maximize}\limits_\theta g^T\cdot(\theta-\theta_{old})\\ s.t.\,\,\,\frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})\le\delta
θmaximizegT⋅(θ−θold)s.t.21(θ−θold)TF(θold)(θ−θold)≤δ
无约束的转换
共轭梯度算法是一种无约束优化算法,因此有必要将上述约束型转为无约束,这里我们使用拉格朗日乘子法。
添加拉格朗日乘子
λ
\lambda
λ,则上式转为:
m
a
x
i
m
i
z
e
L
(
θ
,
λ
)
=
g
T
(
θ
−
θ
o
l
d
)
−
λ
2
[
(
θ
−
θ
o
l
d
)
T
F
(
θ
−
θ
o
l
d
)
−
δ
]
K
K
T
条
件
:
{
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
≤
δ
λ
≥
0
λ
(
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
−
δ
)
=
0
maximize\,\,L(\theta,\lambda)=g^T(\theta-\theta_{old})-\frac{\lambda}{2}[(\theta-\theta_{old})^TF(\theta-\theta_{old})-\delta]\\ KKT条件:\begin{cases} \frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})\le\delta\\ \lambda\ge0\\ \lambda(\frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})-\delta)=0 \end{cases}
maximizeL(θ,λ)=gT(θ−θold)−2λ[(θ−θold)TF(θ−θold)−δ]KKT条件:⎩⎪⎨⎪⎧21(θ−θold)TF(θold)(θ−θold)≤δλ≥0λ(21(θ−θold)TF(θold)(θ−θold)−δ)=0这样一来约束问题就转为了无约束问题。但在正式运用之前,还需要将目标函数变个型,令
s
=
θ
−
θ
o
l
d
s=\theta-\theta_{old}
s=θ−θold,则
m
a
x
i
m
i
z
e
L
(
θ
,
λ
)
=
−
λ
2
s
T
F
s
+
g
T
s
+
λ
2
δ
maximize\,\,L(\theta,\lambda)=-\frac{\lambda}{2}s^TFs+g^Ts+\frac{\lambda}{2}\delta
maximizeL(θ,λ)=−2λsTFs+gTs+2λδ这就是转化之后的二次型了!
Note:
- 这个 s s s就是学习率和搜索方向的乘积 s = α ⋅ d s=\alpha\cdot d s=α⋅d,其中 α \alpha α为学习率, d d d为共轭方向,也是共轭梯度算法中的搜索方向。
- TRPO做的这个近似通过拉格朗日乘子法转成的拉格朗日函数 L L L还提供了一个重要信息:由于仍是对函数做优化,所以其一阶导数应该为0,故有 ∂ L ∂ s = 0 \frac{\partial{L}}{\partial{s}}=0 ∂s∂L=0,展开之后就是: s = 1 λ F − 1 g s=\frac{1}{\lambda}F^{-1}g s=λ1F−1g。这个式子的意义在于,TRPO可以通过共轭梯度法,不断迭代求得的 s s s来代替Natural Policy Gradient中计算费雪信息矩阵 F F F的逆矩阵的步骤,因为FIM的计算成本是非常高的,这也是TRPO在NPG上的一个改进(这也就是为什么上述第一个简化版本伪代码中出现了 F − 1 g F^{-1}g F−1g)。换句话说,我们可以利用CG算法来近似 F − 1 g F^{-1}g F−1g,从而减少NPG算法的复杂度。
学习率修正
Q
2
Q2
Q2:为何要修正
α
\alpha
α?如何去修正呢?
为何要修正
α
\alpha
α呢,因为我们在转无约束的时候,多了一个
K
K
T
KKT
KKT条件:
λ
(
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
−
δ
)
=
0
\lambda(\frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})-\delta)=0
λ(21(θ−θold)TF(θold)(θ−θold)−δ)=0,我们接下来对这个式子进行处理:
因为根据共轭梯度算法的流程,有
θ
=
θ
o
l
d
+
α
⋅
d
(
k
)
,
α
∈
R
\theta=\theta_{old}+\alpha\cdot d^{(k)},\alpha\in\mathbb{R}
θ=θold+α⋅d(k),α∈R,所以
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
−
δ
=
1
2
(
α
d
)
T
F
(
α
d
)
−
δ
=
1
2
α
2
(
d
T
F
d
)
−
δ
\frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})-\delta\\ =\frac{1}{2}(\alpha d)^TF(\alpha d)-\delta\\ =\frac{1}{2}\alpha^2(d^TFd)-\delta
21(θ−θold)TF(θold)(θ−θold)−δ=21(αd)TF(αd)−δ=21α2(dTFd)−δ又因为理论上最好的优化区域并不是在置信区域内,而是在置信边界上,在TRPO论文的补充材料中,作者也指出了这一点: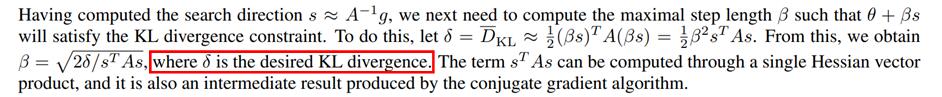
。即
λ
>
0
\lambda>0
λ>0,这样一来
1
2
(
θ
−
θ
o
l
d
)
T
F
(
θ
o
l
d
)
(
θ
−
θ
o
l
d
)
−
δ
≡
0
\frac{1}{2}(\theta-\theta_{old})^TF(\theta_{old})(\theta-\theta_{old})-\delta\equiv0
21(θ−θold)TF(θold)(θ−θold)−δ≡0,故可以得出以下结论:
α
=
2
δ
d
T
F
d
\alpha=\sqrt{\frac{2\delta}{d^TFd}}
α=dTFd2δ这样一来就解决了如何去修正
α
\alpha
α对的问题,也就是说当我们在TRPO算法中使用共轭梯度下降的时候,就不能用标准的
α
\alpha
α公式了,而是要用上式这个经过
K
K
T
KKT
KKT修正过的。
线性搜索
Q
3
Q3
Q3:如何进行线性搜索呢?
根据标准的共轭梯度算法,其会在
n
n
n步迭代就收敛,其
α
\alpha
α其实就是用一维搜索方法进行优化的。但是
Q
2
Q2
Q2中已经将算法进行了改变,故收敛性无法得到保证,那么如何挽回呢?也就是说现在的问题就是如何获得一个更好的学习率
α
∗
\alpha^*
α∗,使得这一步的
α
\alpha
α是一个不错的学习率,这又是一个优化问题:输入是学习率
α
∈
R
\alpha\in\mathbb{R}
α∈R,输出目标函数
L
∈
R
L\in\mathbb{R}
L∈R,
R
→
R
\mathbb{R}\to\mathbb{R}
R→R的问题我们采用线性搜索(即一维搜索)来做,比如常见的黄金分割、斐波那契、二分法、牛顿法、割线法等等。作者在这里简单的采用了指数式下降来搜寻最佳的学习率
α
\alpha
α,类似于Armijo划界法,也就是说从一开始最大的学习率
α
(
0
)
\alpha^{(0)}
α(0)开始,接下来每一个学习率都在上一个备选值的基础上乘以缩减因子
τ
=
0.5
\tau=0.5
τ=0.5,这样就构成
a
k
=
τ
m
a
(
0
)
a_k=\tau^ma^{(0)}
ak=τma(0),相当于构成了一个序列,我们要在这个序列中找出使得目标函数提升的最大学习率
a
∗
a^*
a∗。
Hessian-Free
Q
4
Q4
Q4:如何使用Hessian-Free技术。
我们在伪代码中看出我们需要计算一个Hessian矩阵,黑塞矩阵在二次项函数中是常数矩阵,但是在非线性函数中对于每一次迭代都需要计算一次,计算量和存储量都很大,因此我们必须要消除它。理论上的消除办法有3种,这里我介绍一种,即论文中作者采用的Hestenes-Stiefel公式,它用来消除
F
F
F的原理是什么呢?
我们发现共轭梯度的算法流程中,Hessian矩阵总以matrix-vector products的形式出现。因此我们可以直接带走他们。
具体来说:
对于二次型:
f
=
1
2
θ
T
F
θ
−
b
T
θ
f=\frac{1}{2}\theta^TF\theta-b^T\theta
f=21θTFθ−bTθ来说:
已知
θ
k
+
1
=
θ
k
+
α
k
d
k
\theta^{k+1}=\theta^{k}+\alpha_kd^{k}
θk+1=θk+αkdk,等式两侧同时左乘Hessian矩阵
F
F
F并减去常数向量
b
b
b:
F
⋅
θ
k
+
1
−
b
=
F
⋅
θ
k
+
α
k
F
d
k
−
b
F\cdot\theta^{k+1}-b=F\cdot\theta^{k}+\alpha_kFd^{k}-b
F⋅θk+1−b=F⋅θk+αkFdk−b,又因为
g
k
=
∂
f
∂
θ
k
=
F
⋅
θ
k
−
b
g^k=\frac{\partial{f}}{\partial{\theta^k}}=F\cdot\theta^k-b
gk=∂θk∂f=F⋅θk−b,带入之后:
g
k
+
1
=
g
k
+
α
k
F
d
k
g^{k+1}=g^k+\alpha_kFd^k
gk+1=gk+αkFdk,所以可得以下结论:
F
d
k
=
g
k
+
1
−
g
k
α
k
Fd^k=\frac{g^{k+1}-g^k}{\alpha_k}
Fdk=αkgk+1−gk从这个式子可以看出,有关要计算
F
d
k
Fd^k
Fdk的地方我们以后都只需要计算2个梯度值就行了,而这两个梯度值在共轭梯度算法里本来就需要算的,因此并没有增加额外的算法负担。
所以
β
\beta
β就变成了:
β
k
=
(
g
k
+
1
)
T
⋅
[
g
k
+
1
−
g
k
]
(
d
k
)
T
[
g
k
+
1
−
g
k
]
\beta_k=\frac{(g^{k+1})^T\cdot[g^{k+1}-g^k]}{(d^k)^T[g^{k+1}-g^k]}
βk=(dk)T[gk+1−gk](gk+1)T⋅[gk+1−gk]
总结
- 接下来只要按照伪代码的流程,不断迭代,就可以优化出参数 θ ∗ \theta^* θ∗,共轭梯度算法最著名的地方就在于他可以一边迭代,一边利用当前点梯度和上一个搜索方向的线性结合创造出和之前搜索方向均共轭的下一个搜索方向 d k + 1 d^{k+1} dk+1出来。
- 总的来说,TRPO的优化采用修正的共轭梯度算法+一维搜索算法。我们通过泰勒定理以及拉格朗日乘子法将非线性的约束目标转为了近似二次型函数的无约束目标,并利用 K K T KKT KKT条件对学习率 α \alpha α进行修正。
- 可以看出虽然我们消除了Hessian矩阵的计算,但是共轭梯度算法还是有一定复杂度的,这也是TRPO算法不如PPO实用的一个原因,而PPO采用的是随机梯度优化算法,每一次迭代都基于采样的mini-batch个样本。

















 3533
3533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









