










引言
你是否曾因网页版大模型卡顿而烦恼?是否因本地部署对硬件的高要求而望而却步?现在,这些问题将迎刃而解!本文将为你揭秘如何通过硅基流动平台和Cherry Studio软件,1分钟快速部署DeepSeek大模型,轻松实现高效、低成本的AI开发!无论你是AI新手还是资深开发者,这篇教程都将成为你的得力助手。
一、为什么选择硅基流动+Cherry Studio?
-
极速部署:通过云端API,1分钟完成模型加载,无需复杂配置。
-
无需高配硬件:云端服务解决本地部署的高成本问题。
-
流畅体验:API调用确保运行稳定,告别网页版卡顿。
-
免费试用:硅基流动提供免费资源,降低学习和开发门槛。
二、1分钟极速部署DeepSeek大模型
2.1 访问硅基流动
打开硅基流动官方网站:硅基流动
2.2 注册账号
-
填写手机号码,获取验证码,点击“注册”按钮就能完成注册
2.3 创建API密钥
-
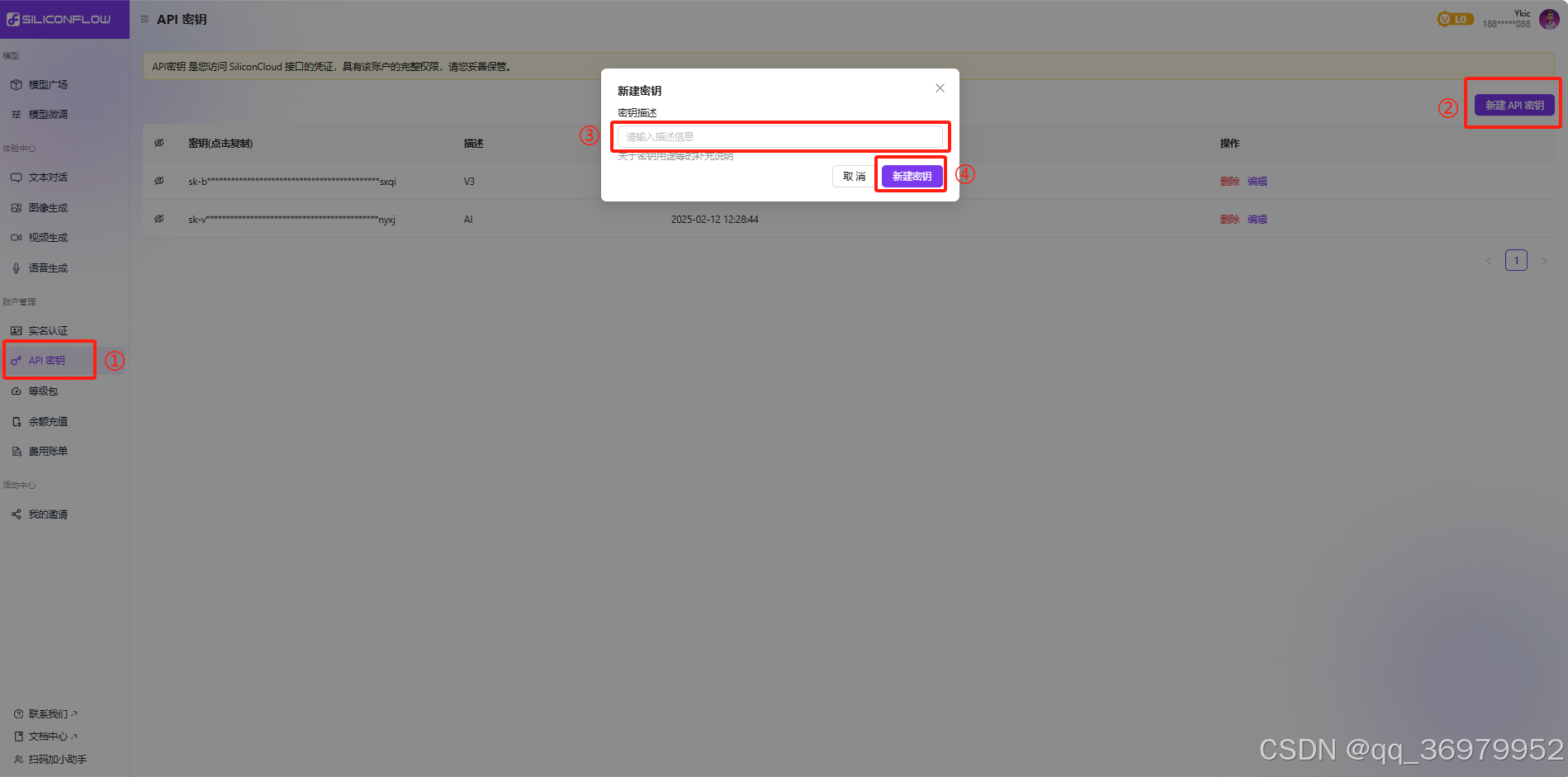
登录后进入账户管理的“API秘钥”页面
-
点击“新建API密钥”,秘钥描述可随意输入,点击新建秘钥即能完成秘钥创建。
三、Cherry Studio极速配置与使用
3.1 下载与安装Cherry Studio - 全能的AI助手
访问Cherry Studio官方网站:Cherry Studio,下载并安装适合你系统的版本。 一直点下一步即能完成软件的安装。
3.2 配置硅基流动API秘钥
-
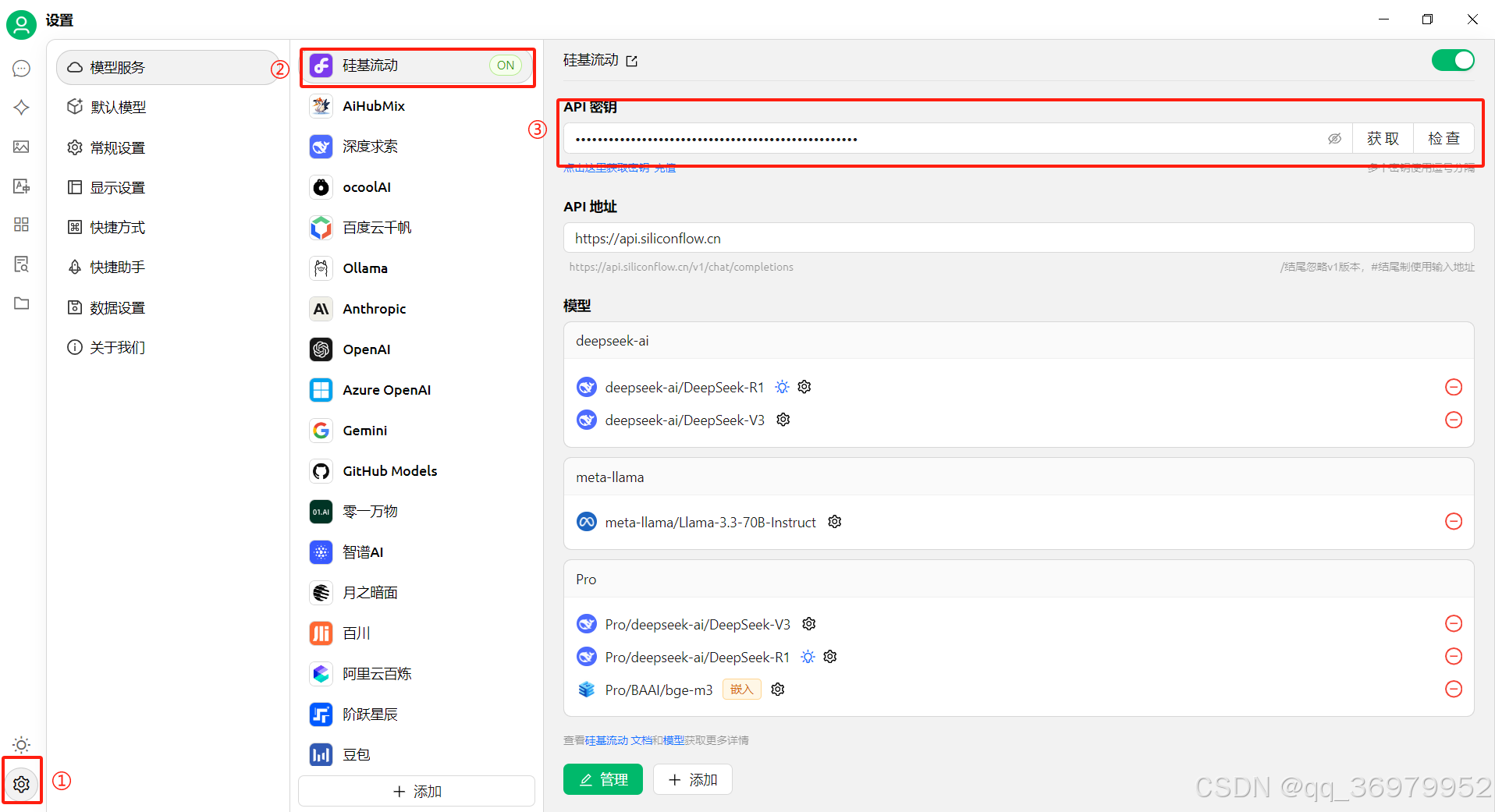
打开硅基流动网页,进入“API秘钥”页面,点击刚才创建的秘钥完成秘钥复制。

-
打开Cherry Studio,进入“设置①”-“硅基流动②”-“把上一步复制的秘钥粘贴至③处”。
3.3 加载DeepSeek模型(以deepseek-ai/DeepSeek-V3为例)
-
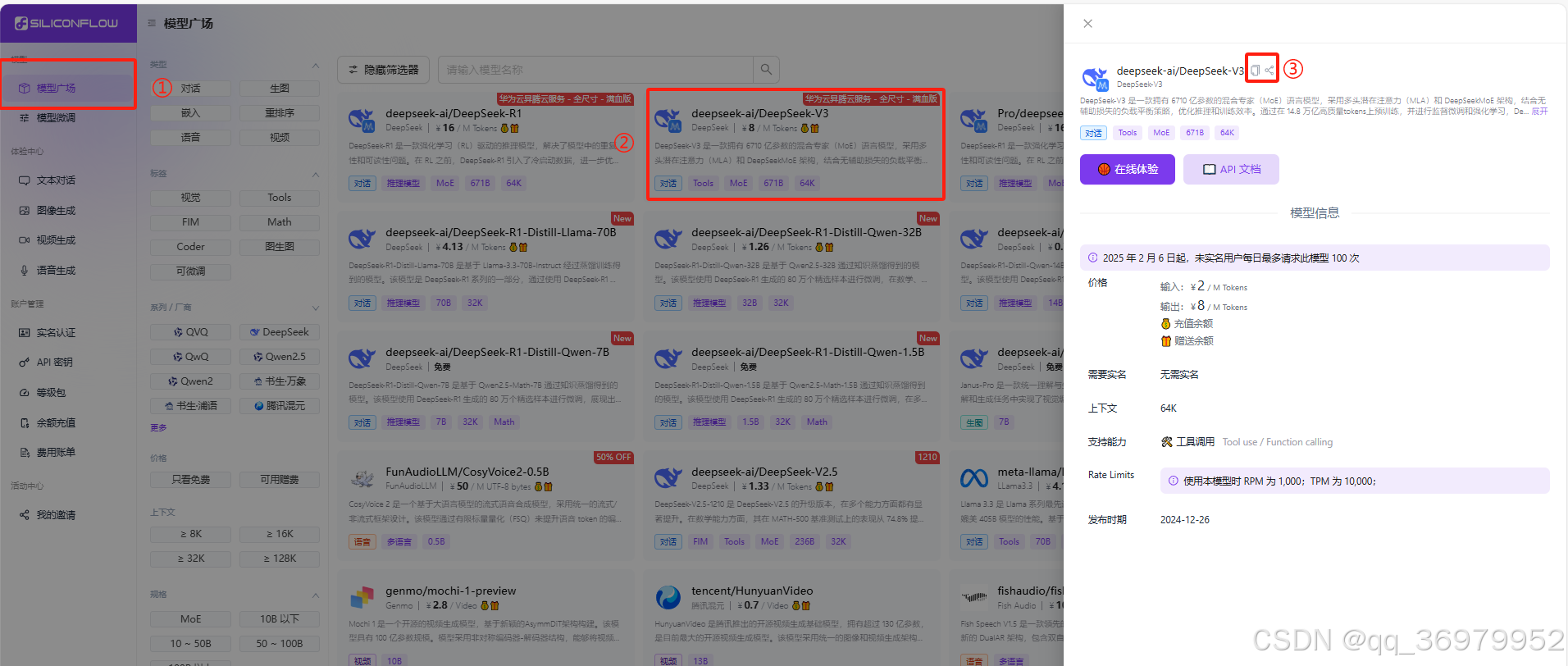
打开硅基流动网页,选择“模型广场”,找到并点击deepseek-ai/DeepSeek-V3模型,在弹框点击模型名字左侧完成模型名字的复制。
-
在Cherry Studio中,进入*设置①”-“硅基流动②”-“点击添加③"-“把上一步赋值的名字粘贴至④处“-”点击添加模型⑤“。
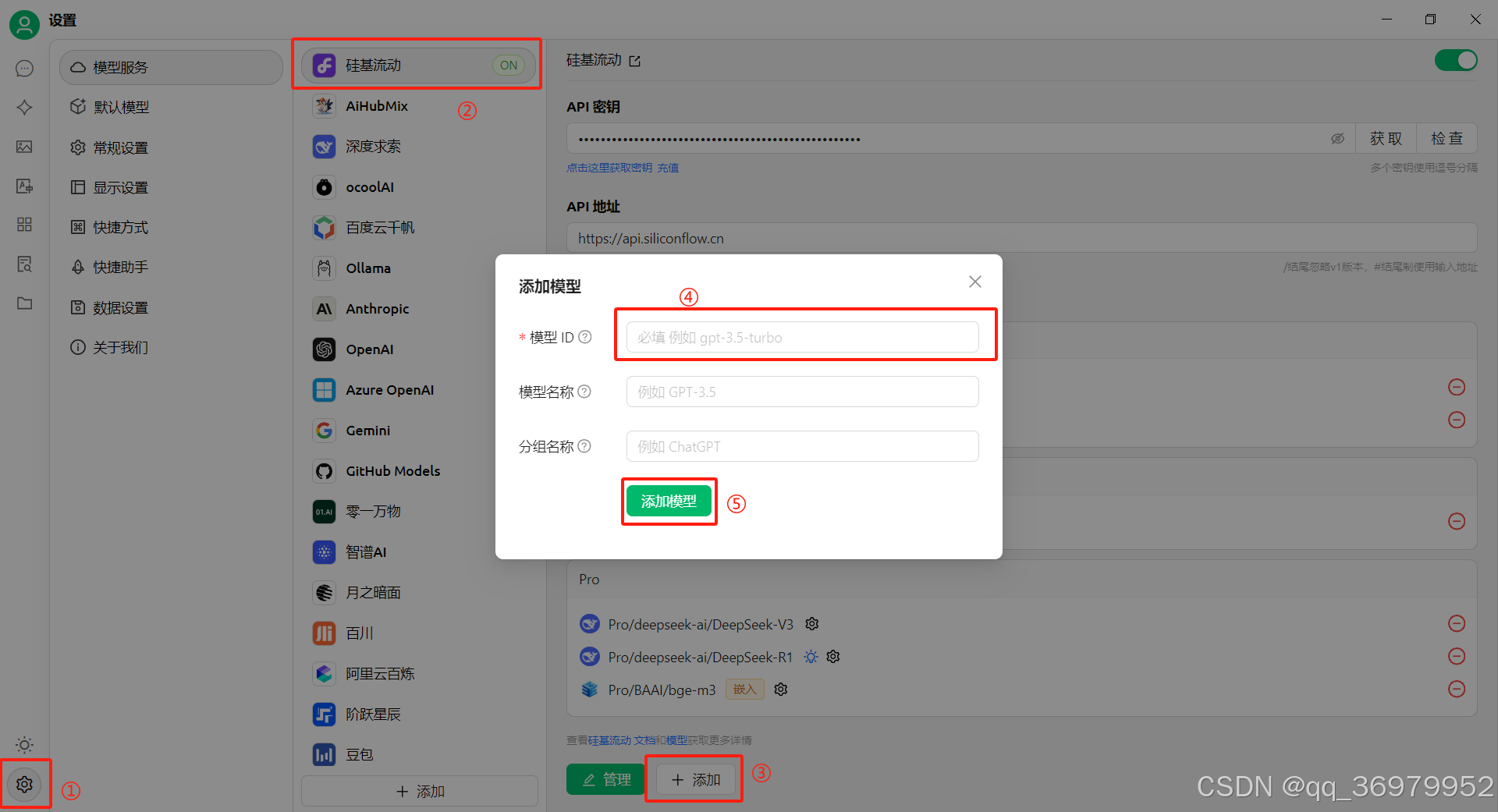
-
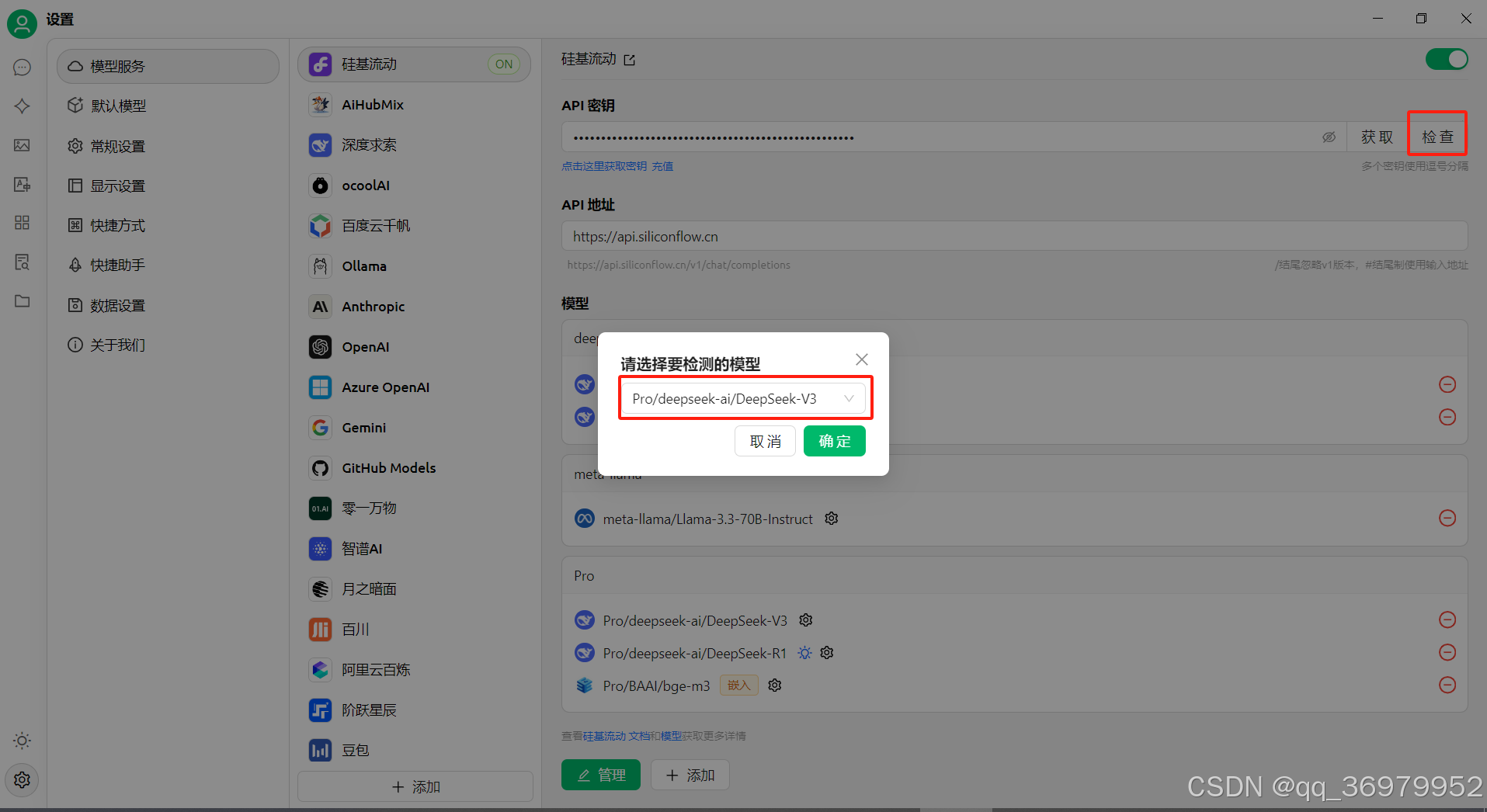
点击”检查“,在弹窗下拉选择“deepseek-ai/DeepSeek-V3”,点击“确定”,当出现连接成功字样时,代表已完成模型加载。
3.4 运行与测试
-
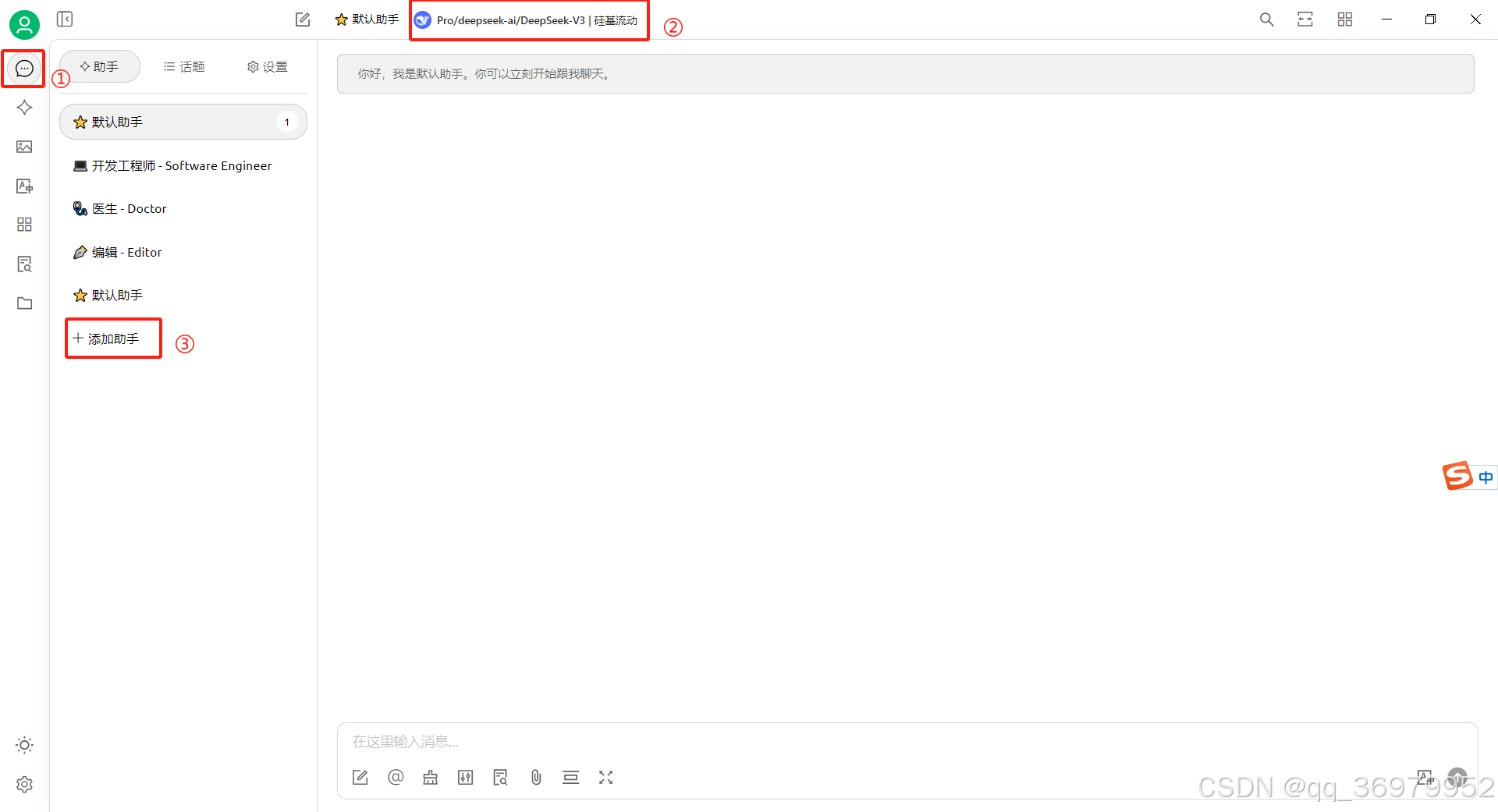
打开Cherry Studio软件,点击“①对话”,点击“②模型名字”,可选择刚才加载的模型,点击“③添加助手”可根据自己的需求完成对应的功能添加。
-
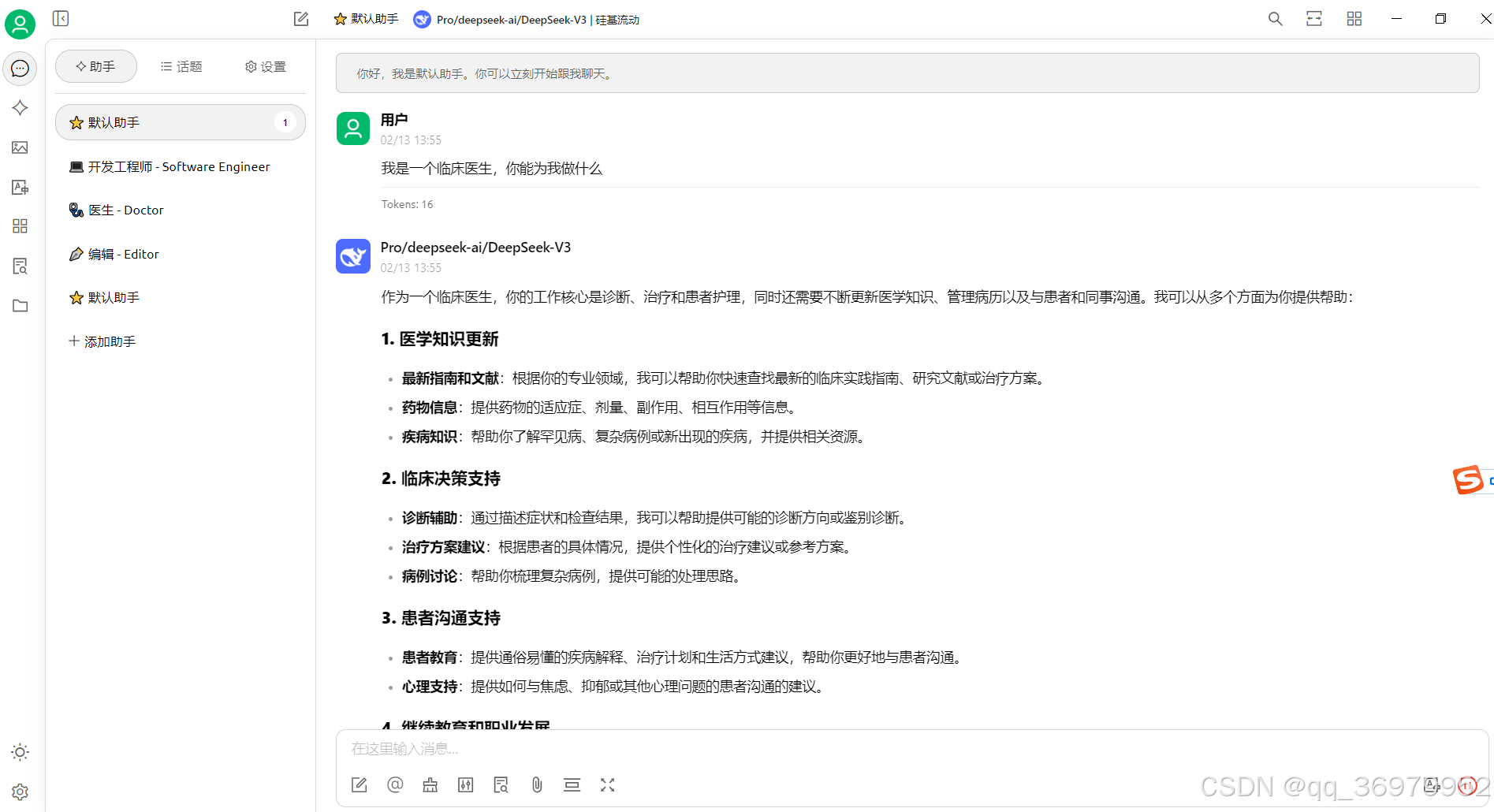
完成上述步骤之后既可以跟deepseek进行对话了。
此方法也同样适合使用其他模型,如果对使用要求不那么高,可以选择一下免费的模型来使用
四、进阶技巧
-
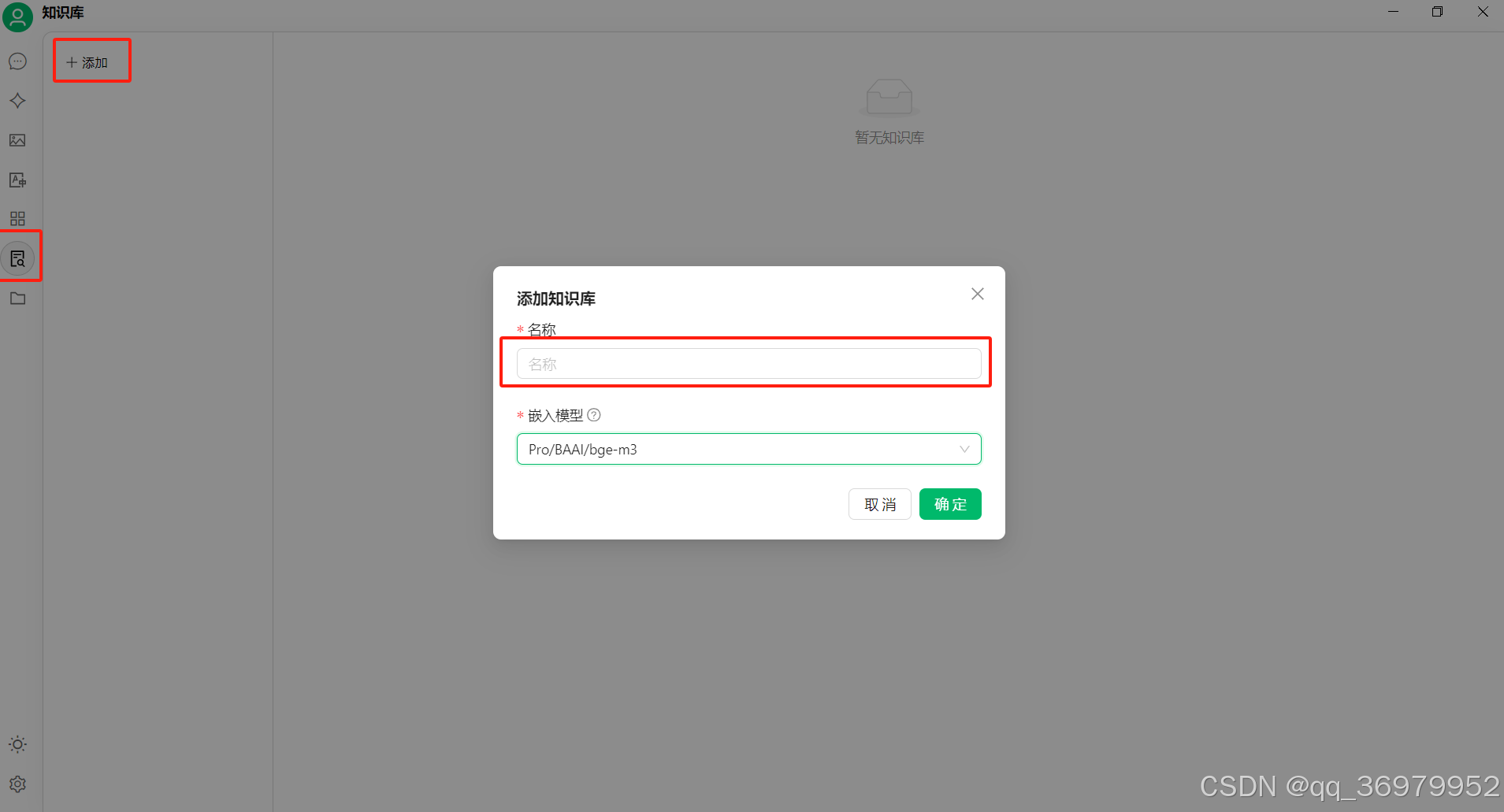
知识库创建:结合下图三个红框,可完成自己知识库的创建,知识库名称根据自我习惯进行自定义,选择嵌入模型之后,点击“确定”按钮即可完成姿势库的新建。
-
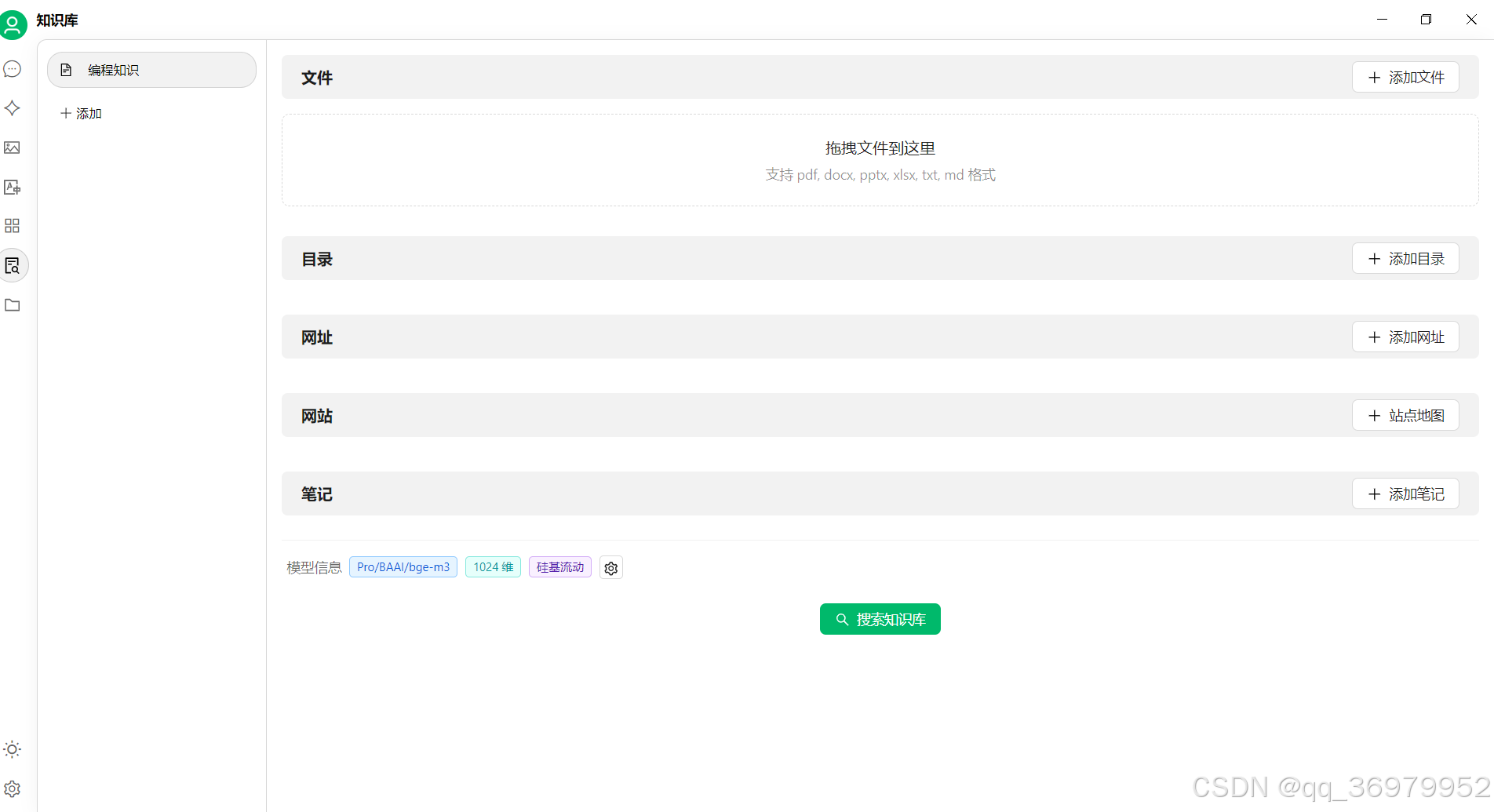
知识库扩展:通过不断往创建的知识库中输入跟库相关的知识,支持上传文件、添加本地目录、添加多个网址、网站、笔记第二个方式,使AI工具在自己所处的行业显得更加专业。
-
模型微调:通过硅基流动的微调工具,定制化训练DeepSeek
-
成本控制:按需使用硅基流动资源,仅为实际消耗付费。
五、总结
通过硅基流动和Cherry Studio,你可以在1分钟内高效部署DeepSeek大模型,无需高配硬件,畅享流畅体验。无论你是初学者还是专业开发者,这种组合都将为你的AI开发带来极大便利。


















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









