









2 Related work
Balle 使用GDN(generalized divisive normalization)
content-weighted image compression system 在rate loss quantization continuous relaxation不同。在importance map上面定义rate loss,使用一个简单的二值化器来量化。
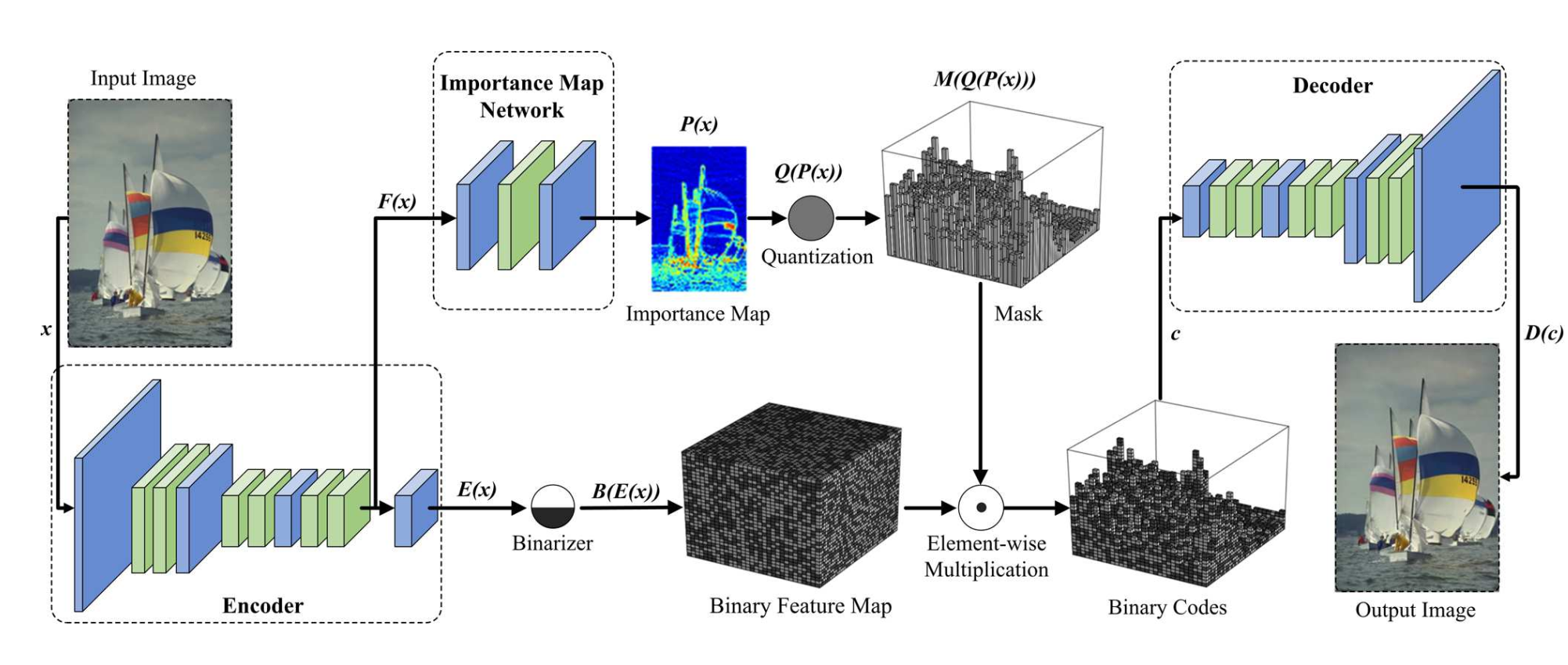
3 Content-weighted Image Compression
3.1.1 encoder 和decoder
Encoder 和decoder都是全连接层,可以后向训练。
encoder由三个卷积层和3个残差块组成。每个残差块有2个卷积层,使用时移除原始的残差块的BN。输入图像 x x x由128个 8 × 8 8 \times 8 8×8步长为4的过滤器卷积,随后用1个残差块。然后特征图用256个 4 × 4 4 \times 4 4×4步长为2的过滤器卷积,接着2个残差块,从而生成中间的特征图 f ( x ) f(x) f(x)。最后特征图 f ( x ) f(x) f(x)用 m m m个 1 × 1 1 \times 1 1×1的过滤器产生encoder结果 E ( x ) E(x) E(x)。少于0.5bpp的模型设置 n = 64 n=64 n=64,否则设为 n = 128 n=128 n=128。
decoder D ( c ) D(c) D(c)的网络结构和encoder对称, c c c是图像的code。
Encoder
decoder
Binarizer
e i j k 是 e e_{ijk}是e eijk是e的元素
由于导数基本为0,不利于back-propagation,受到binarized neural networks(BNN)的影响,因此修改为
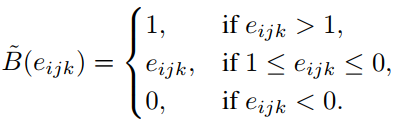
得到的偏导是
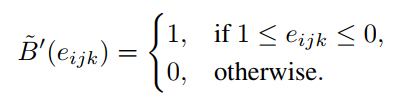
Importance map
在Balle提出的网络中,量化之后的码字长度是空间不变的,压缩是通过熵编码实现的。然而作者认为,一幅图像中不同部分分配的比特数应该是不一样多的,因此作者提出了importance map用于比特分配以及压缩率控制。
将encoder的最后一个残差块的特征图作为importance map的输入,使用3层卷积网络产生了importance map p = P ( x ) p=P(x) p=P(x)。
对于importance map的每个元素 p i j p_{ij} pij计算importance mask m。首先计算量化值,每个 p i j p_{ij} pij都转为不超过 n n n的整数值( n n n是特征图的数量):
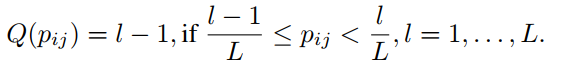
L是重要程度, n m o d L = 0 n \; mod \;L = 0 nmodL=0。Each important level is corresponding to n L \frac{n}{L} Lnbits.
重要性图不仅可以被视为熵率估计的替代方案,而且还可以自然地考虑上下文。
importance mask m:
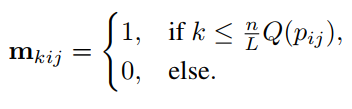
假设每一个feature map的每一个(i,j)位置分配1bit,那么原本共需要 n × h × w n \times h \times w n×h×w,现在只需要 N L ∑ i , j Q ( p i j ) \frac{N}{L}\sum_{i,j}Q(p_{ij}) LN∑i,jQ(pij)bits。
两个式子可以合并写成
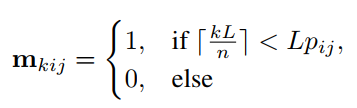
对应的偏导:

最终的编码结果是 c = M ( p ) ∘ B ( e ) c = M(p) \circ B(e) c=M(p)∘B(e)。
也就是将importance mask m和二值量化结果点乘。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ruVhtWAR-1647441363283)(C:\Users\s50018299\AppData\Roaming\Typora\typora-user-images\image-20210826105239854.png)]](https://img-blog.csdnimg.cn/e4684cf34fe04d30b8163c720a2ffd5d.png)
具有锐边或丰富纹理的区域通常具有较高的值,并应分配更多的位来编码。
Model formulation
模型的目标函数是
L = ∑ x ∈ χ L D ( c , x ) + γ L R ( x ) \mathcal{L}=\sum_{x \in \chi}{\mathcal{L}_D(c,x) + \gamma\mathcal{L}_R(x)} L=x∈χ∑LD(c,x)+γLR(x)
L D ( c , x ) \mathcal{L}_D(c,x) LD(c,x)代表失真loss, L R ( x ) \mathcal{L}_R(x) LR(x)表示码率loss。
失真loss
衡量原始图像和解码结果的差异: L D ( c , x ) = ∣ ∣ D ( c ) − x ∣ ∣ 2 2 \mathcal{L}_D(c,x)=||D(c)-x||^2_2 LD(c,x)=∣∣D(c)−x∣∣22
码率loss
码率loss直接定义为码长度的连续估计。假定encoder的结果 E ( x ) E(x) E(x)的是 n × h × w n\times h \times w n×h×w。码分成两部分:1)quantized importance map Q ( p ) Q(p) Q(p),为 h × w h \times w h×w;2)修剪的二值码流 N L ∑ i , j Q ( p i j ) \frac{N}{L}\sum_{i,j}Q(p_{ij}) LN∑i,jQ(pij)。第一部分对encoder和importance map network而言是常量,因此 N L ∑ i , j Q ( p i j ) \frac{N}{L}\sum_{i,j}Q(p_{ij}) LN∑i,jQ(pij)可以直接被用来作为码率loss。由于Q(p_ij) 不可导,relax Q(p_ij)如下
L R 0 ( c , x ) = ∑ i , j ( P ( x ) ) i j \mathcal{L}_R^0(c,x)=\sum_{i,j}(P(x))_{ij} LR0(c,x)=∑i,j(P(x))ij
使用阈值r修改码率loss如下
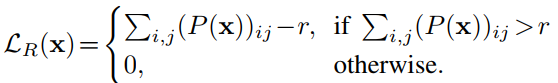
Convolutional entropy encoder
CABAC
使用CABAC进行二值算术编码。文章在这个框架下面进行修改。
Context modeling
c k i j c_{kij} ckij的context记为 C N T X ( c k i j ) CNTX(c_{kij}) CNTX(ckij), C N T X ( c k i j ) CNTX(c_{kij}) CNTX(ckij)是一个 5 × 5 × 4 5\times 5\times 4 5×5×4的长方体。 C N T X ( c k i j ) CNTX(c_{kij}) CNTX(ckij)分为有用和无用的2组。有用的表示可以用来预测 c k i j c_{kij} ckij。无用的包含:1)待预测bit c k i j c_{kij} ckij,2)importance map值为0,3)范围外,4)未能被编码。 C N T X ( c k i j ) CNTX(c_{kij}) CNTX(ckij)的编码方式:1)无用的编为0,2)值为0的无用的bits编为1,3)值为1的编为2
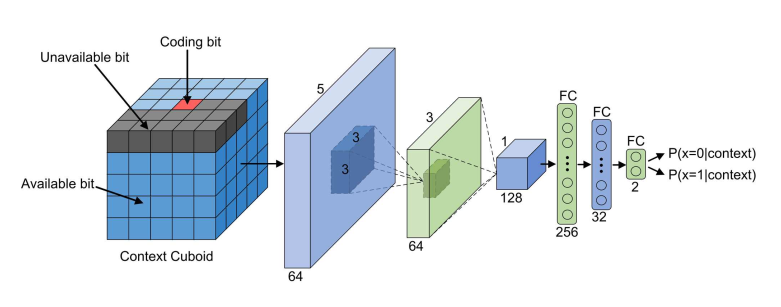
红色块表示要预测的位;深色块表示不可用位;蓝色块表示可用位。
概率预测
常用方法是建立维持一个频率表。由于长方体过大,因此改为CNN模型。
E ( C N T X ( c k i j ) ) E(CNTX(c_{kij})) E(CNTX(ckij))将长方体作为输入,输出是 c k i j c_{kij} ckij为1的概率。
损失函数可以写作:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cHpfGg3X-1647441363286)(C:\Users\s50018299\AppData\Roaming\Typora\typora-user-images\image-20210823153556690.png)]](https://img-blog.csdnimg.cn/1c33488d88cc488d84e9efc8c91a6cc0.png)
encoder用ADAM训练。
实验
数据:ImageNet的一个有大约10000张高质量的子集。将图片裁剪成 128 × 128 128 \times 128 128×128的片,用这些片来训练网络。训练好后运用在Kodak PhotoCD图像数据集上。
对比JPEG,JPEG 2000,Balle的CNN模型,使用MSE、PSNR、SSIM评价。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WnAZPsRs-1647441363287)(C:\Users\s50018299\AppData\Roaming\Typora\typora-user-images\image-20210823161544790.png)]](https://img-blog.csdnimg.cn/ec8ea5778923437cbef9aa0e3ddb297c.png)
率失真曲线如图。在MSE中,JPEG表现最差。PSNR,论文方法和JPEG 2000、Balle相近。SSIM,论文方法最优。
视觉评价





对比四种方法在低压缩率的情况。Balle通过模糊边缘和小范围的纹理产生结果。
列2、3存在不少的模糊、铃效应、块效应等。
我们可以观察到第1、2、3和5行的模糊伪影,第4和5行的颜色失真,第4和5行的振铃伪影。
应将更多的位分配给具有强边缘或详细纹理的区域,而将更少的位分配给光滑区域
importance map不使用手工工程,而是端到端学习,以最大限度地减少速率失真损失
importance map实验分析
baseline model:不包含entropy和基于 importance map的rate loss。

代码
https://github.com/limuhit/ImageCompression这是一个测试代码,对caffe框架进行了一个修改,我理解完整的功能应该是需要再修改的。















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









