









abstract
主要讲了云原生数据库为什么存在,为什么传统数据库不能适应云场景下的需求,首先云计算有个非常关键的功能就是弹性,按需使用,云原生数据库就是匹配这个需求,并且云原生数据库带动了software-hardware co-design,因为有这个方面的需求带动了RDMA,NVM,kernel bypass等技术的发展,对于一些需求比如高并发,云原生数据库可以做到水平扩展,此时又介绍了一下阿里巴巴的云原生数据库产品polardb,和polardb-x,前者是一个应对workload为oltp的云原生数据后,后者是前者的分布式版本,然后又介绍了阿里巴巴的SDDP一个自驱动的数据库智能配置平台,其目标是代替或者减轻DBA的工作,做到智能化,为什么需要按需使用,李飞飞老师例举双十一零点零分云原生数据库TPS暴涨然后随着时间的推移慢慢下降,此时我们按需使用的需求就来了,在双十一零点零分分配非常多的资源,然后随着时间的推移TPS的减少,资源也慢慢的减少,而上述提到的数据库产品也顺利的经过了双十一的考验
introduction
这里更加详细的介绍了阿里巴阿布云原生数据库的细节,比如OLTP数据库 Polardb每一个节点可以存100TB,每一个可以承受1 milion QPS,然后讲了一些传统数据库mysql,postgresql不能做到横向扩展,所以在云原生的场景下不再适合
ARCHITECTURES FOR DATABASE SYSTEMS AT ALIBABA
这里主要介绍了3种数据库主流的架构
single node
就是一个单一的数据库其用本地磁盘存储,缺点是不能扩展,当并发量上去只能干瞪眼,数据库的每一个进程(线程)共享主存,共享磁盘
多个DB同时使用一个共享存储
这里的共享存储可以是多个节点组成的共享存储,也可以是专业的存储机
这个架构我们也非常熟悉,就是多个DB组成集群,然后集群中所有的机器使用一个额外的共享存储存数据,有个问题这种架构是读写分离,多个一般只有一个DB做写服务(INSERT, UPDATE,DELETE),其他的DB做读服务(read-only),为什么要这样设计因为我们要保证写的一致性,但是我们可以用一些multi-master的共识协议,做到写多个node
这个架构看似完美无缺,但是在生产环境中还是会遇到非常多的问题,在计算(DB)和存储节点之间数据低延迟传输就变得非常不可靠,因为我们的数据要经过交换机,经过数据中心,甚至数据会跨区域传输这样会使延迟变得非常非常的大,特别是我们在用一些硬件加速技术比如RDMA
还有一个非常严重的问题是我们的read-only节点增长到一定的数量用户的数据查询请求就会变慢或者阻塞(总体带宽问题?共享存储接收问题?),此时我们访问远端的存储的行为会变得非常昂贵
share nothing

这种架构对于我来说就非常的陌生
也许我们听说过CDN,根据用户地域的不同使用户去访问离自己最近的节点,这个shared nothing有些类似
一个逻辑数据库(多个数据库组成逻辑数据库)被分成多个share(个人觉得是每一个访问为一个shared),每一个share会被分配到一个或者多个node中(可以根据用户的地域分配近的share),底层的共享存储存储的这个share数据只能被这个share分配的node所访问,比较出名的是google的spanner,其用atomic clock和GPS实现数据replica的一致性,还有多区域的transaction的一致性,阿里巴巴用的polardb-x实现share-nothing
OTHER KEY FEATURES OF ALIBABA DATABASE SYSTEMS
Multi-Model Analysis
说实话没看懂贴一下原文
An important application scenario at Alibaba is to support multi-model analysis, which consists of two aspects:southbound and northbound multi-model access. The southbound multi-model access indicates that the underlying storage supports different data formats and data sources. The stored data can be either structured or non-structured, e.g., graph, vector and document storage. The database then provides a unified query interface, such as a SQL or SQLlike interface, to query and access various types of data sources and formats, forming a data lake service. The northbound multi-model access indicates that a single data model and format (e.g., key-value model in most cases) is used to store all structured, semi-structured and unstructured data in a single database. On top of this single storage model, the database then supports multiple query interfaces, such
as SQL, SPARQL and GQL depending on the application needs. Microsoft CosmosDB [9] is a representative system of this kind.
In addition to addressing our internal business operation needs, being able to support multi-model analysis is also an essential requirement for cloud database services. Many cloud applications require to collect large-volumes of data from heterogeneous sources, and conduct federated analysis
to link different sources and reveal business insights (i.e., south-bound multi-model access). On the other hand, a cloud database (e.g., a large KV store such as HBase) is often a central data repository accessed by multiple applications with various application needs. They may prefer to use different query interfaces due to usability and efficiency, where northbound multi-model analysis is needed.
Autonomy and Intelligence
这里主要讲了阿里云的数据库智能管理平台
为什么需要这个东西?
因为阿里云的workload非常复杂,不再是简单的olap,oltp,或者混合型还有非常多,非常多其他的workload,因此为了应对这些workload,阿里云搞了非常多不同类型的数据库,这么多的数据库要DBA去运维配置几乎不可能,所以阿里云搞了一个叫做SDDP(self-driving database platform)的东西,做到自我探测,自我决策,自我恢复,自我优化
但是这里也有一些问题,因为机器学习的训练代价和推测导致做到有效,高效就非常的困难
换句话说自我探测,自我决策,自我恢复都是为了达到上述的有效且高效的手段之一,但是在实现这3个东西的时候怎么自动的检测实例的状态?怎么探测实例不正常的行为?如果不正常的行为发生我们怎么快速的反应也就是快速的自动做出决策?
Software-Hardware Co-Design
在阿里云数据库系统中还有一大创新就是软硬件结合设计,阿里云数据库的一大创新就是在使用有限的系统,硬件,资源的情况下安全高效的运行,因为数据库需要在查询的时候最大限度的使用现有的资源,假如我们简单的讲现有的数据库设计放到新的硬件上,这样是非常失策的,因为硬件的发展不是随着你数据库发展而发展,意思是要改数据库,设计新的算法将他适应在新的硬件上,比如mysql跑在共享存储中,这个共享存储用了现今非常流行的RDMA去减少数据传输的延迟,比mysql直接跑在local disk(ssd)上要慢得多…,阿里巴巴的数据库就对这些新的硬件做了设计,比如RDMA,NVM,GPU/FPGA,NVMe SSD等等
High Availability
这个是老生常谈的话题,阿里巴巴的数据库也是做到了这一点,为什么要高可用?因为没有几个客户可以忍耐自己的业务中断,怎么实现高可用,常用方法,就是主备,三路replica(数据分三分放入三个存储中,一个存储挂了立马切换到另一个存储中),当然有一些特别的客户比如银行,金融客户需要4分或者更多的备份,而且备份还要满足2地三中心,不能把所有备份放入一个数据中心,假如备份都在一个数据中心,且这个数据中心光纤被挖断,那么所有备份都不能用了,然后对于多备份的机器要保证数据一致性,阿里云这里用的是一种并行的paxos 叫做x-paxos,且又介绍了一下CAP理论,分别是consistency,Availability,partition tolerance,因为三个最多只能满足2个,所以阿里数据库满足了C和P。
ALIBABA CLOUD-NATIVE DATABASES
首先看一下阿里云原生数据库的架构,这里主要介绍polardb(OLTP),polardb-x(distribution版本的polardb),AnalyticDB(实时交互的OLAP数据库),SDDP

POLARDB: cloud-native OLTP database
首先PolarDB是基于alisql魔改的,alisql是魔改mysql+innodb的,且PolarDB提供高弹性高并发,high volume,并且PolarDB完全兼容mysql和postgresql,就是为了客户可以将其业务顺利迁移到PolarDB上
PolarDB是一个shared-strorage架构如下,其分为三层分别为
- PolarProxy
- multi-node database cluster
- distributed shared file system PolarFS
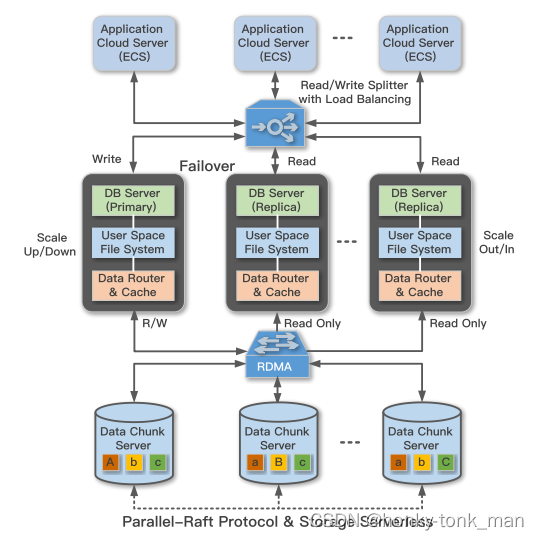
接下来讲了一下PolarDB的架构,如上图所示,PolarDB有点像mysql和postgresql的架构,做到计算节点和存储节点分离,计算节点就是上面多个database,其分为一个主节点,N和从节点,主节点接收读和写的业务,从节点只接受读的业务(保证数据写到存储中的一致性),存储都是由阿里云自己设计的PolarFS搞得一个分布式存储,我们之前讲到这个架构做到了存储和计算的分离,这样有啥好处?第一个增加了容错率,第二个不用关心内存和磁盘容量的比例(我也不知道为啥要关心这个和bufferpool的使用效率有关?),第三点因为使用了计算和存储分离,我们不再关心计算节点的数据持久性问题这样非常方便数据的迁移,PolarDB可以提供100TB的存储和1百万的QPS(每个节点)
接下来介绍PolarFS
我们常用的分布式文件系统如HDFS,Ceph,开源好用,但是延迟极高(对比本地磁盘如SSD),我们的mysql如果直接运行在本地的SSD上比运行在这些开源分布式文件系统上效率会高得多
PolarFS怎么做到低延迟呢?PolarFS依托于PolarStore,这个是一个分布式存储网络,这个分布式存储网络使用RDMA降低延迟,减少kernel space和user space的切换,当数据到存储设备的网卡上的时候传统方式是触发硬中断,由CPU注册软中断,然后再由内核把数据搬到kernel space中,再放到对应的user space中,但是有了RDMA,当数据到达网卡的时候直接由RDMA通过RDMA芯片把数据从网卡直接存入对应进程的用户空间,这样节省了一大部分时间,PolarFS运行在这之上,并且PolarFS考虑了移植性,把PolarFS的接口设计成POSIX风格
既然是分布式文件系统,那么某个节点down了是常有的事情,当节点起来要最快的速度接收新的数据或者和其他的节点做一致性检查,所以最开始PolarFS用了raft算法,但是在使用完raft之后发现效率极其低下(特别是在RDMA等技术的情况下延迟还在10毫秒),然后为此开发了ParallelRaft,其支持无序的日志,commit和applying(原生raft只支持日志序列一样,不然就通不过appendlogRPC伴随的一致性检查)
POLARDB-X: distributed OLTP database
首先使用PolarDB扩展到10个节点就不行了(因为底层RDMA网络的原因),所以不能大量事务导致的承受高并发,这都是在双十一发现的,但是PolarDB-X支持横向扩展,PolarDB-X的架构不是典型的share-nothing,而是share-nothing加上share-storage,传统的share-nothing架构是一个节点处理所有的shared,而PolarDB-X通过横向扩展使其支持更多的shared和事务
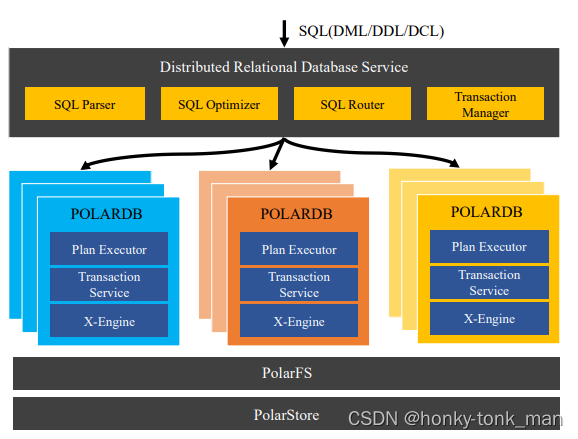
上述是PolarDB-X架构其中最上面的distributed relational database service用来接收用户的sql语句和事务,然后进行sql语句的解析,优化,最后路由到特定的polardb中,这里的PolarDB也和上面讲的一样一个node作为主节点写,其他的从节点只读,每个从节点只是主节点的replica,我们再看到每个PolarDB的内部,分为三个东西分别是plan excutor ,transaction service主要处理事务,最重要的x-engine是阿里巴巴基于LSM树搞得OLTP存储引擎
在处理大量的事务的时候发现了3个问题分别是
-
tsunami problem
随着重大促销活动的启动(例如阿里巴巴双十一全球购物节出现122次高峰),交易量急剧增加,这给底层数据库带来了巨大压力
-
the flood discharge problem
当buffer不能快速刷新的时候hot record(就是内存中的脏page,还没有被写入磁盘)压倒性的把操作系统的buffer撑爆,导致连续的事务被阻塞
-
the fast moving current problem
就是一些大量数据的移动在短时间内高频次发生,比如冷备,热备,温备集中发生
X-engine就是为了处理上述3个问题而创造的
对于一个事务来说怎么提升其效率,这个问题可以归结为怎么高效的将从磁盘中检索数据,持久化数据
X-engine使用TLP(thread-level-parallelism)的方式多核的去请求内存,他将事务的写操作异步化,分解一个长写操作成多个stage,然后放入pipeline,就是为了提升总的吞吐量
这里的异步应该指的是异步IO,就是用户空间下发IO指令后就不管了,去处理别的事情,直到内核处理完,并且将IO移动到用户空间后再通过信号提醒用户空间进程,任务完成,具体看这里
https://zhuanlan.zhihu.com/p/36344554
为了对应第二个问题the flood discharge problem,X-engine设计了一个叫做分层存储的架构去解决这个问题,他将record再各个层级间移动,这个地理与LSM-tree,并且用FPGA去做compaction,其架构如下
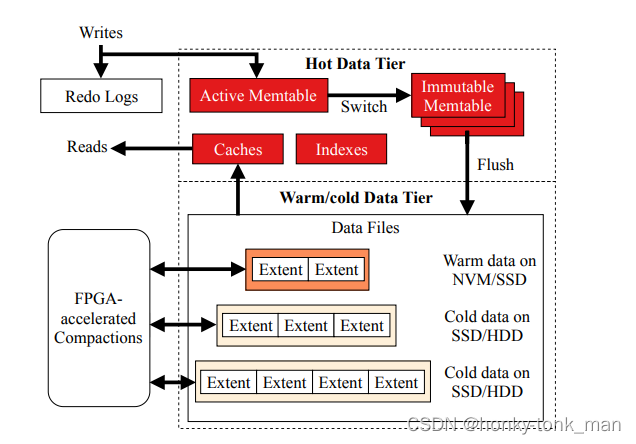
冷热温数据是个啥?其实冷热温是按照访问次数来定义的
Hot data is frequently accessed on faster storage, warm data is accessed less frequently and stored on slightly slower storage, and cold data is rarely accessed and stored on even slower storage.
上述的架构直接将热数据放到内存中,因为最常访问,温数据放到NVM/SSD中,NVM就是非易失性存储的缩写,其速率比内存要慢一些但是掉电不会丢数据,他的速度要比sata的SSD要快不少















 1472
1472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









