










introduction
我们都知道L1/L2/L3cache解决了内存墙的问题,但是作者分析出现有的缓存架构有着天然缺陷,
- 作者列出的many to few communication,也就是L1ache中大量的数据传输到L2cache中,可能对于L1cache的带宽使用率不是很高,而对L2cache的亚里非常大(因为L1和L2cache的缓存速率不一样)
- 因为L1cache的私有性(core独享或者一个SM独享),为了保证cache的一致性我们要使用一致性协议比如MSEI等,这样会导致hight cache line replication 在多个L1 cache之间,这样会减少L1cache的带宽,假如L1 cache的replicate 次数降低,那么会带来更高的缓存命中率,和缓存空间,和提升带宽,和减少L2或者memory的压力(我猜测因为L1 cache是write through导致L2或者main mem压力上升)
为了针对上面所说的2个问题,作者设计了一个新的内存架构,就是Decoupled L1,也就是将L1cache从core中拿出来,也就是分离core和L1 cache…然后将每个core 分离出来的cache聚合成一个大的cache
这个aggregate DC-L1cache可对所有的core访问,这里作者将所有的L1 cache放入一个clustered DC-L1cache中平衡NOC和replicate wast,大概是在这个集群中搞了一个shared cache 专门用于放多个core共享的数据,而不是让所有的DC-L1对所有的core可访问
NoC也要重新设计,让DC-L1cache 连接GPU core和memory
设计动机
cache line replication导致的低效
这里主要讨论为什么要设计decouple l1 cache,还有tightly coupled的设计不高效的地方
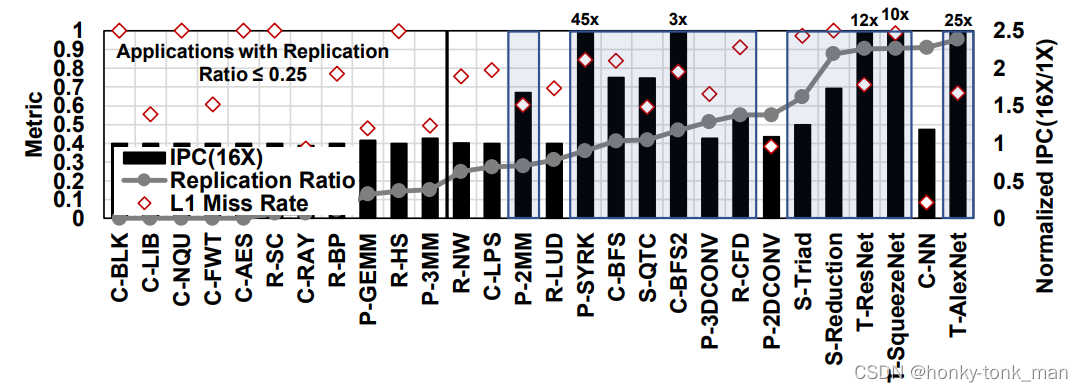
看上述的图,我们首先定义replication ratio指的是除此core外其他core发生L1 cache miss和总L1 cache miss的比
-
首先我们上面讲了每个core(SM core)本地都维护了一个L1cache,当我们的core 请求L1cache发生了cache miss则会向L2cache 独自请求数据,假如多个core都发生各自的L1 cache miss,则多个core都会将L2对应的数据移动到自己独有的L1 cache 中,这样会导致L1cache的浪费
-
因为data replication引起的浪费可能不适应所有的应用,减少/消除浪费的缓存空间,则只有对缓存空间敏感的应用程序才会受益,所以我们为了评估量化,将L1cache放大了16倍,然后我们发现这16个应用都是缓存空间敏感型,我们进一步分析缓存空间的子集replication敏感型,我们评估了L1 miss率(看上图),有的饮用没有收到L1cache私有化的影响(比如C-NN),因为大部分的请求都可以在本地解决,所以我们为了评估什么应用是replication敏感的搞了以下的几个标准
- replication ratio > 25%
- L1 miss rate > 50%
- 当总的L1cache 增加了16倍的容量后运行速率上涨了5%以上的应用
最后我们找到有12个应用是replication-sensitive的(都用蓝色框框标起来)
-
对于简单的测试消除replicate给replication sensitive应用带来的影响,作者设计了一个L1cache,这个L1 cache维护了所有core的读写,来保证没有replication的发生,最后发现L1 miss的概率平均下降了89.5%,因为减少了cache replication,使我们的cache可以存下更多的数据,从而提升缓存命中率
低L1 cache 使用率导致的低效
还是我们提到的L1到L2的many to few的访问模式,导致L1cache的带宽使用率不高,而对L2cache的亚里又非常的大
因为L1cache速率比L2cache 速率快,且每个core都有L1cache,然后每个L1cache 不断地往L2cache 中写数据
这里作者定义了一个叫做core’s L1 accesses的指标衡量每一个core的L1带宽使用情况,直接看下图

所以作者提出将core上的L1cache都分离出来集中管理
decoupled L1 cache 设计思路
先看设计图
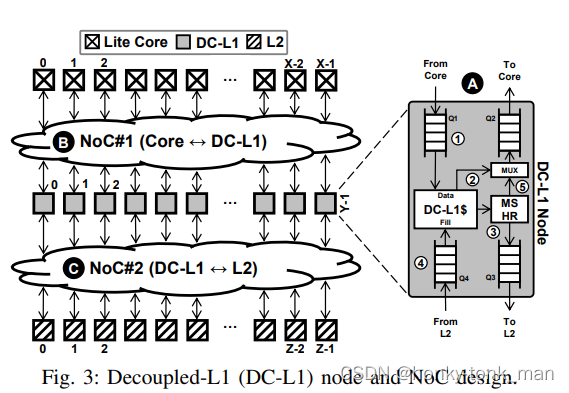
通过上图我们可以明确看到我们从core到DC L1之间有2个queue分别处理core -> dc l1cache,DC L1cache -> core,DC L1cache到L2cache 之间也是有2个queue,功能也和上面差不多,我们知道传统的core中有L1cache还有MSHR,我们除了分离L1cache还分离MSHR,然后我们根据不同的场景介绍作者的设计
-
处理读请求
首先我们的core发送读请求到NoC#1(图中的B),然后通过NOC#1到对应的DC L1cache的收queue中,他会发生以下的步骤
- 首先在DC L1 cache中按照FIFO的方式将请求拿出,到DC-L1$中,这个就是存储L1cache的数据,此时根据缓存命中分2个情况
- 缓存命中,直接将对应的数据发送到次DC-L1 的出队列中返回到NOC#1最后回到core中
- 假如缓存不命中那就先到MSHR中,按照MSHR的处理惯例,将请求发送到DC L1cache的出队列上(Q3),然后队列从NOC#2到L2cache中找数据,假如找到就从DC-L1cache的Q4返回存入DC-L1$中,然后按照上一条的方式将数据返回到core中
注意,作者设计的DC L1只会返回core需要的数据,而不是整个cache line都返回,假如我们把cache line都返回则会浪费我们的带宽
- 首先在DC L1 cache中按照FIFO的方式将请求拿出,到DC-L1$中,这个就是存储L1cache的数据,此时根据缓存命中分2个情况
-
处理写请求
这个写处理请求有点特点,首先我们写请求在DC L1cache中命中,直接驱逐对应的cache line到L2 cache中然后返回消息给core,假如在DCL1 cache写miss,则不在DC L1cache中分配空间,而是直接将写的请求转发到L2中,假如DC-L1cache收到L2发过来的ACK(表明写完成),则直接转发到core中
-
处理Non-L1请求
这里主要是讲我们的指令不需要L1cache参与的,直接由DC L1 cache的Q1转发到Q3,bypass掉DC-L1$,同样的一些不需要L1回复的请求直接由L1的Q4转发到Q2,最后到core上,(因为设计上Core想到L2或者mem必须经过L1)
-
处理原子操作
首先我们baseline的办法是原子操作越过L1cache,交由L2/memory controller操作,我们这里也是一样
为什么原子操作会越过L1cache我也不知道,明天详细查阅资料
这里作者又重新的设计了一下DC-L1 cache
作者假设我们GPU有X个core,每个core有一个DC-L1$,则我们一共有X个DC-L1$,每个DC-L1$大小C,此时作者讲多个X聚合成一个大的DC-L1$,从数量上来讲X > Y,但是从每个的DC-L1$容量来讲Y > X,Y的DC-L1$大小有
X
∗
C
Y
\frac{X * C}{Y}
YX∗C,此时每一个Y DC-L1 cache关联一组core,这一组core对这个Y DC-L1$私有,我们将这个Y DC-L1$代称为PrY,我们可以通过控制Y中有多少个X来达到控制聚合颗粒度
下图画出了一个Pr40(40个X DC-L1cache和成一个Y)的示例图
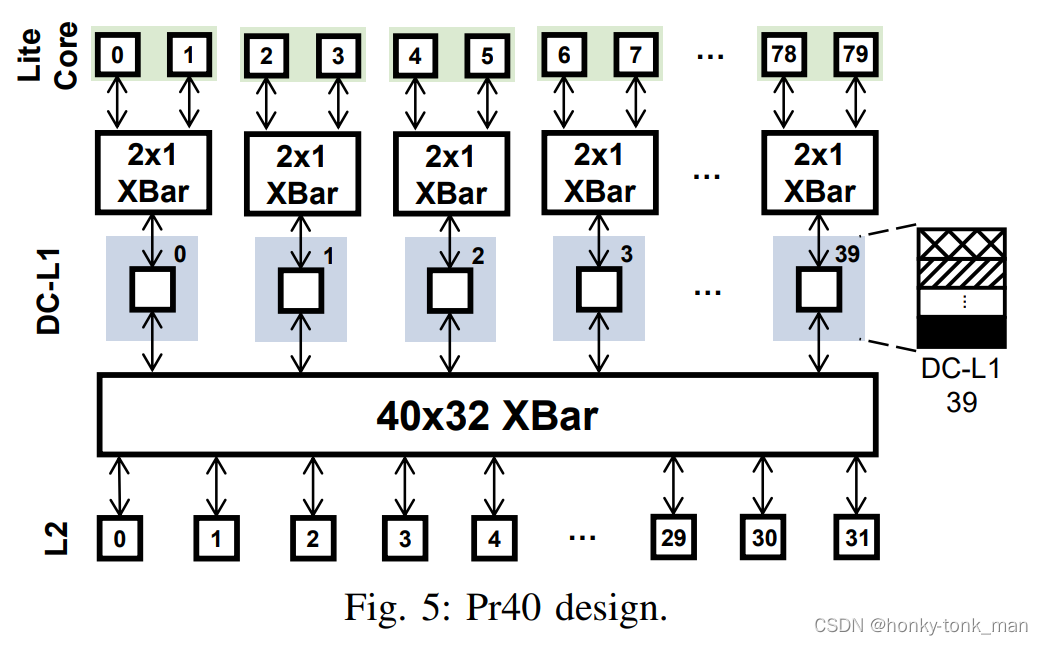
我们可以看到core到DC-L1之间又搞了一个2X1的XBar,每2个core都可以通过这个2X1的NOC#1中的crossbar访问这个私有Y DC-L1 cache,
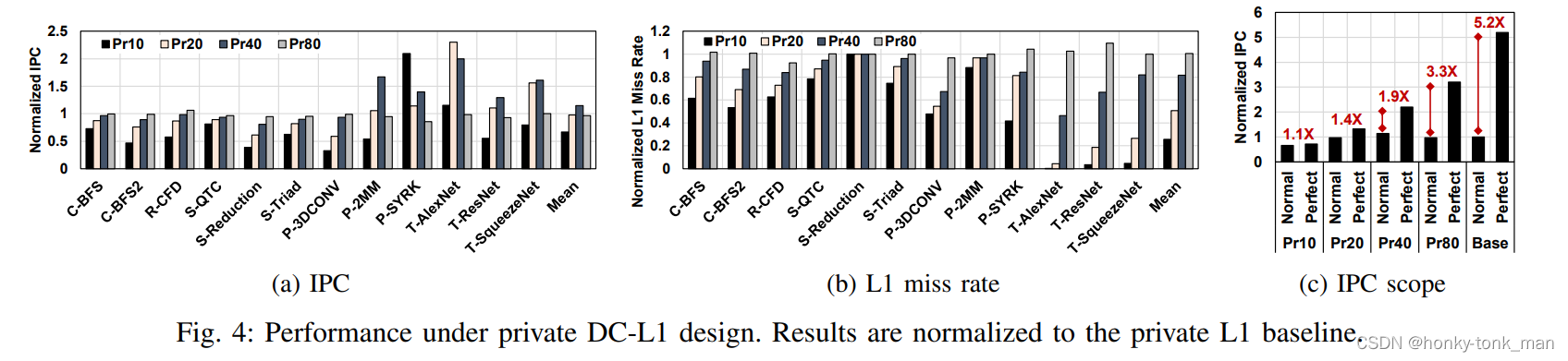
这个时候作者做了个性能的比较,正对Y内含有不同的X DC-L1cache,如下图
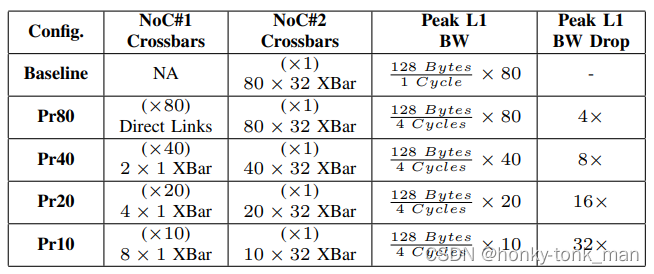
Pr80就是不进行聚合,一共就80个X DC-L1cache,不聚合也是80个Y DC-L1cache
Pr40我们上面讲了就是2和1(2个X合一个Y)
Pr20就是4合1
Pr10是8合1
上面的32指的是我们NoC#1(core to DC-L1)一次发送32byte,所以NOC#2则一共一次可以发送80X32byte的数据(假如是Pr80),一个cache line大小128B,那么我们从DC1一次取数据(一个cache line大小)到core上需要4个周期也就是4次所以L1的带宽峰值就是
128
B
4
c
y
c
l
e
s
∗
80
\frac{128B}{4cycles}*80
4cycles128B∗80(假设Pr80)
为什么baseline可以一次取128B因为base line中core和L1cache是连在一起的所以可以可以一次取一个cache line,而不用经过NoC
我们评估IPC(instruct pre cycle)和L1 cache miss率
如果光看IPC,Pr80和baseline有点像,只不过性能平均少了3%左右
shared DC-L1 cache设计
作者为了减少cache中数据replication还发明了一个shared DC-L1cache,在此之间作者先将所有的DC-L1cache合成一个大的地址范围(不过地址的顺序不是和DC -L1cache的物理顺序一样,而是交错的)如下图
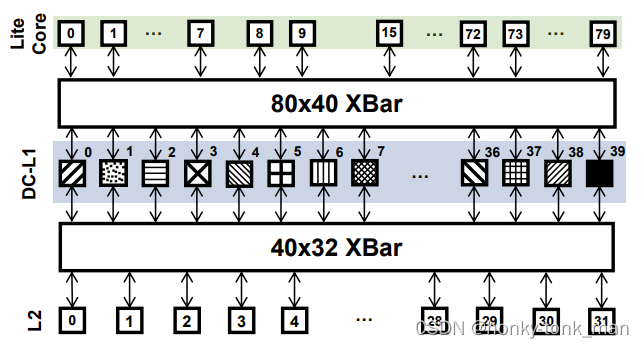
上图中纯黑色的DC-L1cache可能就是一个shared DC-L1cache
当然这个设计需要我们的任何一个core可以穿越任何一个DC-L1,上图中有80个core,40个DC-L1cache,我们把上面的设计统称为SH40,我们把物理地址给映射到这40个DC-L1中比如物理地址是黑色地址范围只能由DC-L1 39这个cache去存储
-
选择home DC-L1缓存:假如一个需要缓存的cache line地址来了(物理地址),我们先要根据映射,找到我们这个cache line应该缓存在那个DC-L1上
这里的物理地址和DC-L1cache的映射是由home bit实现的,大概怎么选作者用到了home bit,但是具体没有提及,我猜测应该是根据物理地址划分成三部分(tag,index(way这里应该换成了DC的index),offset)这种组相联映射
-
处理请求:和之前的设计差不多,就是将对应的请求转发到home DC-L1上
shared DC-L1设计的性能
一样我们这里评测IPC和miss率
看图
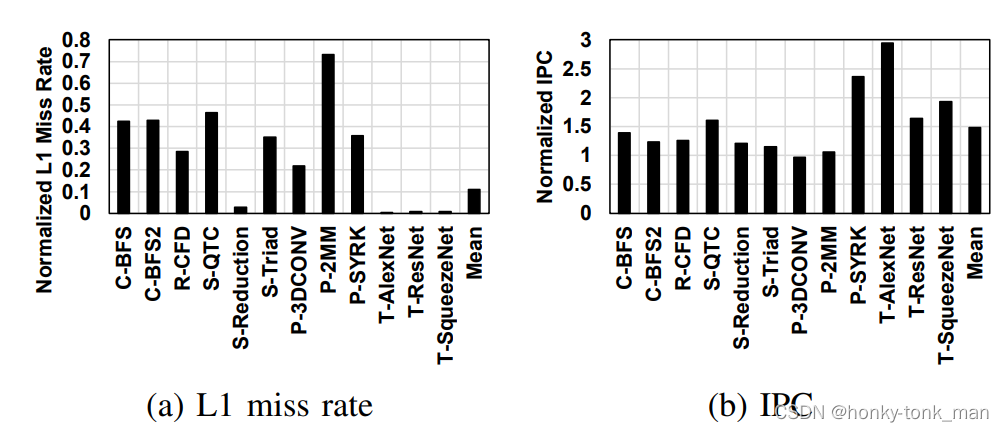
作者对比的是SH40,此时DC-L1的miss率掉了89%平均,因为SH这种方法有效的降低了cache line的replicate率和增加了存储的空间,但是有2个replication-sensitive的应用没有从SH40这个设计中获利,比如P-2MM,只提升了6%,因为SH40有一个非常严重的问题叫做partition camping
partition camping的意思是我们cache是分成多个部分,理想情况下每个部分平均的接收请求,但是有一些应用会让一个parition接收大量的请求,造成带宽的下降
还有一个应用P-3DCONV他的miss率还降低了3%…
针对作者搞得SH方法,作者对一些replication-insensitive的应用也做了一个评估,看下图
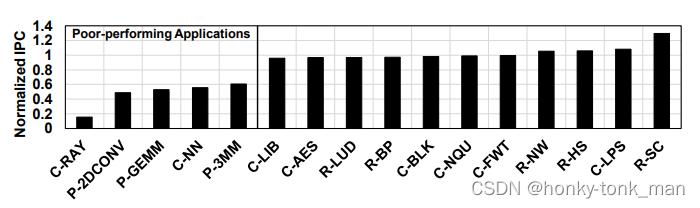
作者给出大部分cache 延迟容忍性比较高的应用表现得都比baseline要好
clustered shared dc-L1 cache
为了减少跨区域访问和增强replication-sensitive应用的效率,并且还不能给replication-insensitive应用的影响,作者又对他的设计进一步的优化,搞出了clustered shared dc-L1 cache
所以作者开始调查cache replication带来的影响,而不是直接消除replication
作者这里介绍了上一步SH的劣势,比如和Pr40相比,虽然replication降低了,但是Noc和static power还是高,
这里clustered shared dc-L1 cache设计我们定义M个DC-L1node可以被N个core访问,Y是总共的DC-L1的数量,Z是我们存在的集群数量,(Z = Y/M),还有就是每个集群都被分配了一个独一无二的地址范围(每个集群而言),看下图
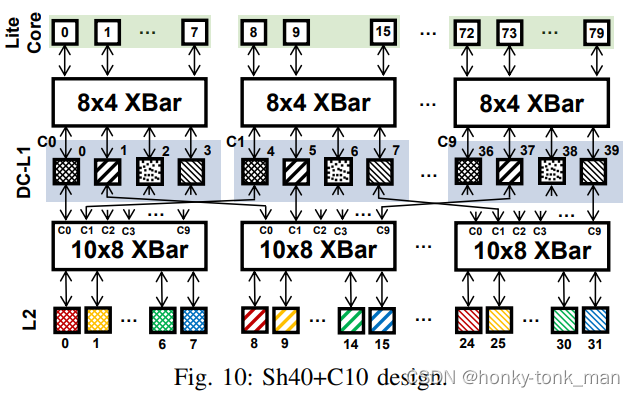
上图中一共又40个DC-L1cache,还有10个集群,每个集群包括4个DC-L1cache,和8个core访问,所以每个集群NoC #1是8*4,通过这个NoC#1到这8个core中,我们因为L1被划分成了不同的集群,那么我们L1每个集群访问L2cache,L2cache也要划分不同的区域,(因为每一个集群的地址都是独一无二的,上图中将L2cache划分成32个slice),作者设定10个DC-L1cache(这些DC-L1cache是不同集群中的) 可以通过crossbar访问8个L2cache slice
后续的操作Home DC-L1和之前的CH都差不多
对于这个clustered shared L1 cache的性能评估首先,评估对象是集群数量,通过观察发现集群数量越大,L1 miss率越高
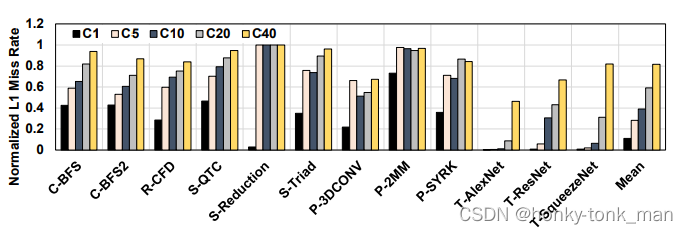
通过上图可以看到评估的对象是C1 C5 C10 C20 C40,随着集群数量的越来越多,L1miss率越高,但是对于baseline来说L1 miss率降了不少,对比baseline C5,C10,C20,L1 miss率分别降低了72%,61%,41%
虽然C5,C10,C20的L1miss率降低,但是其效率还是有着显著提升,C10 但是其性能对比C1还是降低了百分之5,但是大部分的replication-sensitive的应用性能C1要优于其他,因为这些应用对于消除replication带来的cache capacity effective很敏感,但是还有一些应用比如T-AlexNet,C1的性能就不行了,因为集群大于1代表着一个cache line的copies可能存在多个集群中
除此之外作者还对replication-insensitive的应用做了比较
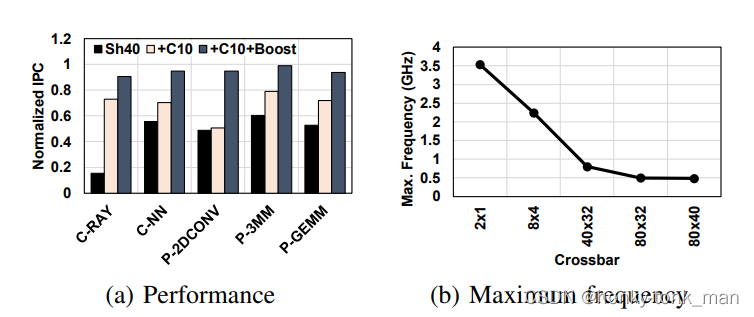
发现在insensitive应用中对比之前的SH和这里的SH+C,发现SH+C性能有着显著的提升,如下图
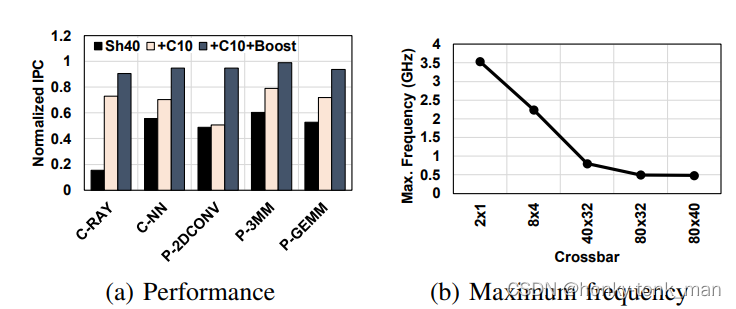
特别是,C-RAY, P-3MM, and P-GEMM饱受partition camping的折磨
首先什么是replication insensitive,就是对于replication不是非常敏感的应用,换句话说每个core拿的数据都不一样,很少发生每个core拿到相同的数据再通过MSEI去维护一致性,对于SH方法中所有DC-L1被化成一个统一的地址(但是地址不是按照DC-L1顺序从大到小划分,而是乱序),他们每个DC-L1都映射着固定的物理地址,也就是说一个范围的物理地址,最终只会被缓存到一个DC-L1中,此时他的miss率就下降了非常多,但是NOC2中通讯次数变多,变多后对于能耗也变高,这个时候有个问题产生,我们的core只取一个DC-L1(假如我们的应用是平均访问全部分布的物理地址还好说)此时miss率高升,这样我们就会不断地往L2或者mem中拿数据,返回到L1,并且缓存到着其中一个DC-L1中,这样NOC不管1或者2的访问次数会飙升,并且其他的DC-L1没有用到,所以对于一些replication insensitive的应用特别是会发生partition camping的应用,假设这个应用只取物理地址的某个范围,恰好这某个范围的物理地址被映射到一个DC-L1cache中,那么这个DC-L1cache 会被反复使用,且miss率飙升,IPC下降,其他的DC-L1cache可能使用率就变低,而clustered shared cache正好解决这个问题
这里还要提及的是不管cpu/gpu,假设我们就一个用户线程(比如主线程),他最终运行在那个core上是看操作系统调度(用户线程->系统线程->硬件线程),只有一个线程通常意义上只能允许一个线程在一个时间运行在一个core上,也许根据调度原则他下个时间调度到下一个core上,但是一个时间内他只能在一个core上跑















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









