







前言
这篇可以说是gnu核心贡献者Ulrich Drepper写的What Every Programmer Should Know About Memory1 这里讲了一些内存和cpu缓存的知识,除此之外又讲了计算机内存发展的历史,比如在上个世纪CPU和内存的速度其实差不多,但是随着内存技术发展缓慢,CPU急速发展,在那个年代CPU频率快速提升直到本世纪初,CPU的设计理念从提升单核频率到多核上(因为频率提升的越高,需要散发的热量更大),又讲了之前内存控制器都是在北桥上(这样导致我们每一次进行内存访问CPU都要先经过北桥,这样我们到北桥的BUS会非常拥堵),现在集成在CPU中然后直接和内存相连接,比如4个CPU,每个CPU都有自己的内存控制器,每个CPU都直接连接着内存(每个CPU连接内存的数量一致)如下图
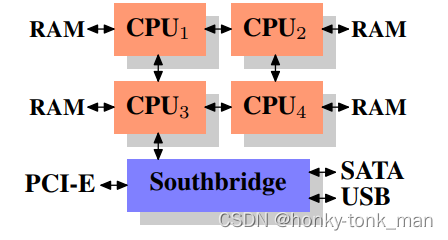
但是这个架构还是有缺陷,比如我们要保证每个cpu直连的内存是对所有cpu所可访问的,比如cpu4连接的内存要对cpu1开放,如果我们cpu1访问cpu1直连的内存那么速度还正常,但是我们CPU1要访问CPU2直连的内存需要进行内部通讯,CPU1要穿过CPU2才能访问CPU2所直连的内存,这样导致有额外的消耗,如果我们CPU1想访问CPU4直连的内存,那么CPU1要内部通讯2次,消耗更大,这个问题也是大名鼎鼎的NUMA架构
DRAM和SRAM
我们知道DRAM一般用于内存,SRAM一般用于CPU缓存,一个bit的DRAM大概需要1个晶体管,一个SRAM大概需要6个晶体管,一次DRAM访问要刷新(将数据读出再写进去,也就是保存数据),而SRAM则不用,DRAM刷新必须要保持64ms一次,为什么DRAM要刷新?因为他会漏电,换句话说它不易长久保存
CPU缓存
CPU缓存对于程序员来说是透明的,但是程序员要协作硬件,也就是写出缓存友好的代码
我们来看看多核cpu的架构
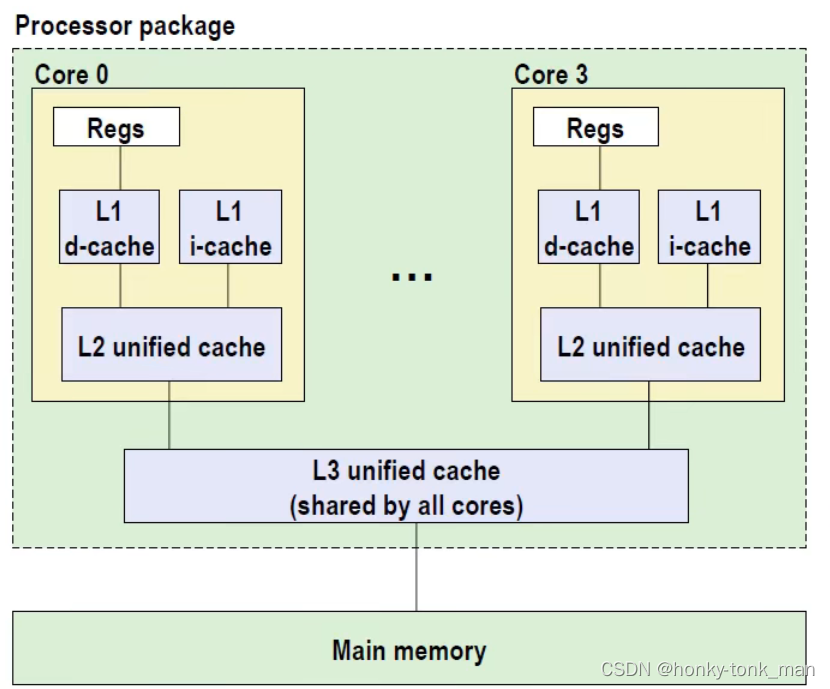
先看一级缓存,每个core的一级缓存分为指令缓存i-cache和数据缓存d-cache,一级缓存的大小大概32KB(i7),8路,访问需要4个时钟周期
二级缓存就大了很多,但是访问速度也就慢了不少,i7大概256KB,访问大概需要10个周期,但是其不区分指令缓存和数据缓存
三级缓存时多个core共享,空间更大(8MB),16路,当然访问周期也达到了40到75cycle
上述的一级缓存,二级缓存,三级缓存的block size或者叫做cache line size都是64Byte,什么意思呢?每一级cache不是单独的一个行,而是由多行(cache line)组成,每一次cache向下级存储要数据缓存到此cache中都是按照cache line size来请求的,比如内存有一个数据只有1个Byte,但是为了缓存到L3 cache中只能把内存中这1Byte数据连带后面的63Byte数据都缓存到L3 cache中占取L3 cache的一行(cache line),
关于CPU的缓存写入有2种方法,分别是write-back和write-through
如果你学过数据库,那么你一定对disk-orient DBMS的buffer pool manager非常熟悉,write-back就像buffer pool manager的写机制一样,当我们写一个page的时候先pin住它,当改动buffer pool中的page后不立即写入磁盘,而是将其视为“dirty page”,当我们因为buffer pool空间不足后准备驱逐的时候,再写入磁盘,write-back也是,先对cache中的数据更改,更改完后将这个cahce line设置为dirty的等准备cache 满了后,再加入新的cache,再做写入下级存储的操作
write-through就比较简单,当我们改动cache后立马将改动写入下级存储这里还要介绍一下write allocate和write no allocate,WA(write allocate)和WNA(write no allocate)都是在发生write miss的时候产生的2种策略,
write allocate:在我们写这个数据之前,先将它从内存中拖到cache中再写,写完后看是write through还是write back 刷新主存
write no allocate:发生cache miss后直接在主存中改数据
有的cache line大小由128Byte,还是要看具体的CPU规格
为什么一级缓存中的指令缓存和数据缓存要分开?因为我们cpu内部有非常多的单元,有取值单元,有数据单元,L1的i-cache设计的靠近CPU的取指单元(instruction fetch),d-cache靠近CPU的数据单元(LSU),这样可以降低延迟,还有一个重要的优点是在一定的周期内,既可以取值,又可以取数据,(因为他们是分离的2个物理部分),假如我们的i-cahce和d-cache在一起,那么CPU在同一时刻只能取指,或者取数据,
cache的组成部分如下
| tag | data block | flag |tag就是我们从内存中fetch的地址(物理地址)
data block就是tag这个地址中存储的真实数据也就是cache line
flag有一位,表明这个cache entire是vaild还是dirty的
通常意义下缓存的大小不计入tag和flag甚至正向纠错码,尽管它们确实会影响缓存的物理区域
cache也有block模式和no block模式,假如cache是block模式一个指令访问一个cache block miss后,其他的线程访问cache,假如访问的地址(物理地址)和上一个指令访问miss的cache block对应的物理地址一样此时就block住,等上一个指令将数据从内存拿到对应的cahce line中被block的地址才release,然后读新的cache block
cache还有no block,这个就要靠MSHR解决
关于MSHR建议看后面的链接https://miaochenlu.github.io/2020/10/29/MSHR/
简单介绍一下MSHR是no-block cache才会用到的,什么是no block cache?就是我们一个cache miss发生后,第二条指令访问缓存发现访问缓存对应的物理地址和上一个指令访问cache cache miss对应的物理地址一样,第二条指令不会block就是no-block cache,MSHR只有no block cache 发生cache miss的时候才会用,当我们的cache miss发生我们去找MSHR,看我们请求的cache block在不在里面,如果在里面(说明前一个指令也是请求相同的cache block),那么我们这个指令就会将自己load还是store这个cache的信息写入MSHR,写完后就不访问内存找数据,而是等待,假如我们的MSHR没有cache block的信息(访问的cache block第一次发生miss),我们就会为这个cache block创建一个MSHR entire,然后去内存请求数据,在这个时候就如我们上面所说,其他的指令如果访问这个cache block miss后发现这个cache block已经有了MSHR entire,就会将自己指令是准备load还是store这个数据写入对应的cache block的MSHR entire中(就不准备去内存拿数据),等创建这个cache block对应MSHR entire的指令从内存返回(此时已经拿到cache block对应的数据)然后更具其他指令存入的MSHR entire的信息(store/load)返回给相应的指令,最后删除这个MSHR entire
假如MSHR太多了,我们一个指令准备创建发现MSHR entire太多了,达到上限,此时指令就stall住
我们可能会看到cpu的L1/L3/L3缓存会写8-way/4-way,这是啥意思呢?还是先回到缓存中,我们知道缓存的存取基本单位是cache line,有的cache line 64字节,有的cache line 128字节,但是我们多个cache line又组成set,多个set组成我们的L1/L2/L3cache,8-way/4-way代表我们一个set中有多少cache line
我们知道内存地址按照位数展开,比如32位的系统最大地址为11111111111111111111111111111一共32个1,那么为了表示方便我们给他变成16进制,每4位二进制组成一个16进制,此时上面的最大地址就变成0xFFFFFFFF,其中一个F代表1111,此时假如我们的前24bit不变,那么地址范围就是0xXXXXXX00~0xXXXXXXFF所以可以代表256个地址,一个地址对应一个字节,那么总共有256个字节也就是256B
关于我们的8way和4way还有一个概念非常重要就是set associative cache,指的是内存到每一个set是一对一映射,比如我的L1cache的cache line 64B,8way,总大小32KB,那么得出总共有32KB/64B=512个cache line,因为8 way,所以可以分成512/8=64个set(一个set 8个cache line),还记得我们之前说过每一个cache line的结构如下|tag|cache line(data)|flag|,这里可以明确告你tag代表cache line内存的真实地址的一部分(前一部分,且物理地址),tag和flag都不计入cache line的总大小里去
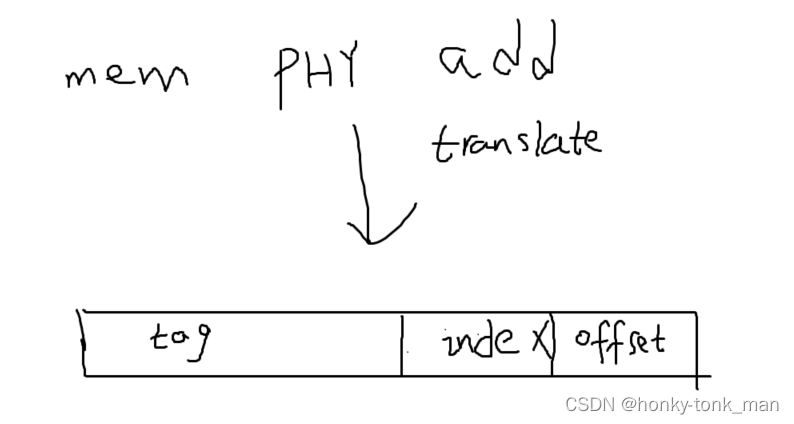
我们一个cpu想在L1下查找一个物理地址,首先会将物理地址分成如下|physical page address| set index| offset|部分其中tag(物理地址的一部分)占32-6-6(也就是物理地址的前20位,32代表物理地址的长度32位,第一个6代表我们用2的6次放可以寻址所有的set,也就是可以用6个bit位去寻址64个set,第三个6代表我们可以用6个bit寻址一个长64B的cache line),所以set index占有6bit,offset 6个bit,假如来了一个物理地址
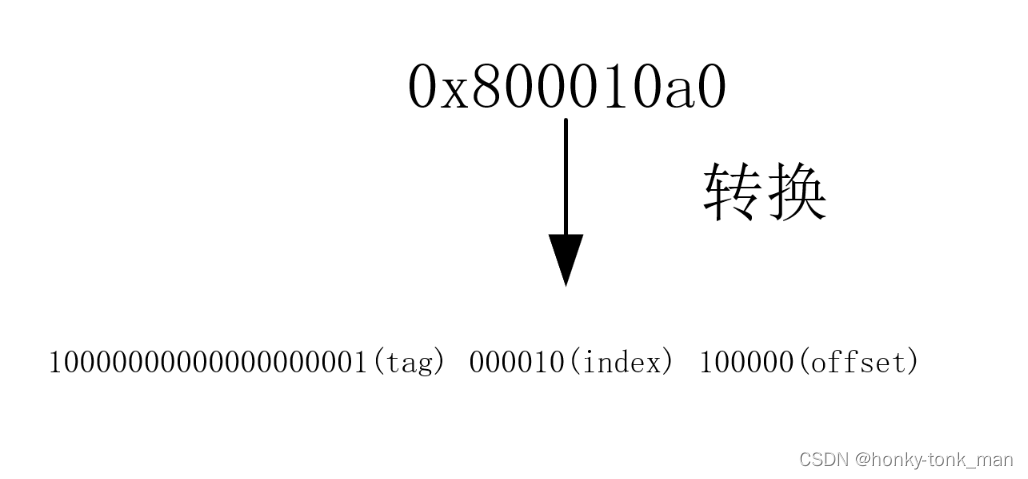
0x800010a0,将这个物理地址划分成三段就我们上面算的tag length位20bit不变,先找index也就是这6bit000010我们直接确定这个地址对应的数据应该存在第二个set中,然后根据物理地址的tag也就是物理地址的前20bit去进行查找在这个8-way中进行匹配,找到是哪一个way,找到后就再根据offset精确到字节
所以说我们将数据存入cache中也不是随便存,也不是说从这个字节后面存一个cache line大小的数据到L1cache中就完事,而是要先将物理地址转换成
tag| index | offset后确定存入那个set,再看要取的数据位于那个offset中假设offset为111111,那么我们只能取这个bit的前63个bit加这个数据缓存到L1cache中
在多个core上因为我们多个core共享L3级别的缓存,假如我们多个core同时对L3级别的缓存写(先拿到自己的L2级别缓存中,在拿到自己的L1级别缓存中更改数据,再写回L3级别缓存)那么会导致L3缓存不一致性,此时我们有一个非常著名的协议叫做MESI保证缓存的一致性
MESI是4个状态的缩写,分别是
- modified
the local processor has modified the cache line , this also implies it is only copy in any cache
- exclusive
the cache line is not modified but known to not be loaded into any other procesor’s cache
- shared
the cache line is not modified and might exist in another processor’s cache
- invaild
the cache line is invalid i,e unused
有个例子如下
- 我们有core 1和core 2,分别从L3 cache中拿到了data这个变量,data等于5,此时data = 5 在core 1和core 2自己的缓存中,首先core 1将数据拿到自己的缓存中core 2还没拿,此时core 1这个数据的状态是E(exclusive),当core 2拿到这个数据到自己的缓存中就变成S(shared)
- core1更改了data的数值(core1中的data将被改为modified状态),将data改为10,但是此时此刻core2中data还是旧数字5
- core1改完data后通过总线告诉core2我已经将data数据改了,请将data标记为invaild,core2收到后就将data标记为invaild,如果core 2准备访问这个数据就会cache miss(因为这个数据被标记为invaild),然后core2会去向core1要data数据的最新值,core1将data的新值发送给core2后将data变成shared状态,core2收到新值后也会将data变成shared state
为了提升新能我们也可以用编译器pre-fetch数据到缓存中
这里还有一个知识点叫做缓存颠簸(cache thrashing),讲的是我们将一个内存的一个数据存入cache中,除了数据本身还会存入这个数据后续的一些数据(填满cache),此时如果我们第二次访问的数据是这个缓存到cache数据之外的数据那么会发生cache miss,然后缓存新的一批进来,这样重复导致cachemiss的情况一直在发生,一直没有好好的利用cache,换句话说就是低效代码
int arr[1000][1000];
for(int i=0; i<1000; i++)
{ for(int j=0; j<1000; j++)
{ arr[j][i] = i*j; // some random operation.
}
}
上面就是一个低效代码
虚拟内存
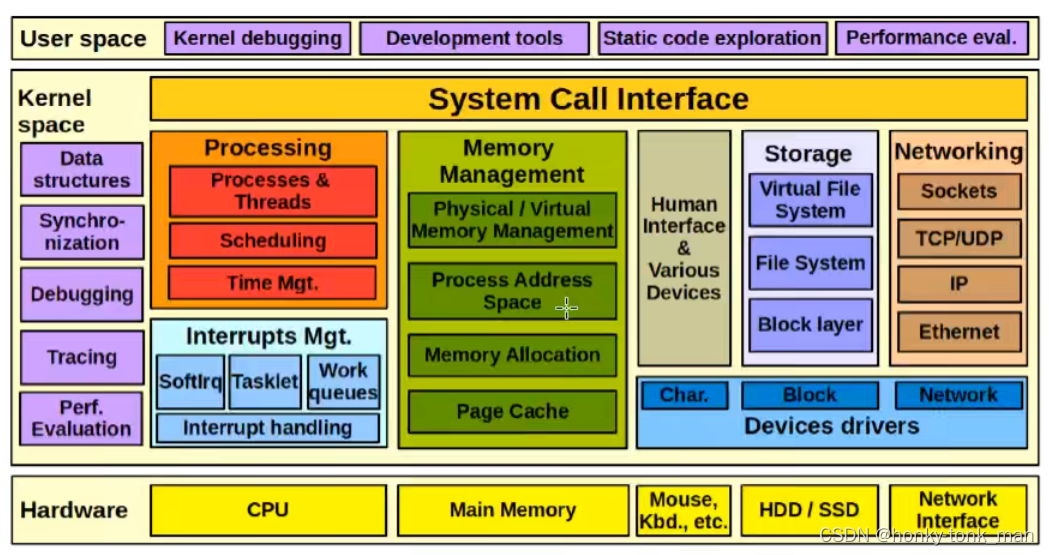
虚拟内存这个东西其实是和内核(os)强相关的,linux内核有专门应对内存管理的模块,如下
为什么我们需要虚拟内存,或者直接使用物理内存会发生什么?
因为我们内存是稀缺资源,所有的程序都会嫌内存不会用,但是多个程序又不得不公用一个内存,大家都知道每个进程的内存从进程角度,每个进程认为主机内所有内存都是属于自己的没有人和自己抢,但是实际上进程只是运行在虚拟内存上(虚拟内存要映射到物理内存)
为什么要这样设计虚拟内存?假如我们没有虚拟内存,就一共32 it 的ram(一共4G,一个bit一个字节),进程1要1个G,操作系统说没问题直接将物理内存的1G分配给进程1,进程2找操作系统要2G,操作系统看了以下发现还有3个G可用空间,就直接将2G物理内存分给进程2,此时进程3也找操作系统要2G内存,但是操作系统看发现只有1G可用空间了,就拒绝了进程3的请求,那么进程3就跑不起来,但是我们细看进程1和进程2真正所使用的内存空间,你会发现,进程1和进程2都没完全使用操作系统分配给他的内存空间,并且使只使用了一点,还空了一大部分没用,但是这一大部分操作系统不能说收回给进程3用,所以为了解决这个问题我们引入虚拟内存,假如我一共就4个G,进程1向os请求内存,os会直接把4个G都分配给它(4个G都是虚拟内存),进程1因为不会把分配的4个G都用完,所以进程1用多少,os给他多少,其余的都分配给其他的进程(当然其他的进程也是分配虚拟内存)
假如我们的物理内存用完了,我们可以使用LRU等算法进行页的驱逐,驱逐到磁盘中,等我们的进程找这个页的数据(在进程的虚拟内存中是存在的,但是在物理内存中已经没了,因为物理内存不够被存到磁盘中)我们的操作系统发现物理内存却页,就会把相应的页从磁盘中拿到物理内存中再连接对应的进程的虚拟内存,当然因为涉及到磁盘访问,这样就会导致性能急剧下降
当然如果我们的2个进程所访问的虚拟内存数据一样,我们经过map后可以map到同一个物理内存页,这个页也叫做shared page
和数据库的buffer pool机制一样,但是操作系统的物理内存page out到磁盘的swap区域
操作系统转换虚拟内存和物理内存直接的地址对照表叫做mmu,mmu是硬件!一般集成到cpu中,为了加速MMU,我们给MMU也搞了一个缓存叫做TLB
我们写C/C++会遇到segment fault是咋回事呢?首先我们的操作系统可以对物理内存做控制,比如划分一块区域只读,或者只能写,此时我们的程序想越界访问它不应该访问的区域就会发生segment fault,比如你在栈中分配了4个字节的空间你非要访问第五个字节,但是第五个字节可能被os映射成只写的,那么你就越界了,直接segment fault,假设第五个字节被os分配的只读那么你可以读不会报错,但是读的数据就不是你想要的数据…
我们可能常常听过用户空间和内核空间,简而言之内核空间就是那个运行的空间,用户空间是用户进程所使用的空间,我们所说的内核空间和内核空间都是属于虚拟地址空间,并且内核空间在32位系统大小1个G,但是这个大小是可调整的,并且内核空间也分内核虚拟地址和内核逻辑地址,内核逻辑地址是连续的地址,内核虚拟地址则不连续,所以内核逻辑地址一般映射到一块连续的物理地址上,因为地址连续,所以适合拿来做DMA
我们操作系统做内存管理的时候最小的管理单元是Page,Pagesize是可调整的默认4K,page是虚拟内存的概念,而page frame是物理内存的页,他们一般一一对应
我们之前讲到page fault是由虚拟内存进行地址转换后发现没有找到对应的页,或者对应的page frame是别的进程的此时mmu发现这个错误就会先发一个中断再抛出一个错误给kernel,kernel进行处理,将虚拟内存需要的页从disk的swap中取到对应空闲的page frame中(物理内存),然后更改mmu对应的内容,最后返回对应的数据给进程
OOM就是out of memory的简称意思是内核分配的内存大于实际内存就会报这个错误,并且杀死进程
SLAB cache指的是内核提前分配好的一些cache块,等内核调用
kmem_cache_alloc()的时候将这些分配好的SLAB cache分配给对象,这有点像线程池,提前分配好线程,等需要的时候直接返回即可,注意SLAB cache是给内核空间用的而不是给用户空间用的
虚拟地址和物理地址的简单转换
首先我们的OS维护了一个叫做Page Directory的东西用来存储每个physical page(page frame)的地址,我们的virtual address大致分为2部分,一部分为page directory中page的地址(Page directory中目标page的下标),第二部分是这个physical page的offset,这样一个虚拟地址可以直接通过page directory转换成物理地址
virtual address
| Directory | offset |
好像我们的MMU硬件也是用来干虚拟地址转换物理地址的,但是OS为何又维护一个Page Directory?他们的功能不就重复了吗?
首先os需要告诉MMU该如何将虚拟地址转换成物理地址,MMU使用Page table将虚拟地址转换成物理地址,而不是MMU自己维护了一个Page table,当然MMU自己有一个寄存器叫做TLB去存储最近访问的虚拟地址和物理地址的转换(假如MMU tlb miss了后就需要去walk page table,因为page table在内存中MMU进行page walk非常慢),page table还保存了这个page是否为dirty的标志位,还有要注意的是TLB缓存是每一个core都有的,并且TLB缓存被设计到L1缓存旁边,减少周期,当我们一个虚拟地址和物理地址的mapping都被缓存到每个core的TLB缓存中后,假如有一个core更改了这个TLB的映射,那么其他的core都要更新,这个也叫做TLB shootdown
记住上面的virtual address的directory指的是page directory,page directory和page table是2个东西,他们共同维护了一个虚拟地址向物理地址的转换,首先我们找到page directory,每个page directory的一个entire指向一个page table,其实虚拟地址分为三部分,首先是确定page directory的地址(可能存在某个寄存器里),第二部分找到对应的page table,第三个找到对应的page table entire,最后是page中的offset,一个page table entire的结构如下
frame number就是物理地址的位子
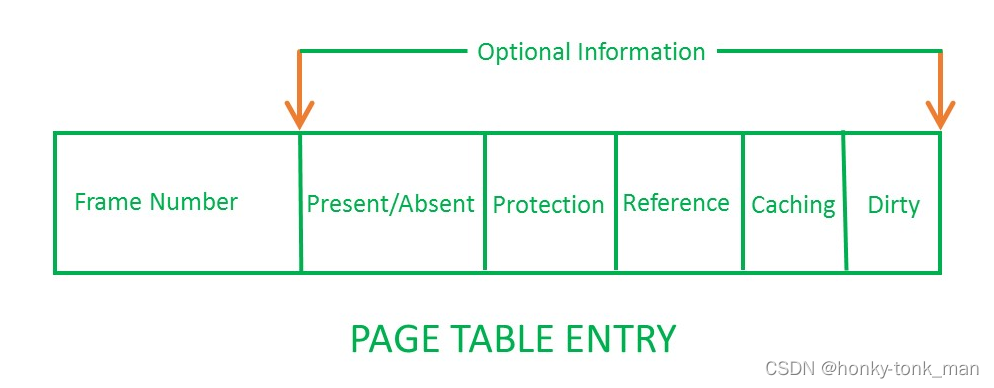
这里我们还要注意一点,每一个进程可能需要一个page table…一个page table大小多大呢?假设在32bit系统(总共4G),每个page大小4k,那么一共有 2 20 2^{20} 220个page存在,假设我们每一个PTE(page table entire)需要4个字节(PTE就是page table的每一个元素),那么每一个page table大概需要4M,记住之前我们讲过一个进程就要一个page table,100个进程就需要400M来存储page table(因为我们一个page table entire表示一个page),所以我们需要多级页表
多级page table
多级页表可以看这里
mmap原理,首先我们直到mmap是将外设硬件或者硬盘中的空间映射到mmap分配的内存中(虚拟内存),那么他到底是怎么工作的呢?
首先我们mmap分配完一个虚拟地址返回后,其在page table中并没有映射物理内存地址,所以,程序第一次访问mmap分配的虚拟地址会发生page fault,page fault会由MMU引起一个exception,(注意的是exception和interrupt处理方式一样,对于CPU来说interrupt和exception都有一个number,这个number可以看成index of处理进程的程序,当exception和interrupt发生,CPU进入内核模式更具对应的Number运行对应的程序去处理),cpu接受到这个exception后根据这个exception对应的number去运行对应的处理进程,怎么处理呢?内核会去allocated一个内存然后将file中的数据存到新分配的物理内存上,然后改page table
上面提到了exception和interrupt,简单说明了exception和interrupt处理方式一样,对于CPU来说interrupt和exception都有一个number,这个number可以看成index of处理进程的程序,当exception和interrupt发生,CPU进入内核模式更具对应的Number运行对应的程序去处理,那么exception和interrupt有和区别呢?
interrupt是一中exception,exception有4种,分别是interrupt,trap,fault ,abort,区别如下
class cause async/sync return behavior interrupt Signal from I/O device Async Always returns to next instruction Trap Intentional exception(syscall) Sync Always returns to next instruction Fault Potentially recoverable error Sync Might return to current instruction Abort Nonrecoverable error Sync Never returns
https://akkadia.org/drepper/cpumemory.pdf ↩︎















 7596
7596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









