






GPU架构
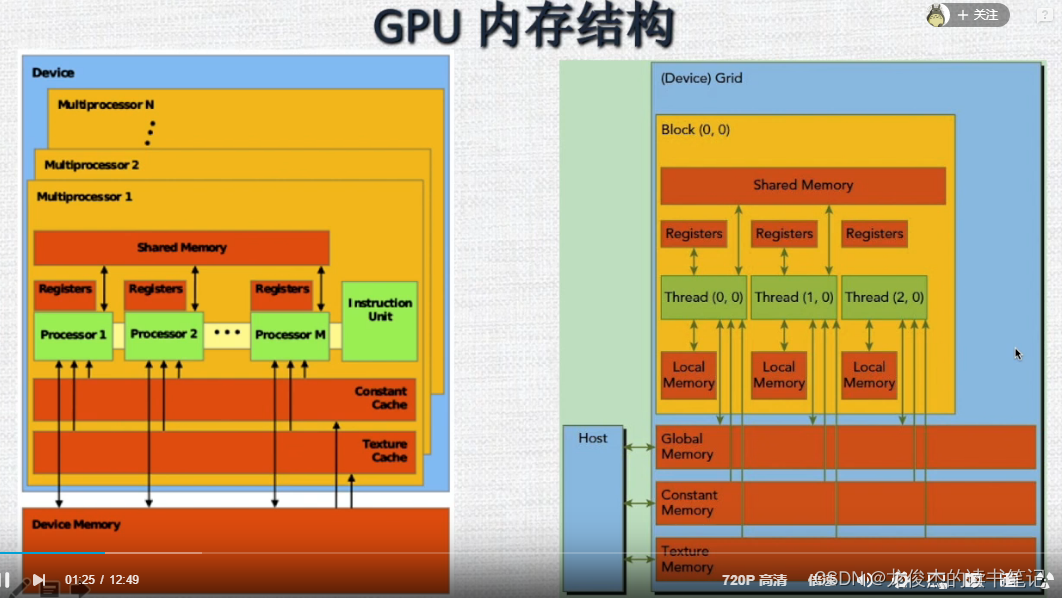
GPU内存类型及生命周期
GPU内存类型及生命周期
- Local memory: 每个线程都有自己的私有本地内存及寄存器
- Shared memory:可以被线程块中所有线程共享,周期与线程块一致;
- Global memory:所有的线程都可以访问。平时所说的 “显存”,相对来说,速度最慢
- Constant memory常量内存和texture memory纹理内存:只读内存块。所有线程均可访问。对于一个应用来说,全局内存、常量内存和纹理内存具有相同的生命周期。
- L1 cache、L2 cache:每个MP有L1、L2 cache,MP 通过L2与global memory连接
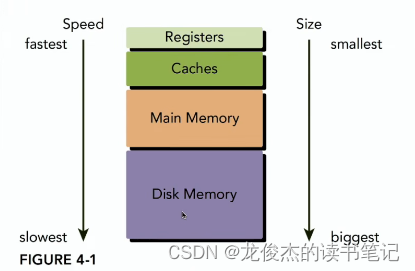
可编程内存

寄存器

本地内存

2.0 指GPU的计算能力
共享内存

Q: MDC的访存操作可否并行?(一个AIcore核内)

共享内存访问冲突


warp: 一个block中有若干个thread,每warpsize个thread称为一个warp [见 GPU的线程模型]
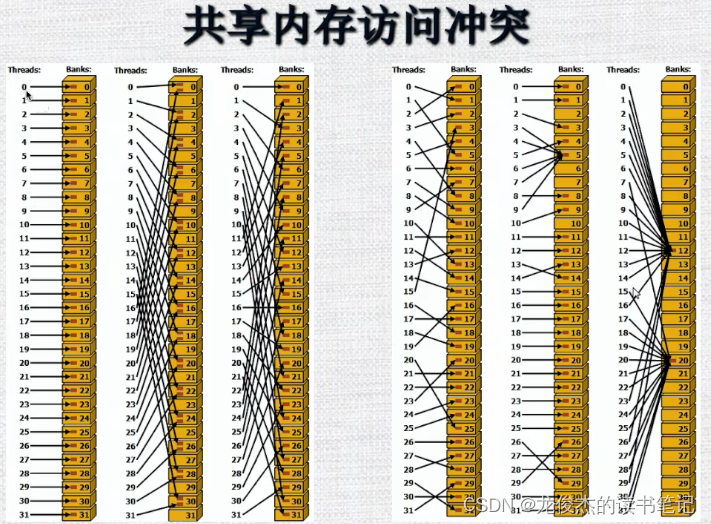
线程访问banks示意图,左图及右图1 均为无访问冲突
右图2 存在3 4 6 7 9线程同时访问一个bank,因此硬件会将请求分成5个没有冲突的访问序列。
常量内存

纹理内存

全局内存

全局内存对齐访问

GPU缓存
















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









