







隐变量
什么是隐变量呢,让我们先简单的说一下,我们估计算法在做的一些事情,我们要做的其实就是估算出概率模型的参数,概率模型是什么呢?你可以简单把它理解成一个分布,甚至说可以把它理解成一个函数,我们的估计算法就是为了求解出这些函数的参数而存在的。这边借用知乎上的一个例子,希望能够解释清楚隐变量是什么?
如果你站在这个人旁边,你目睹了整个过程:这个人选了哪个袋子、抓出来的球是什么颜色的。然后你把每次选择的袋子和抓出来的球的颜色都记录下来(样本观察值),那个人不停地抓,你不停地记。最终你就可以通过你的记录,推测出每个袋子里每种球颜色的大致比例。并且你记录的越多,推测的就越准(中心极限定理)。然而,抓球的人觉得这样很不爽,于是决定不告诉你他从哪个袋子里抓的球,只告诉你抓出来的球的颜色是什么。这时候,“选袋子”的过程由于你看不见,其实就相当于是一个隐变量。隐变量在很多地方都是能够出现的。现在我们经常说的隐变量主要强调它的“latent”。所以广义上的隐变量主要就是指“不能被直接观察到,但是对系统的状态和能观察到的输出存在影响的一种东西”。所以说,很多人在研究隐变量。以及设计出各种更优(比如如可解释、可计算距离、可定义运算等性质)的隐变量的表示。
EM算法
EM(Expectation-Maximization)算法是一种常用的估计参数隐变量的利器,也称为“期望最大算法”,是数据挖掘的十大经典算法之一。EM算法主要应用于训练集样本不完整即存在隐变量时的情形(例如某个属性值未知),通过其独特的“两步走”策略能较好地估计出隐变量的值。
EM算法与初值的选择有关,选择不同的初值可能得到不同的参数估计值。因此在实际中,常用的办法是选取几个不同的初值进行迭代,然后对得到的各个估计值加以比较,从中选择最好的。
EM算法思想
EM是一种迭代式的方法,它的基本思想就是:若样本服从的分布参数θ已知,则可以根据已观测到的训练样本推断出隐变量Z的期望值(E步),若Z的值已知则运用最大似然法估计出新的θ值(M步)。重复这个过程直到Z和θ值不再发生变化。
简单来讲:假设我们想估计A和B这两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。

现在再来回想聚类的代表算法K-Means:【首先随机选择类中心=>将样本点划分到类簇中=>重新计算类中心=>不断迭代直至收敛】,不难发现这个过程和EM迭代的方法极其相似,事实上,若将样本的类别看做为“隐变量”(latent variable)Z,类中心看作样本的分布参数θ,K-Means就是通过EM算法来进行迭代的,与我们这里不同的是,K-Means的目标是最小化样本点到其对应类中心的距离和,上述为极大化似然函数。
EM算法的推导过程
jensen不等式
在介绍推导过程的时候,需要明白jensen不等式,他是一个关于凸函数的一个定理,直接上公式定义;
如果f是凸函数,X是随机变量,那么

特别地,如果f是严格凸函数,那么 当且仅当
当且仅当 ,也就是说X是常量。
,也就是说X是常量。
这里我们将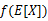 简写为
简写为 。
。
如果用图表示会很清晰:

这里需要解释的是E(X)的值为什么是(a+b)/2,因为有0.5 的概率是a,0.5的概率是b,于是他的期望就是a,b的和的中间值了。同理在y轴上的值也是如此。
EM算法数学推导
当样本属性值都已知时,我们很容易通过极大化对数似然,接着对每个参数求偏导计算出参数的值。但当存在隐变量时,就无法直接求解,此时我们通常最大化已观察数据的对数“边际似然”(marginal likelihood)。

这时候,通过边缘似然将隐变量Z引入进来,对于参数估计,现在与最大似然不同的只是似然函数式中多了一个未知的变量Z,也就是说我们的目标是找到适合的θ和Z让L(θ)最大,这样我们也可以分别对未知的θ和Z求偏导,再令其等于0。
然而观察上式可以发现,和的对数(ln(x1+x2+x3))求导十分复杂,那能否通过变换上式得到一种求导简单的新表达式呢?这时候 Jensen不等式就派上用场了
注意,这里的ln(*)函数为凹函数,故可以将上式“和的对数”变为“对数的和”,这样就很容易求导了。

(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式。对于每一个样例i,让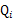 表示该样例隐含变量z的某种分布,
表示该样例隐含变量z的某种分布,![clip_image032[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616025060.png) 满足的条件是
满足的条件是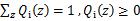 。于是就来到了问题的关键,通过上面的不等式,我们就可以确定式子的下界,然后我们就可以不断的提高此下界达到逼近最后真实值的目的值,那么什么时候达到想到的时候呢,没错,就是这个不等式变成等式的时候,然后再依据之前描述的jensen不等式的说明,当不等式变为等式的时候,当且仅当,也就是说X是常量,推出就是下面的公式:
。于是就来到了问题的关键,通过上面的不等式,我们就可以确定式子的下界,然后我们就可以不断的提高此下界达到逼近最后真实值的目的值,那么什么时候达到想到的时候呢,没错,就是这个不等式变成等式的时候,然后再依据之前描述的jensen不等式的说明,当不等式变为等式的时候,当且仅当,也就是说X是常量,推出就是下面的公式:

再推导下,把![]() 乘过去等式右端,再两边都对所有z(i)求和(右端提取公因子c,这个认为每个样例的两个概率比值都是c),由于
乘过去等式右端,再两边都对所有z(i)求和(右端提取公因子c,这个认为每个样例的两个概率比值都是c),由于 (因为Q是随机变量z(i)的概率密度函数),则可以得到:
(因为Q是随机变量z(i)的概率密度函数),则可以得到: ,再次继续推导;
,再次继续推导;

通过数学公式的推导,简单来理解这一过程:固定θ计算Q的过程就是在建立L(θ)的下界,即通过jenson不等式得到的下界(E步);固定Q计算θ则是使得下界极大化(M步),从而不断推高边缘似然L(θ)。从而循序渐进地计算出L(θ)取得极大值时隐变量Z的估计值。
EM算法也可以看作一种“坐标下降法”,首先固定一个值,对另外一个值求极值,不断重复直到收敛。这时候也许大家就有疑问,问什么不直接这两个家伙求偏导用梯度下降呢?这时候就是坐标下降的优势,有些特殊的函数,例如曲线函数z=y^2+x^2+x^2y+xy+…,无法直接求导,这时如果先固定其中的一个变量,再对另一个变量求极值,则变得可行。
最后就得出了EM算法的一般过程了:
循环重复直到收敛
(E步)对于每一个i,计算

(M步)计算
















 5188
5188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









