








题目:基于级联超分辨率和身份先验的人脸超分
1、引言
主要思想
到目前为止,以令人信服的方式(尤其是在高放大倍数下)获得任意特征的超分辨率人脸图像仍然是一个未解决的问题,主要有以下两个原因:
1、人脸超分任务的模糊性,对于特定领域的SR问题,如面部幻觉,解决方案空间已经受到面部外观的限制,仍然有压倒性数量的合理HR解决方案同样能很好地解释观察到的LR输入。
2、很难将强先验信息集成到FH模型中。
我们解决了在高倍率下对低分辨率输入的高分辨率人脸图像产生幻觉的问题。我们使用卷积神经网络(CNNs)来解决这一问题,并提出了一种新的(深度)面孔超分模型,该模型将身份先验信息融入到学习过程中。该模型由两个主要部分组成:i)级联超分辨率网络,用于对低分辨率人脸图像进行放大;ii)人脸识别模型集合,在训练过程中充当超分辨率网络的身份先验。与大多数竞争的超分辨率技术依赖单个模型进行放大(即使具有大的放大系数)不同,我们的网络使用多个SR模型的级联,这些模型使用2倍的步长逐步放大低分辨率图像。这一特性允许我们以不同的分辨率应用监控信号(目标外观),并在多个尺度上结合身份约束。所提出的C-SRIP模型(Cascaded Super Resolution With Identity Priors)能够在不受约束的条件下提升(微小)低分辨率图像的分辨率,并对不同的低分辨率输入产生视觉上令人信服的结果。
本文贡献
1、引入了一种新的基于CNN的人脸幻觉模型C-SRIP,该模型将多尺度的身份先验信息集成到SR网络的训练过程中,并保证了最新的FH效果。据我们所知,该模型首次尝试利用多尺度身份信息来约束基于深度学习的SR模型的解空间。
2、介绍了一种级联SR网络结构,它以2倍的放大倍数实现图像的超分辨率,并提供了一种方便而透明的方式来合并多个尺度的监控信号。一旦经过训练,SR网络就能够在放大倍数为8倍的情况下对微小的未对齐的24×24像素LR图像产生幻觉,并产生逼真和视觉上令人信服的幻觉结果。
背景:到目前为止,以令人信服的方式获得任意特征的超分辨率人脸图像仍然是一个未解决的问题;
方法:引入了一种新的基于CNN的人脸幻觉模型C-SRIP,将多尺度的身份先验信息集成到SR网络的训练过程中,并且我们的网络是一种级联SR网络结构,使用2倍的步长逐步放大低分辨率图像;
结论:所提出的C-SRIP模型能够在不受约束的条件下提升(微小)低分辨率图像的分辨率,并对不同的低分辨率输入产生视觉上令人信服的结果。
2、网络结构
C-SRIP由两个主要组件组成:i)围绕强大的级联残差架构构建的用于图像放大的生成性SR网络,以及ii)在训练期间用作身份信息源的人脸识别模型集合。如图1所示,C-SRIP的目标是定义从LR输入脸部图像x到HR对应y的映射fθSR。
- C-SRIP模型的生成部分,级联SR网络,是一个52层的CNN,它将LR人脸图像作为输入,并以8倍的放大倍数对其进行超分辨率处理。网络使用一系列级联的所谓SR模块逐步放大LR输入图像,其中每个模块仅将图像放大2倍。
- 利用先验信息在训练过程中约束随机共振模型的解空间是超分辨领域中的一个关键机制。身份信息与语义内容相关(即:图像中是谁?)。而不是感知质量(即:图像在视觉上有多令人信服?)。在SR图像中,它代表了约束跳频模型解空间的自然选择。事实上,从图像增强以及内容保存的角度来考虑FH,并将这两种观点结合到FH模型中以获得最佳结果似乎是直观的。对于C-SRIP,我们将每个识别模型与SR模块之一相关联,并将其用作相应SR输出的身份,如图1所示。由于每个SR模块可以被显示为仅向输入图像添加高频细节(见图2左侧),因此我们预先训练所有识别模型以仅响应幻觉细节,而忽略由输入和SR图像共享的低分辨率内容(见图2右侧)。

图1 C-SRIP模型的图解。该模型由一个产生式SR网络和一组人脸识别模型组成,这些模型在训练过程中充当身份先验。

图2 每个SR模块在扩展过程中添加高频面部细节(左)。识别模型被预先训练为仅对这些细节作出反应(正确),因此在训练期间用作身份先验

训练数据生成。该图(从左到右)显示了一个示例,左侧是生成的训练图像四元组,然后分别是三种不同空间分辨率的残差图像)。注意,残差是通过从原始参考图像减去给定分辨率的模糊版本的参考图像来生成的。
3、损失函数
1、使用分类交叉熵损失函数LCE来训练SqueezeNet模型,用于基于生成的残差图像进行分类:
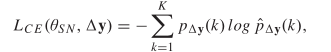
2、首先在8×超分辨率图像上定义基于(单尺度)SSIM的损耗。与基于补丁的SSIM不同,我们使用高斯核和卷积运算来构造SSIM,这些操作很容易使用普通的深度学习框架来实现。
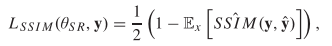
将C-SRIP模型的总体损失定义如下:
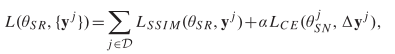
4、实验结果

九种最先进的SR模型进行定性比较。前两行显示LFW的样本结果,后两行显示Helen的结果,最后两行显示CelebA数据集的结果。每行的第一列显示了输入的24x24像素LR图像

在最具挑战性的任务中,C-SRIP与9种最先进的SR模型进行了比较,其中24×24像素的图像被放大到192×192像素的最终大小(使用8×8的放大系数)。

C-SRIP消融研究结果。Baseline没有级联SR模块和中间监管的基线SR模型。B-SSIM:基线SR模型(基线),但使用建议的基于SSIM的损失进行训练。C-SSIM:级联SR模型,使用提出的基于SSIM的损失进行训练,但没有身份先验,也没有多尺度监督。C-SSIM-M:级联SR模型,使用多尺度监督和提出的基于SSIM的损失函数进行训练,但没有身份先验。C-SRIP:多尺度SSIM和身份监管的C-SRIP模型。

消融研究的可视结果。















 2472
2472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









