









 介绍INSIDER,一种存算一体系统,利用FPGA解决数据墙问题,提供文件抽象简化编程,确保数据安全。适用于高效存储场景,通过动态带宽调度优化资源利用。
介绍INSIDER,一种存算一体系统,利用FPGA解决数据墙问题,提供文件抽象简化编程,确保数据安全。适用于高效存储场景,通过动态带宽调度优化资源利用。
存算一体论文阅读之
INSIDER:Designing In-Storage Computing System for Emerging High-Performance Drive
相关代码已开源。
INSIDER
现在的瓶颈从存储驱动转移到了主存到存储器之间的互联以及IO口也就是数据墙(data movement wall)
为了解决前述问题,自然而然想到将CPU负责的计算任务pffload给各存储部分,但有一系列问题限制了应用:
(1)灵活性受限。一些嵌入式核计算能力太弱了不适合ISC,ASIC全定制设计更加限制了应用的灵活性
(2)编程的复杂性,为了适合ISC计算一方面要改代码一方面drive端还要能看懂host的意思
(3)缺少关键的系统支持。
(4)数据不受保护,可被任意读写,安全性无法得到保证。
为此本文重新定义了全栈式存储系统-INSIDER,具有以下特性;
(1)驱动速率高。使用FPGA作为ISC的控制单元保持了可变成型,流水线设计使得以下时间互相overlap:外存访问时间、村内计算时间、总线数据传输时间、主存计算时间
(2)高度抽象。使得主存端及drive端都只关注计算逻辑的描述
(3)提供必要的系统支持。将控制部分和数据部分进行了分离,控制部分是无法编程修改的,这样可提高数据访问的安全性。
Section II Related Work & Background
Part A Stroage x相关
外存由于访问时间慢作为二级存储设备来使用,带宽也比DRAM低。Bottleneck存在于: 互连的性能高于访问drive本身;IO口的一系列处理也比访问drive快。 但在过去的十年间,局面完全发生了逆转。 现在大多使用PCIe 4X接口(4 GB/s),但由于SSD结构中存在不同的通道以及bank这样的一种两级结构比起PCIe时序结构,很容易就能达到6.4GB/s,这还是没用3D堆叠技术的。 如果不解决这一“data movement wall”终端用户是不可能实现高效存储的。
Part B 存算一体相关
ISC我理解的就是host将计算的工作分发给板子上的存储器,存储器的accelerator部分负责完成一些简单的运算(如filtering/reduction).虽然没有cpu算力强但可以有效减少数据搬移的bottleneck。随后再将storage计算的结果传回给host.
ISC的概念20年前就已提出,但当时受限于两方面因素:
(1)以当时的技术架构计算单元集成到storage drive中成本高昂
;
(2)当时drive的性能比host/drive bus低的多
但现在的SSD一般都配备多个嵌入式处理器,算力的提升意味着可以将一些task offload到存储端
ISC主要用于一些用户端的任务,但仍有以下限制:
(1)存储端算力有限
(2)
编程层面抽象的不够
(3)
缺少系统支持
(1)可以看到存储端算力与host端CPU可能有100X的差距,处理数据方面可能会慢
(2)host端在编程时需要大量修改源码来平衡ISC的性能;drive端由于没有自己的file system还需要通过host FS获取数据
(3)一般SSD配备多核也为了充分利用内部带宽会同时执行多个任务,这就涉及到数据之间的保护、隔离问题
Section III INSIDER系统架构
我们从用户层到底层硬件重新设计了INSIDER的存储系统。
Part A为什么基于FPGA来设计ISC单元
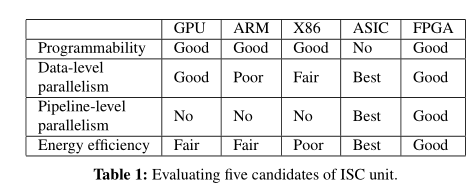
ISC UNIT要求:可重构、支持并行化计算、高能效比
比如常规存储单元耗能10W不能因为加了处理单元进去就大大增加了能耗
为了满足以上要求,本文对比了可作为ISC单元的候选方案,可以看到FPGA综合对比是最好的,尤其是在可编程方面比AISC有很大优势。
Part B 驱动设计–Drive Side
1.INSIDER整个结构如下图所示,可以看到
数据流和控制流是分开的
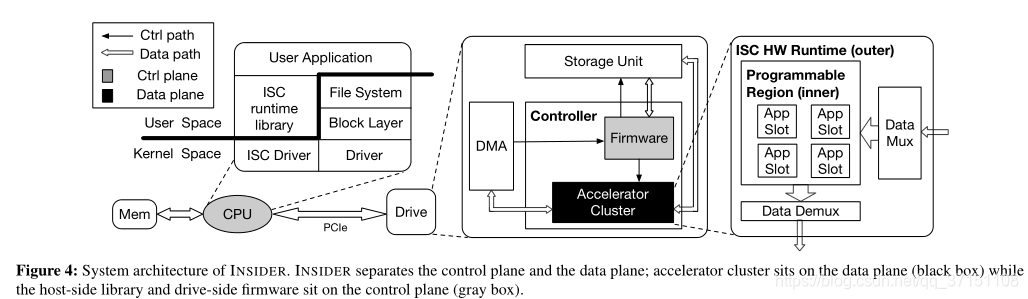
drive controller:包含逻辑固件和加速模块,其中firmware与host端的ISC通信完成控制流,接受驱动发送的请求吧逻辑地址映射为实际的物理地址上;
acclertor cluster也不负责数据的读写,而是与DMAcontroller和存储芯片沟通。
这样把数据和控制分开,控制部分还会负责权限检查以免数据的随机读取
 进一步分析Accelerator Cluster内部结构可以看到分为两层,
进一步分析Accelerator Cluster内部结构可以看到分为两层,
inner layer为可编程部分,包含很多个应用节点。每个节点可以执行一种任务的计算。与CPU的多线程不同,这是在空间上的并行,以及每一个slot的规模都有用户定义;
outer layer则是运行时的硬件,负责将数据分发到不同的slot,并且这一层用户是不可编程的。
Part C Host Side
核心是使用了virtual file abstraction,虽然是虚拟的但对于host端的用户编程时可通过API完成一系列调用。使用的是虚拟文件抽象,提供一系列文件接口,因此几乎不用改源代码。就要定义一系列接口:文件的读写。
读文件:系统开机->登录->打开文件->读文件->关闭文件
写文件:打开文件->写文件->关闭文件
Virtual File Read
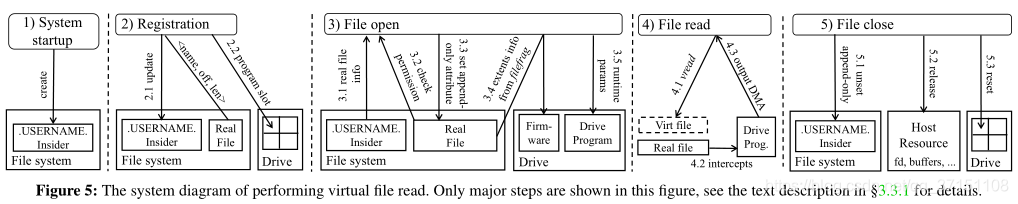
System startup:INSIDER会创建一个隐藏的映射文件(.USERNAME)用来存储虚拟的映射信息,比如将文件与对应的user关联,将文件的许可值设置为0640
Registration:host program通过访问reg_virt_file决定drive端要速去的数据,会根据mapping file通过ID找到要读取的文件\length\偏移量等。通过这种映射就可以完成离散的数据读取,映射信息也会记录到mapping file中。INSIDER的调度原则很简单:当所有的计算单元都忙的时候就block
File open:通过vopen打开文件,INSIDER首先会根据mapping file确定要打开的文件位置;然后到host端为文件系统中检索文件的权限、ownership等;如果数据访问权限正常会将对应的accelerator slot index返回给存储端;最后INSIDER会通过filefrag将真实文件的内容传输给drive端,并发送执行计算的相关参数。
Virtual File Write
Registration:首先需要用于预申请一定的空间用于写入文件内容,首先就要清除文件unwritten的标志位
File Open:文件开启过程中出了前述操作还会将一些dirty page的内容进行清除
File write:通过vwrite完成汪virtual file中写入新的内容。写入的内容通过DMA传给存储端进行相应的计算,最终的计算结果也会写入响应的block
File close:这一过程中INSIDER会丢掉读文件时的cache以保证新写入的数据可被host读到用户也能知道写入的字节数从而决定亚欧要进行ftruncate。
virtualfile write主要减轻了host->drive方向的数据传输问题,bus上传递的都是压缩后的数据
并发控制
有可能发生指令竞争,比如对同一文件同时读写;同一文件同时被不同的任务写入结果;同一文件一般被vfile读取内容同时又被host写入内容等。INSIDER采用和LINUX一样的并发性处理办法。
Drive Architecture
Drive-Side Programming Model
只描述计算逻辑,具体的数据移动都封装好了。
Input FIFO存储用于accelerator计算的数据
Output FIFO:存储accelerator计算结果供vread读。上述均以flit为基本单位
Parameter FIFO:存储host发送的一些计算参数。比如sample中的上下界,根据上下界每次从input FIFO读取响应的数据进来
系统级流水线设计
整个执行时间主要包括:drive_read+drive_compute+output_transfer+host_compute。流水线设计体现在:
drive_read、drive_compute流水执行,时间重叠;
vread\vopen等指令当drive获得真实文件地址就可以开始计算,host端可以执行别的;bus上的数据传输也通过vread进行了分离,不至于一次传输大量数据
Adaptive Bandwidth Scheduler
由于不同任务所需的并行化程度不一致,单一的任务可能不会使得drive bandwidth饱和,因此动态调度需要满足:
(1)将drive data动态分配给不同的accelerator
(2)不同的accelerator由不同的数据处理速率可以动态配置
具体实现通过一系列的credit register,根据传到存储端不同应用的请求,对于处理速度高的分配较低,然后根据分配FIFO每次进行数据的dispatchFIFO(依旧看不太懂。。。))
Section IV 实验
代码量:10K C/C++(包括源代码+HLS高级综合)
2K verilog 2K描述语言
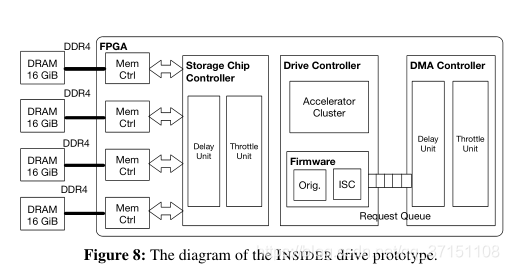
DRIVE的硬件包括:PCIe接口、storage chip controller,drive controller,DMA controller
drive controller:处理host发送要求访问drive的请求
(还没有进行wear leveling&garbage collection)
FPGA的其他资源用来实现logic
DRAM用来模拟storage chip
软件部分包括:
Complier:
Software Simulator:因为FPGA编译通常要耗时几个小时,提供C++层面orRTL层面的仿真可以将时间缩短到几十分钟
Host-side runtime library:必要时还会使用POSIC I/O来访问host file system
Linux Kernel drivers:first driver将INSIDER封装成一个常规的storage drive;second drive主要处理virtual file相关的DMA Buffer操作。
Section V Evaluation
测试的指标主要有:加速比,瓶颈分析-PCIe bandwidth
实验具体配置:
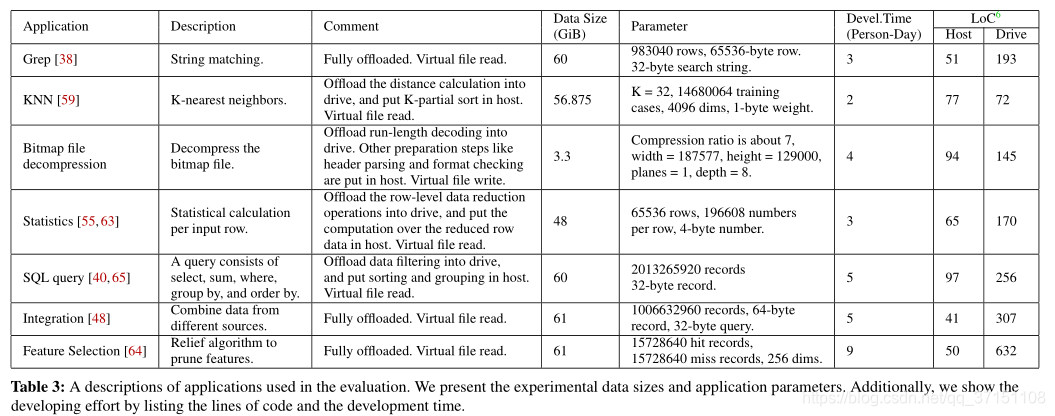
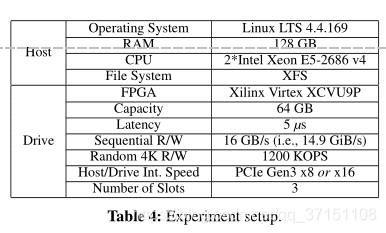 测试了以下计算:Grep,KNN,Bitmap file decompressing,Statistics,SQL Query,Integration,Feature Selection
测试了以下计算:Grep,KNN,Bitmap file decompressing,Statistics,SQL Query,Integration,Feature Selection
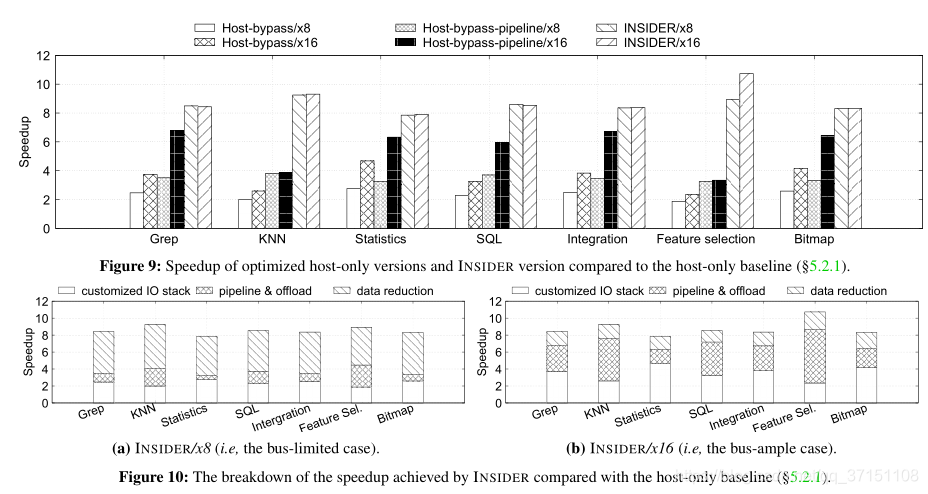
 Speed Up Bottleneck
Speed Up Bottleneck
影响加速比的因素主要有3类:
(1)I/O stack
(2)task offloading
(3)reduce data volume
当bus位宽较少时data volume是主要的bottleneck,因此需要进行数据压缩,当bus从8x->16x data compression占比减少。
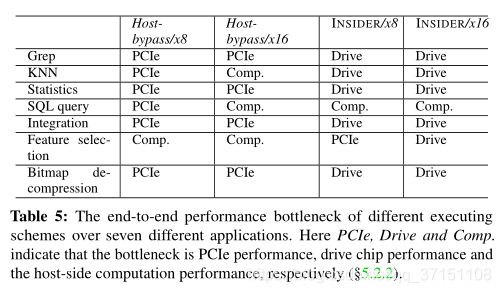
这7种应用于INSIDER架构中大部分性能取决于内部drive speed,但对于KNN ,feature selection等主要取决于host-side的计算量
编程的代价:
时间:得益于抽象文件 每一部分少于0.5h,主要时间都在development drive accelerator上
simultaneous multiprocessing
实验还测试了同时执行多任务的调度机制,实验结果如下
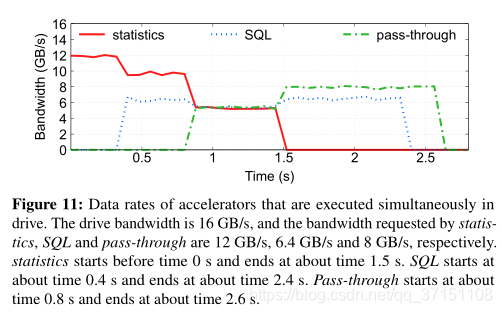 Resource Utilization
Resource Utilization
资源利用率分析
主要有:用户逻辑部分、INSIDER框架自身、IO的IP核(DMA/DRAM controller)。其中第三部分栈最多的资源,但目前成熟的存储芯片中已经有优化在此不计入资源考虑
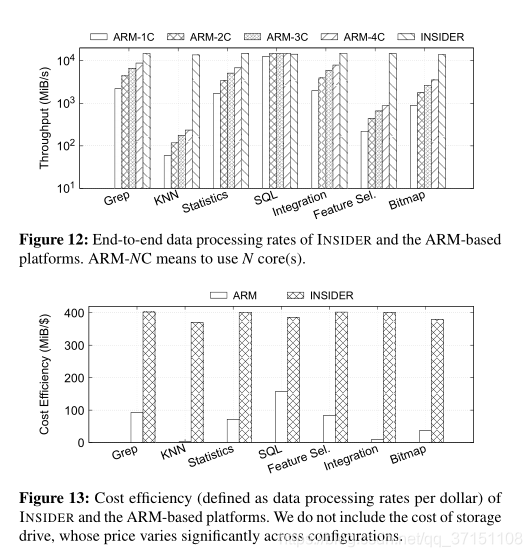
基于FPGA实现ISC还与ARM进行了对比。
对比speed up 和cost efficiency。
总结
INSIDER是一个全栈式的存储系统,性能方面有效解决了“数据墙”的问题;编程方面提供了文件抽象使得编程更加简单,同时还提供了必要的技术支持。
未来将探索将INSIDER架构应用到更多场景,比如通过RDMA/Ethernet实现云端的存算一体;另一反面现在主要是以计算为中心的计算机系统,但面临两大问题:一是通过IO进行CPU与其他设备的数据交流成本是很高的;二是CPU的速度已经跟不上IO的增长速度,因此未来本文会继续探索以数据为中心的计算机体系结构,CPU将只负责control plane,与数据相关的control下放给存储端等。

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









