







TransUNet:基于Transformer的强大特征编码器用于医学图像分割
Abstract
医学图像分割是疾病诊断、制定医疗计划的先决条件。而UNet在诸多医学图像分割任务中均取得了优异的性能,已经成为基准网络模型。但是受限于卷积操作只能学习到局部特征,UNet在进行长程关系建模时能力有限。
最初被设计用于seq2seq的Transformer模型逐渐显现出其天然的捕获长程关系的能力,缺点就是对细节信息提取能力不足。
因此本文提出了结合二者优点的TransUNet模型。一方面,取CNN提取到的feature map并序列化后的结果作为Transformer encoder的输入;另一方面decoder会上采样encoder的feature map与高分辨率的feature map相结合,从而实现精确定位。
本文认为Transformer可以作为一款强大的编码器用于提取医学图像特征,结合UNet使用可以增强细节特征从而进行精确定位。TransUNet在不同的医学图像分割任务,如多器官分割、心室分割等均取得了优异的成绩。
Section I Introduction
卷积神经网络,尤其是全卷积神经网络已经成为医学图像分割任务的主流框架。其中UNet,这样一种具有跨层连接的编码-解码网络结构可以有效的保留细节信息,成为主流的方案,在诸多分割任务,如心室分割、器官分割以及结肠镜分割中均得到了应用。
尽管基于CNN的方法显示出了优秀的特征提取能力,但是其并不擅长对长程依赖关系进行建模,主要是因为卷积操作本身的局部性。因此当目标结构在纹理、形状、大小方面表现出较大差异时CNN的性能就不会得到很好的发挥。为了解决这一问题,有的研究提出向CNN中加入self-attention机制。
另一方面,最初用于解决MLP任务的Transformer,正隐隐成为可以完全替代卷积操作的另一种通配符,Transformer是完全基于注意力机制,不仅可以充分的对上下文信息进行建模,并且在大规模数据集上晕训练后的模型可以方便的迁移到下游任务。近期越来越多的尝试正在将其应用于计算机视觉任务。
本文则首次尝试将Transformer应用于医学图像分割任务;一个有趣的实验现象是,仅仅使用transformer对输入进行编码,然后直接对提取到的feature map进行上采样,进而做密集预测,效果并不好。
主要是因为Transformer将输入视为1D序列,只关注全局信息,这样就缺失了低分辨率的特征,从而也无法进行精确的定位。而细节信息也无法通过简单的上采样恢复回去;而CNN就可以很好的提取低级特征,比如图像的细节信息。
因此,本文提出了第一个基于Transformer的医学图像分割框架——TransUNet,一方面基于seq2seq机制建立self-attention,另一方面借助CNN来弥补空间信息的丢失。因此TransUNet是结合了CNN与Transformer的混合模型,可以同时较好的处理全局信息和局部信息。
受启发于U型网络的有效性,本文也搭建了encoder-decoder结构,充分提取不同层次的feature map,并借助skip connection有效的将不同尺度的高分辨率的CNN特征进行融合,从而有助于精确的定位。
实验结果表明这种基于Transformer的分割框架比之前CNN结合self-attention的框架具有更好的分割性能;除此之外本文还发现,越丰富的低层次特征 一般会具有更好的分割性能。本文的TransUNet在诸多医学图像分割任务中取得了优异的性能。
Section II Related Works
CNN+self-attention
一个流派是尝试将self-attention与CNN结合,从而有效的对feature map的全局依赖关系进行建模,比如有的提出non-local attention,或者在skip connection中增加额外的注意力模块等。本文则是使用Transformer嵌入self-attention。
Transformers
Transformer最初用于解决MLP中的机器翻译任务,为了将Transformer适配于计算机视觉任务,Parmar等人则是对每次query的局部进行查询,而不是对全局pixel进行查询;Child等人提出Sparse Transformer则是以稀疏的思想近似计算self-attention。
ViT则是首个将Transformer用于处理图像的,将图像处理成patch序列。
据我们所知,TransUNet是第一个基于Transformer的医学图像分割框架。
Section III Method
分割任务需要完成像素级别的密集预测,即输入HWC的图像,输出H*W的分割图。常见处理方法是直接训练一个CNN先将输入编码成高级特征表述,然后在解码成原始图像分辨率的分割图。本文不同于以往的常规方法,本文用Transformer做编码,直接将self-attention嵌入其中。
Part 1 Transformer
作为Encoder
Image Sequentialization
图像序列化的方法参考ViT中的做法,将输入x展成2D patch序列,patch size = P,P的大小决定了序列长度。
Patch Embedding
首先将输入patch xp映射到D维度隐空间,并且进行positional embedding:
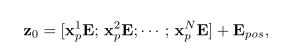
随后送入具有L层MSA和MLP的Transformer进行编码,输出表示为:
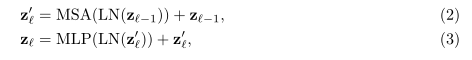
Part 2 TransUNet
为了完成分割任务,最简单的解决办法就是直接对feature map进行上采样,恢复到原始图像分辨率。 因此需要首先对HW/P^2的feature map通过上采样,在经过1x1卷积缩放到需要分割的类别,然后通过双线性插值得到最终H*W的分割图。 这种上采样恢复方式,在本文实验设置中称为"None"
尽管对Transformer处理后的结果进行上采样已经达到了一定的分割性能,但是并不是最优解,因为下采样之后的结果(H/P * W/P)往往与原始分辨率相去甚远,仅通过插值恢复到H*W中间已经丢失了许多细节信息,如器官的形状、边界信息.
因此为了弥补细节信息的丢失TransUNet采用了CNN-Transformer混合的方式进行编码,具体结构参见Fig 1.

CNN-Transformer Hybrid as Encoder
TransUnet采用CNN混合Transformer的方式作为编码器,首先用CNN作特征提取,将CNN提取的特征图谱作为Transformer的输入。patch embedding使用的是CNN提取到的featuremap 而不是原始图像中提取的1x1 patch。
这样设计使得我们可以在decoding时利用CNN提取的高分辨率特征,并且本文通过实验发现这种混合的特征提取方式比纯Transformer的特征提取效果要好。
Cascaded Upsampler
本文还使用了级联的上采样器(CUP),在上采样过程中会级联不同尺度CNN提取到的feature map,即将CNN不同分辨率的feature map reshape到合适大小,与不同的上采样层进行级联,以级联之后的结果作为改层上采样的输入。这样可以通过skip connection有效融合不同分辨率的特征。
Section IV Experiments and Discussion
Part 1 Dataset
Synapse multi-organ segmentation dataset
Automated cardiac diagnosis challenge
Part 2 Implementation Details
数据增强: 随机旋转、随机翻折
TransUNet的encoder部分:
使用ViT中的结构,包含12层Transformer layers;
CNN使用的是ResNet-50;
均取在ImageNet上预训练的结果;
输入图像大小:224
patch size:1
6
因此需要在CUP中连续级联4个Upsampler才可以恢复到原始分辨率。
实验设置:
学习率0.01
权重衰减1e-4
batch size 24
训练卡:RTX 2080Ti
对3D图像的处理:所有的3D图像以切片的方式,将2D图像堆叠在一起重建3D预测结果。
Part 3 Comparison Results
Table 1展示了对比结果,参与对比的有目前的一些SOTA网络,如V-Net,DARR,UNet,AttnUNet等。
为了说明CUP decoder的有效性,本文使用ViT作为encoder,decoder分别使用None,CUP来对比效果;为了说明混合encoder的有效性,则使用CUP作为decoder,分别使用ViT,R50-ViT作为encoder。

可以看到与ViT-None相比,ViT-CUP提升了6.36% DSC和3.5mm HD,说明了CUP的解码效果更好;而与VIT-CUP相比,R50-ViT-CUP性能分别提升了3.43%和3.24mm。
与其他CNN网络性能相比,直接使用Transformer的性能还有一定差距,主要就是Transformer不能在较好的捕获高级语义特征的同时保留低层细节信息用于精细的像素级别分割任务。
采用Transformer与CNN混合的方式,性能可以超过V-Net和DARR,但是仍然稍逊于R50-UNet和R50-AttUNet.直到最后加入skip connection性能才达到了SOTA,超过了上述所有网络结构。说明TransUNet可以同时学习到高级语义特征和底层细节特征。
Part 4分析性实验
为了进一步研究TransUNet每一部分的有效性,本文进行了一系列消融实验。进一步验证:skip connection数目的影响、输入分辨率的影响、序列长度、patch size以及模型层数的影响。
Skip connection的数目
原始UNet中,通过skip connection可以有效恢复丢失的空间信息,因此本文探究了不同skip connection数目对TransUNet性能的影响。
Fig 2展示了不同数目跨层连接对性能的影响,对所有层都使用跨层连接时性能是最好的,因此在TransUNet中也对每一层都使用了skip connection,可以看到对小尺寸器官的分割提升的更大,也验证了skip connection对细节信息的补充能力。

另一个有趣的实验是,在skip connection中使用额外的transformer并且发现这种新型的跨层连接方式会进一步提升性能。受限于GPU的内存,本文在1/8比例处加入了额外的Transformer,最终将性能提升了1.4% DSC。
Input Resolution
Table 2展示了不同输入分辨率对应的分割性能,patch size固定的情况下输入分辨率影响的是输入Transformer序列的长度,实验结果显示输入高分辨率图像确实会进一步提升性能,但却带来了更大的计算成本。因此综合考虑下本文依旧使用224的输入分辨率。

Patch size/Sequence length的影响
Table 3展示的是patch size/sequence length的影响,可以看到 patch size越小,性能越好;可以看到Transformer序列长度是与patch size的平方成反比的。

因此可以解释为:patch size越小,序列越长,Transformer可以进一步学习每个元素之间更复杂的长程依赖关系,从而鲁棒性更强。
本文patch size设置为16.
Model Scaling

本文还探究了不同网络规模对性能的影响
Base: 隐藏层维度D=12,层数=768,MLP尺寸=3072,head数目=12
Large:上述参数分别为:24,1024,4096,16
可以看到网络规模越大确实性能越好,但是结合考虑计算成本,本文依旧采用Base规模的TransUNet。

Part 5 可视化结果
Fig 3展示了一些分割结果,可以看到与其他网络模型相比,本文的TransUNet可以更好的提取全局信息,语义信息更加鲜明,而其他CNN网络则容易发生过分割或欠分割的现象。
此外,从第一行的分割结果可以看出。TransUNet的假阳更少,说明TransUNet能够更好的抑制噪声,从而进行准确的预测。
第三点,可以看到TransUNet的预测结果可以比R50-ViT-CUP更好的捕获器官的边界和形状。比如在第三行,TransUNet正确的预测了左右肾,但是R50-ViT-CUP却错误的填充了左肾的空洞;这说明TransUNet可以更好的分割、提取细节的形状信息。因为R50只能依赖于高级语义特征,而TransUNet可以同时利用高层语义特征和低层细节特征,再次阐明了借鉴UNet中skip connection结构的有效性。
Part 6模型泛化性能
为了评估TransUNet的泛化性能,还在心室分割任务中进行了实验,依旧达到了SOTA。
Section V Conclusion
Transformer是一类基于self-attentionde 网络节骨,本文首次探究了将其应用于医学图像分割任务。为了充分发挥Transformer的性能,本文建立了类似UNet的网络结构,称之为TransUNet。
不仅可以较好的提取全局语义信息,还可以有效的利用CNN提取到的低层细节信息进行精确定位。
这种CNN-Transformer的混合设计展示出了优异的性能,有望成为目前主流FCN的一种可替代方案。















 1492
1492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









