






1.摘要
医学图像分割是开发医疗保健系统,特别是疾病诊断和治疗计划的必要前提。在各种医学图像分割任务中,U形架构(也称为U-Net)已成为事实上的标准,并取得了巨大的成功。然而,由于卷积运算的内在局部性,U-Net在显式建模长程依赖性方面通常表现出局限性。Transformer是为序列间预测而设计的,它已经成为具有天生的全局自我关注机制的替代架构,但由于低级细节不足,定位能力有限。
在本文中,我们提出TransUNet作为医学图像分割的有力替代方案,它既有Transformers的优点,也有U-Net的优点。一方面,Transformer将来自卷积神经网络(CNN)特征图的标记化图像块编码为用于提取全局上下文的输入序列。另一方面,解码器对编码特征进行上采样,然后将其与高分辨率CNN特征图相结合,以实现精确定位。
我们认为Transformer可以作为医学图像分割任务的强大编码器,与U-Net相结合,通过恢复局部空间信息来增强更精细的细节。TransUNet在不同的医疗应用(包括多器官分割和心脏分割)上实现了优于各种竞争方法的性能。
2.介绍
尽管基于CNN的方法具有非凡的表示能力,但由于卷积运算的内在局部性,其在建模显式长程关系时通常表现出局限性。因此,这些结构通常产生较弱的性能,特别是对于患者之间在纹理、形状和大小方面存在较大差异的目标结构。为了克服这一限制,现有研究建议基于CNN特征建立自我注意机制。另一方面,专为序列预测而设计的Transformers已成为替代架构,它完全使用分配卷积算子,并且仅依赖于注意机制而不是Transformer。与先前基于CNN的方法不同,Transformers不仅在建模全局上下文方面具有强大的能力,而且在大规模预训练下对下游任务表现出卓越的可转移性。这一成功在机器翻译和自然语言处理(NLP)领域得到了广泛证实。最近,各种图像识别任务的尝试也达到甚至超过了最先进的水平。
在这篇论文中,提出了第一个研究,它探索了Transformer在医学图像分割背景下的潜力。然而,有趣的是,我们发现单纯的使用(即使用一个Transformer对标记化的图像补丁进行编码,然后直接对隐藏特征表示进行上采样,使其成为一个全分辨率的密集输出)不能产生令人满意的结果。
这是由于transformer将输入视为1D序列,专注于各个阶段的全局上下文建模,因此导致低分辨率的特征缺乏详细的定位信息。而这些信息不能通过直接上采样到全分辨率有效恢复,因此导致分割结果粗糙。另一方面,CNN体系结构(例如U-Net)提供了一种提取低级视觉线索的途径,可以很好地弥补这些细微的空间细节。
为此,我们提出了首个医学图像分割框架TransUNet,该框架从序列到序列预测的角度建立了自注意机制。为了弥补transformer带来的特征分辨率损失,TransUNet采用了一种混合的CNN- transformer架构,利用来自CNN特征的详细高分辨率空间信息和transformer编码的全局上下文。受u型建筑设计的启发,Transformer Encoder的自关注特征图被上采样,与编码路径上shortcut的不同高分辨率CNN特征相结合,实现精确定位。我们证明,这样的设计允许我们的框架保持变压器的优点,也有利于医学图像分割。经验结果表明,与之前的基于cnn的自注意方法相比,我们基于transformer的体系结构提供了更好的利用自注意的方法。此外,我们观察到更密集的低层特征合并通常会导致更好的分割精度。大量的实验证明了该方法在各种医学图像分割任务中的优越性。
给定图像H×W ×C,空间分辨率为H×W,通道数为C。我们的目标是预测相应的大小为H × W的像素级标签映射。最常见的方法是直接训练CNN(例如UNet),首先将图像编码为高级特征表示,然后将其解码回全空间分辨率。与现有的方法不同,我们的方法通过使用变压器在编码器设计中引入了自我注意机制。
3.网络结构
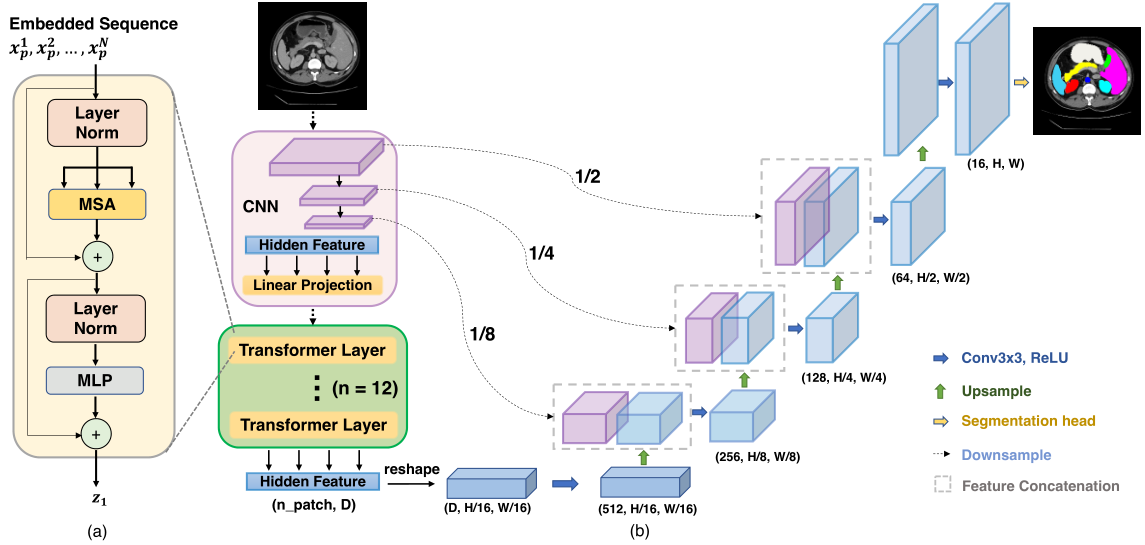
整个TransUNet的网络结构如图上所示,其实挺容易理解的。
1)首先输入一个CT图像,如果图像是单通道的就通过repeat函数复制两次,将通道扩充为三通道的。
2)将三通道图像[B,3,224,224]]通过ResNetV2进行下采样,将图像编码为高级特征表示。然后创建一个feature列表将每个下采样后的特征图保存下来。最后经过ResNetV2网络输出[B,16C,14,14]。C=64 x widthfactor。feature列表包含三个尺寸大小的特征图,分别是[B,C,112,112],[B,4C,56,56],[B,8C,28,28]。
具体ResNetV2的结构:先使用卷积核7x7,s=2,p=3的卷积操作进行root下采样为[B,C,112,112],然后通过maxpooling层下采样为[B,C,56,56]。最后就通过三个block下采样,输出特征图。
3)先对下采样后的特征图[B,16C,14,14]进行embedding,
利用卷积核大小为patch_size x patch_size,s=patch_size将图像切成一个个patch,得到[B,hidden_channel,num_patches],num_patches=(14/patch_size)**2。然后reshape为[B,n_p,h_c]。加入position embedding=[1,n_p,h_c]。最终得到输出特征图[B,n_p,h_c]。
4)Transformer Encoder。这步没什么说的,就是大家非常熟悉的Transformer,计算自注意力。输出[B,n_p,h_c]。
5)Decoder。先将[B,n_p,h_c]reshape为[B,h_c,根号下n_p,根号下n_p]。然后Conv2d为[B,512,14,14]。然后通过四个decoder最后输出[B,32,224,224]。
decoder为先通过双线性上采样来使特征图尺寸扩大一倍,然后与之前卷积后shortcut的feature进行concat,最后通过两个Conv2d将特征图映射到低维空间。
6)SegmentationHead。将网络输出的特征图进行分割,通过Conv2d输出[B,n_classes,224,224]
4.TransUNet网络全部代码
下方代码为除了ResNetV2之外的全部代码。
# coding=utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import copy
import logging
import math
from os.path import join as pjoin
import torch
import torch.nn as nn
import numpy as np
from torch.nn import CrossEntropyLoss, Dropout, Softmax, Linear, Conv2d, LayerNorm
from torch.nn.modules.utils import _pair
from scipy import ndimage
from . import vit_seg_configs as configs
from .vit_seg_modeling_resnet_skip import ResNetV2
logger = logging.getLogger(__name__)
ATTENTION_Q = "MultiHeadDotProductAttention_1/query"
ATTENTION_K = "MultiHeadDotProductAttention_1/key"
ATTENTION_V = "MultiHeadDotProductAttention_1/value"
ATTENTION_OUT = "MultiHeadDotProductAttention_1/out"
FC_0 = "MlpBlock_3/Dense_0"
FC_1 = "MlpBlock_3/Dense_1"
ATTENTION_NORM = "LayerNorm_0"
MLP_NORM = "LayerNorm_2"
def np2th(weights, conv=False):
"""Possibly convert HWIO to OIHW."""
if conv:
weights = weights.transpose([3, 2, 0, 1])
return torch.from_numpy(weights)
# sigmoid激活函数
def swish(x):
return x * torch.sigmoid(x)
# 激活函数的选择
ACT2FN = {"gelu": torch.nn.functional.gelu, "relu": torch.nn.functional.relu, "swish": swish}
class Attention(nn.Module):
def __init__(self, config, vis):
super(Attention, self).__init__()
self.vis = vis
self.num_attention_heads = config.transformer["num_heads"]
self.attention_head_size = int(config.hidden_size / self.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
# 线性层得到q、k、v向量
self.query = Linear(config.hidden_size, self.all_head_size)
self.key = Linear(config.hidden_size, self.all_head_size)
self.value = Linear(config.hidden_size, self.all_head_size)
self.out = Linear(config.hidden_size, config.hidden_size)
self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.softmax = Softmax(dim=-1)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
# 线性层得到q、k、v矩阵
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# q乘k的转置
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
# 除以根号下d
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# 进行softmax
attention_probs = self.softmax(attention_scores)
weights = attention_probs if self.vis else None
attention_probs = self.attn_dropout(attention_probs)
# 乘以v矩阵
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
# 映射层
attention_output = self.out(context_layer)
attention_output = self.proj_dropout(attention_output)
return attention_output, weights
class Mlp(nn.Module):
def __init__(self, config):
super(Mlp, self).__init__()
self.fc1 = Linear(config.hidden_size, config.transformer["mlp_dim"])
self.fc2 = Linear(config.transformer["mlp_dim"], config.hidden_size)
self.act_fn = ACT2FN["gelu"]
self.dropout = Dropout(config.transformer["dropout_rate"])
self._init_weights()
def _init_weights(self):
nn.init.xavier_uniform_(self.fc1.weight)
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.normal_(self.fc1.bias, std=1e-6)
nn.init.normal_(self.fc2.bias, std=1e-6)
def forward(self, x):
x = self.fc1(x)
x = self.act_fn(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class Embeddings(nn.Module):
"""Construct the embeddings from patch, position embeddings.
"""
def __init__(self, config, img_size, in_channels=3):
super(Embeddings, self).__init__()
self.hybrid = None
self.config = config
img_size = _pair(img_size)
if config.patches.get("grid") is not None: # ResNet
grid_size = config.patches["grid"]
patch_size = (img_size[0] // 16 // grid_size[0], img_size[1] // 16 // grid_size[1])
patch_size_real = (patch_size[0] * 16, patch_size[1] * 16)
n_patches = (img_size[0] // patch_size_real[0]) * (img_size[1] // patch_size_real[1])
self.hybrid = True
else:
patch_size = _pair(config.patches["size"])
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])
self.hybrid = False
if self.hybrid:
self.hybrid_model = ResNetV2(block_units=config.resnet.num_layers, width_factor=config.resnet.width_factor)
in_channels = self.hybrid_model.width * 16
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=patch_size,
stride=patch_size)
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, config.hidden_size))
self.dropout = Dropout(config.transformer["dropout_rate"])
def forward(self, x):
if self.hybrid:
x, features = self.hybrid_model(x)
else:
features = None
# [B,16C,14,14]
x = self.patch_embeddings(x) # (B, hidden. n_patches^(1/2), n_patches^(1/2))
x = x.flatten(2) # (B, hidden, n_patches)
x = x.transpose(-1, -2) # (B, n_patches, hidden)
embeddings = x + self.position_embeddings
embeddings = self.dropout(embeddings)
return embeddings, features
class Block(nn.Module):
def __init__(self, config, vis):
super(Block, self).__init__()
self.hidden_size = config.hidden_size
self.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn = Mlp(config)
self.attn = Attention(config, vis)
def forward(self, x):
h = x
x = self.attention_norm(x)
x, weights = self.attn(x)
x = x + h
h = x
x = self.ffn_norm(x)
x = self.ffn(x)
x = x + h
return x, weights
def load_from(self, weights, n_block):
ROOT = f"Transformer/encoderblock_{n_block}"
with torch.no_grad():
query_weight = np2th(weights[pjoin(ROOT, ATTENTION_Q, "kernel")]).view(self.hidden_size, self.hidden_size).t()
key_weight = np2th(weights[pjoin(ROOT, ATTENTION_K, "kernel")]).view(self.hidden_size, self.hidden_size).t()
value_weight = np2th(weights[pjoin(ROOT, ATTENTION_V, "kernel")]).view(self.hidden_size, self.hidden_size).t()
out_weight = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "kernel")]).view(self.hidden_size, self.hidden_size).t()
query_bias = np2th(weights[pjoin(ROOT, ATTENTION_Q, "bias")]).view(-1)
key_bias = np2th(weights[pjoin(ROOT, ATTENTION_K, "bias")]).view(-1)
value_bias = np2th(weights[pjoin(ROOT, ATTENTION_V, "bias")]).view(-1)
out_bias = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "bias")]).view(-1)
self.attn.query.weight.copy_(query_weight)
self.attn.key.weight.copy_(key_weight)
self.attn.value.weight.copy_(value_weight)
self.attn.out.weight.copy_(out_weight)
self.attn.query.bias.copy_(query_bias)
self.attn.key.bias.copy_(key_bias)
self.attn.value.bias.copy_(value_bias)
self.attn.out.bias.copy_(out_bias)
mlp_weight_0 = np2th(weights[pjoin(ROOT, FC_0, "kernel")]).t()
mlp_weight_1 = np2th(weights[pjoin(ROOT, FC_1, "kernel")]).t()
mlp_bias_0 = np2th(weights[pjoin(ROOT, FC_0, "bias")]).t()
mlp_bias_1 = np2th(weights[pjoin(ROOT, FC_1, "bias")]).t()
self.ffn.fc1.weight.copy_(mlp_weight_0)
self.ffn.fc2.weight.copy_(mlp_weight_1)
self.ffn.fc1.bias.copy_(mlp_bias_0)
self.ffn.fc2.bias.copy_(mlp_bias_1)
self.attention_norm.weight.copy_(np2th(weights[pjoin(ROOT, ATTENTION_NORM, "scale")]))
self.attention_norm.bias.copy_(np2th(weights[pjoin(ROOT, ATTENTION_NORM, "bias")]))
self.ffn_norm.weight.copy_(np2th(weights[pjoin(ROOT, MLP_NORM, "scale")]))
self.ffn_norm.bias.copy_(np2th(weights[pjoin(ROOT, MLP_NORM, "bias")]))
class Encoder(nn.Module):
def __init__(self, config, vis):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)
for _ in range(config.transformer["num_layers"]):
layer = Block(config, vis)
self.layer.append(copy.deepcopy(layer))
def forward(self, hidden_states):
attn_weights = []
# 依次经过几个Block
for layer_block in self.layer:
hidden_states, weights = layer_block(hidden_states)
if self.vis:
attn_weights.append(weights)
encoded = self.encoder_norm(hidden_states)
return encoded, attn_weights
class Transformer(nn.Module):
def __init__(self, config, img_size, vis):
super(Transformer, self).__init__()
self.embeddings = Embeddings(config, img_size=img_size)
self.encoder = Encoder(config, vis)
def forward(self, input_ids):
embedding_output, features = self.embeddings(input_ids)
encoded, attn_weights = self.encoder(embedding_output) # (B, n_patch, hidden)
return encoded, attn_weights, features
class Conv2dReLU(nn.Sequential):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
padding=0,
stride=1,
use_batchnorm=True,
):
conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
bias=not (use_batchnorm),
)
relu = nn.ReLU(inplace=True)
bn = nn.BatchNorm2d(out_channels)
super(Conv2dReLU, self).__init__(conv, bn, relu)
class DecoderBlock(nn.Module):
def __init__(
self,
in_channels,
out_channels,
skip_channels=0,
use_batchnorm=True,
):
super().__init__()
self.conv1 = Conv2dReLU(
in_channels + skip_channels,
out_channels,
kernel_size=3,
padding=1,
use_batchnorm=use_batchnorm,
)
self.conv2 = Conv2dReLU(
out_channels,
out_channels,
kernel_size=3,
padding=1,
use_batchnorm=use_batchnorm,
)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x, skip=None):
x = self.up(x)
if skip is not None:
x = torch.cat([x, skip], dim=1)
x = self.conv1(x)
x = self.conv2(x)
return x
class SegmentationHead(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, upsampling=1):
conv2d = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=kernel_size // 2)
upsampling = nn.UpsamplingBilinear2d(scale_factor=upsampling) if upsampling > 1 else nn.Identity()
super().__init__(conv2d, upsampling)
class DecoderCup(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
head_channels = 512
self.conv_more = Conv2dReLU(
config.hidden_size,
head_channels,
kernel_size=3,
padding=1,
use_batchnorm=True,
)
decoder_channels = config.decoder_channels
in_channels = [head_channels] + list(decoder_channels[:-1])
out_channels = decoder_channels
if self.config.n_skip != 0:
skip_channels = self.config.skip_channels
for i in range(4-self.config.n_skip): # re-select the skip channels according to n_skip
skip_channels[3-i]=0
else:
skip_channels=[0,0,0,0]
blocks = [
DecoderBlock(in_ch, out_ch, sk_ch) for in_ch, out_ch, sk_ch in zip(in_channels, out_channels, skip_channels)
]
self.blocks = nn.ModuleList(blocks)
def forward(self, hidden_states, features=None):
B, n_patch, hidden = hidden_states.size() # reshape from (B, n_patch, hidden) to (B, h, w, hidden)
h, w = int(np.sqrt(n_patch)), int(np.sqrt(n_patch))
x = hidden_states.permute(0, 2, 1)
x = x.contiguous().view(B, hidden, h, w)
x = self.conv_more(x)
for i, decoder_block in enumerate(self.blocks):
if features is not None:
skip = features[i] if (i < self.config.n_skip) else None
else:
skip = None
x = decoder_block(x, skip=skip)
return x
class VisionTransformer(nn.Module):
def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.zero_head = zero_head
self.classifier = config.classifier
self.transformer = Transformer(config, img_size, vis)
self.decoder = DecoderCup(config)
self.segmentation_head = SegmentationHead(
in_channels=config['decoder_channels'][-1],
out_channels=config['n_classes'],
kernel_size=3,
)
self.config = config
def forward(self, x):
# [B,C,H,W],当图片为单通道[B,1,H,W]时,将通道数复制三次得到[B,3,H,W]
if x.size()[1] == 1:
# repeat的参数是对应维度的复制个数,参数为(2,2)时,0维复制两次,1维复制两次
x = x.repeat(1,3,1,1)
x, attn_weights, features = self.transformer(x) # (B, n_patch, hidden)
x = self.decoder(x, features) # [B,16,H,W]
logits = self.segmentation_head(x)
return logits
def load_from(self, weights):
with torch.no_grad():
res_weight = weights
self.transformer.embeddings.patch_embeddings.weight.copy_(np2th(weights["embedding/kernel"], conv=True))
self.transformer.embeddings.patch_embeddings.bias.copy_(np2th(weights["embedding/bias"]))
self.transformer.encoder.encoder_norm.weight.copy_(np2th(weights["Transformer/encoder_norm/scale"]))
self.transformer.encoder.encoder_norm.bias.copy_(np2th(weights["Transformer/encoder_norm/bias"]))
posemb = np2th(weights["Transformer/posembed_input/pos_embedding"])
posemb_new = self.transformer.embeddings.position_embeddings
if posemb.size() == posemb_new.size():
self.transformer.embeddings.position_embeddings.copy_(posemb)
elif posemb.size()[1]-1 == posemb_new.size()[1]:
posemb = posemb[:, 1:]
self.transformer.embeddings.position_embeddings.copy_(posemb)
else:
logger.info("load_pretrained: resized variant: %s to %s" % (posemb.size(), posemb_new.size()))
ntok_new = posemb_new.size(1)
if self.classifier == "seg":
_, posemb_grid = posemb[:, :1], posemb[0, 1:]
gs_old = int(np.sqrt(len(posemb_grid)))
gs_new = int(np.sqrt(ntok_new))
print('load_pretrained: grid-size from %s to %s' % (gs_old, gs_new))
posemb_grid = posemb_grid.reshape(gs_old, gs_old, -1)
zoom = (gs_new / gs_old, gs_new / gs_old, 1)
posemb_grid = ndimage.zoom(posemb_grid, zoom, order=1) # th2np
posemb_grid = posemb_grid.reshape(1, gs_new * gs_new, -1)
posemb = posemb_grid
self.transformer.embeddings.position_embeddings.copy_(np2th(posemb))
# Encoder whole
for bname, block in self.transformer.encoder.named_children():
for uname, unit in block.named_children():
unit.load_from(weights, n_block=uname)
if self.transformer.embeddings.hybrid:
self.transformer.embeddings.hybrid_model.root.conv.weight.copy_(np2th(res_weight["conv_root/kernel"], conv=True))
gn_weight = np2th(res_weight["gn_root/scale"]).view(-1)
gn_bias = np2th(res_weight["gn_root/bias"]).view(-1)
self.transformer.embeddings.hybrid_model.root.gn.weight.copy_(gn_weight)
self.transformer.embeddings.hybrid_model.root.gn.bias.copy_(gn_bias)
for bname, block in self.transformer.embeddings.hybrid_model.body.named_children():
for uname, unit in block.named_children():
unit.load_from(res_weight, n_block=bname, n_unit=uname)
CONFIGS = {
'ViT-B_16': configs.get_b16_config(),
'ViT-B_32': configs.get_b32_config(),
'ViT-L_16': configs.get_l16_config(),
'ViT-L_32': configs.get_l32_config(),
'ViT-H_14': configs.get_h14_config(),
'R50-ViT-B_16': configs.get_r50_b16_config(),
'R50-ViT-L_16': configs.get_r50_l16_config(),
'testing': configs.get_testing(),
}
下方代码为ResNetV2的网络结构
import math
from os.path import join as pjoin
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
def np2th(weights, conv=False):
"""Possibly convert HWIO to OIHW."""
if conv:
weights = weights.transpose([3, 2, 0, 1])
return torch.from_numpy(weights)
class StdConv2d(nn.Conv2d):
def forward(self, x):
w = self.weight
v, m = torch.var_mean(w, dim=[1, 2, 3], keepdim=True, unbiased=False)
w = (w - m) / torch.sqrt(v + 1e-5)
return F.conv2d(x, w, self.bias, self.stride, self.padding,
self.dilation, self.groups)
def conv3x3(cin, cout, stride=1, groups=1, bias=False):
return StdConv2d(cin, cout, kernel_size=3, stride=stride,
padding=1, bias=bias, groups=groups)
def conv1x1(cin, cout, stride=1, bias=False):
return StdConv2d(cin, cout, kernel_size=1, stride=stride,
padding=0, bias=bias)
class PreActBottleneck(nn.Module):
"""Pre-activation (v2) bottleneck block.
"""
def __init__(self, cin, cout=None, cmid=None, stride=1):
super().__init__()
cout = cout or cin
cmid = cmid or cout//4
self.gn1 = nn.GroupNorm(32, cmid, eps=1e-6)
self.conv1 = conv1x1(cin, cmid, bias=False)
self.gn2 = nn.GroupNorm(32, cmid, eps=1e-6)
self.conv2 = conv3x3(cmid, cmid, stride, bias=False) # Original code has it on conv1!!
self.gn3 = nn.GroupNorm(32, cout, eps=1e-6)
self.conv3 = conv1x1(cmid, cout, bias=False)
self.relu = nn.ReLU(inplace=True)
if (stride != 1 or cin != cout):
# Projection also with pre-activation according to paper.
self.downsample = conv1x1(cin, cout, stride, bias=False)
self.gn_proj = nn.GroupNorm(cout, cout)
def forward(self, x):
# Residual branch
residual = x
# 是否有下采样模块
if hasattr(self, 'downsample'):
residual = self.downsample(x)
residual = self.gn_proj(residual)
# Unit's branch
y = self.relu(self.gn1(self.conv1(x)))
y = self.relu(self.gn2(self.conv2(y)))
y = self.gn3(self.conv3(y))
y = self.relu(residual + y)
return y
def load_from(self, weights, n_block, n_unit):
conv1_weight = np2th(weights[pjoin(n_block, n_unit, "conv1/kernel")], conv=True)
conv2_weight = np2th(weights[pjoin(n_block, n_unit, "conv2/kernel")], conv=True)
conv3_weight = np2th(weights[pjoin(n_block, n_unit, "conv3/kernel")], conv=True)
gn1_weight = np2th(weights[pjoin(n_block, n_unit, "gn1/scale")])
gn1_bias = np2th(weights[pjoin(n_block, n_unit, "gn1/bias")])
gn2_weight = np2th(weights[pjoin(n_block, n_unit, "gn2/scale")])
gn2_bias = np2th(weights[pjoin(n_block, n_unit, "gn2/bias")])
gn3_weight = np2th(weights[pjoin(n_block, n_unit, "gn3/scale")])
gn3_bias = np2th(weights[pjoin(n_block, n_unit, "gn3/bias")])
self.conv1.weight.copy_(conv1_weight)
self.conv2.weight.copy_(conv2_weight)
self.conv3.weight.copy_(conv3_weight)
self.gn1.weight.copy_(gn1_weight.view(-1))
self.gn1.bias.copy_(gn1_bias.view(-1))
self.gn2.weight.copy_(gn2_weight.view(-1))
self.gn2.bias.copy_(gn2_bias.view(-1))
self.gn3.weight.copy_(gn3_weight.view(-1))
self.gn3.bias.copy_(gn3_bias.view(-1))
if hasattr(self, 'downsample'):
proj_conv_weight = np2th(weights[pjoin(n_block, n_unit, "conv_proj/kernel")], conv=True)
proj_gn_weight = np2th(weights[pjoin(n_block, n_unit, "gn_proj/scale")])
proj_gn_bias = np2th(weights[pjoin(n_block, n_unit, "gn_proj/bias")])
self.downsample.weight.copy_(proj_conv_weight)
self.gn_proj.weight.copy_(proj_gn_weight.view(-1))
self.gn_proj.bias.copy_(proj_gn_bias.view(-1))
class ResNetV2(nn.Module):
"""Implementation of Pre-activation (v2) ResNet mode."""
def __init__(self, block_units, width_factor):
super().__init__()
width = int(64 * width_factor)
self.width = width
self.root = nn.Sequential(OrderedDict([
('conv', StdConv2d(3, width, kernel_size=7, stride=2, bias=False, padding=3)),
('gn', nn.GroupNorm(32, width, eps=1e-6)),
('relu', nn.ReLU(inplace=True)),
# ('pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=0))
]))
# [B,C,55,55]
self.body = nn.Sequential(OrderedDict([
('block1', nn.Sequential(OrderedDict(
[('unit1', PreActBottleneck(cin=width, cout=width*4, cmid=width))] +
[(f'unit{i:d}', PreActBottleneck(cin=width*4, cout=width*4, cmid=width)) for i in range(2, block_units[0] + 1)],
))),
('block2', nn.Sequential(OrderedDict(
[('unit1', PreActBottleneck(cin=width*4, cout=width*8, cmid=width*2, stride=2))] +
[(f'unit{i:d}', PreActBottleneck(cin=width*8, cout=width*8, cmid=width*2)) for i in range(2, block_units[1] + 1)],
))),
('block3', nn.Sequential(OrderedDict(
[('unit1', PreActBottleneck(cin=width*8, cout=width*16, cmid=width*4, stride=2))] +
[(f'unit{i:d}', PreActBottleneck(cin=width*16, cout=width*16, cmid=width*4)) for i in range(2, block_units[2] + 1)],
))),
]))
def forward(self, x):
# [B,3,224,224]
features = []
b, c, in_size, _ = x.size()
x = self.root(x) # [B,C,112,112]
features.append(x)
x = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)(x) # [B,C,55,55]
for i in range(len(self.body)-1):
x = self.body[i](x)
right_size = int(in_size / 4 / (i+1))
if x.size()[2] != right_size:
pad = right_size - x.size()[2]
assert pad < 3 and pad > 0, "x {} should {}".format(x.size(), right_size)
feat = torch.zeros((b, x.size()[1], right_size, right_size), device=x.device)
feat[:, :, 0:x.size()[2], 0:x.size()[3]] = x[:]
else:
feat = x
features.append(feat)
x = self.body[-1](x) # [B,16C,14,14]
return x, features[::-1]


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









