







Patches are All you Need
Abstract
ICLR2022 Under Review
Paper
Code
虽然CNN多年来一直作为视觉任务的主流框架,近期的实验表明基于Transformer的模型,尤其是ViT在某些任务上已经超过了CNN。但是由于SA计算时的指数复杂度,ViT需要进行patch embedding,并将patch组合在一起,将一小部分图像区域变成单一的输入特征,然后组成整张图的序列表示。这就自然而然引出一个问题:ViT的优异性能到底是由于Transformer的强大还是由于使用patch作为输入导致的呢?
本文给出了倾向于后者的一些证据;此外本文还提出了ConvMixer,一种极简的模型,与基本的MLP-Mixer更相似,取patcher作为输入,然后将空间与通道维度分开,整个网络保持输入的分辨率。
但是ConvMixer只使用标准卷积操作实现混合操作,尽管ConvMixer很简单,但是本文证明了它的性能优于ViT,MLP-Mixer以及其他一些变体,也优于一些传统的视觉模型,如ResNet。
Section I Introduction
多年来卷积神经网络一直作为计算机视觉任务中的主流深度学习框架,近期基于Transformer的架构在许多任务中展现了引人注目的表现,尤其在大数据及上通常优于经典的卷积神经网络。因此Transformer成为主流框架可能只是一个时间问题。
但是SA计算复杂度限制了将Transformer应用于图像,因为输入的像素量随着分辨率指数增长,切的patch也会越来越多,整个序列也会越来越长。
本文探讨的问题就是,ViT强大的性能到底来源于Transformer结构本身还是源于这是基于patch的表示。本文设计了一个非常简单的卷积结构-ConvMixer,在许多方面和ViT也和MLPMixer比较类似:直接作用在patch上,在所有层中保持相同的分辨率和大小,在连续层中不进行下采样操作,不同channel、空间之间是独立的。区别就是本文所有的都是基于标准卷积完成的。
本文的主要结论是,ConvMixer尽管结构十分简单,在Pytorch中仅6行皆可以实现,但其性能却优于两个参数量相似的标准的计算机视觉模型,如ResNet和MLP-Mixer的变体。重要的是本文并没有进行额外的设计来追求准确性或速度,这与我们比较的其他模型形成了鲜明对比。
实验究结果表明,至少在某种程度上,基于patch的输入可能是Vision Transformer性能优越的关键原因,尽管这些结果只是一个snapshot,仍然需要更多的实验来进一步分析patch embedding和其他因素的影响,但是本文相信提供了一个强大的基于patch的卷积模型,以便与未来更先进的架构进行比较。
Section II A simple Model: ConvMixer
本文的模型称为ConvMixer,包括一个patch embedding层,后面重复一个简单的全连接模块(Conv-Mixer层)。
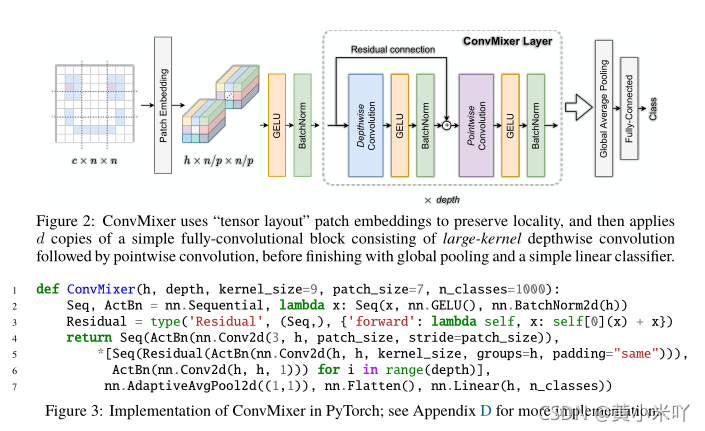
Patch embedding可以通过步长卷积实现,输入通道Cin,输出通道h,步长和卷积核均为patch-size§。从而得到h x (n/p) x (n/p)大小的feature map;
Conv-Mixer层:使用的是1x1卷积和深度卷积,深度卷积就是分组卷积的组数=h。卷积后还会进行激活和BN。
迭代足够深度后,会用全局池化得到一个大小为h的特征向量,然后进行softmax。
Fig 3展示了ConvMixer的Pytorch实现。
ConvMixer的参数包括:
隐藏层的宽度(即patch embedding的维度)
CinvMixer重复的次数-d
patch-size p 来决定模型内部的分辨率
深度卷积的核大小-k
本文的想法来自于MLP-Mixer。
本文使用深度卷积来混合空间信息,使用point-wise convolution来进行通道混合。MLP-Mixer的核心思想是MLP和SA可以混合遥远的空间位置,这样就可以具有任意大小的感受野;因此本文使用异常大的卷积核来混合遥远的空间位置。
虽然SA和MLP理论上更加灵活,感受范围更大,但是卷积的归纳偏执更适合视觉任务,其数据效率也更高。
通过这样的标准操作,本文还可以看到patch本身的作用,可以与金字塔形网络、卷积中的下采样操作作对比。
Section III Experiments
Training Setup
直接在ImageNet-1K上进行验证,不经过任何预训练。
还使用了随机增强
优化器AdamW
没有进行任何超参调整,训练epoch也更少,因此本文模型可能会过度或未充分正则化,因此实验的精度可能比实际更低。
实验结果
参数量为52M的ConvMixer在ImageNet上达到了81.4%的top-1精度
21M–80.2%的top-1精度
ConvMixer越宽收敛的越早,但是对内存需求也更大;
kernel-size也是越大越好,kernel-size从9减少为3时精度会掉1%
以及patsh-size越小 在实验中效果更好,本文认为更大的patch需要更深的ConvMixer
patch-sizec从7增加到14后精度为78.9%但是速度提升了4X。
此外本文还证明了DELU并不是100%必要的,本文使用RELU训练的模型效果也不错。
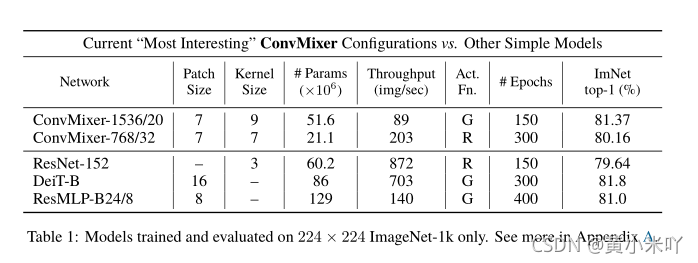
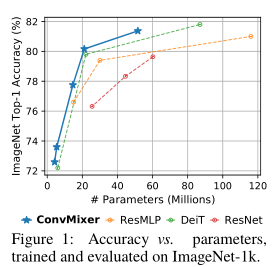
其他对比结果参见Table 1和Fig 1。
Comparisons
本文的训练方法与DeiT比较类似,鉴于ConvMixer本身结构就十分简单,本文专注于其他在ImageNet-1K上也比较基本的基于patch的架构进行对比,即DeiT和ResMLP。
为了对比的公平性,本文使用ResNet与ConvMixer有相同的参数,鉴于这种设计对ResNet是次优的,也可能对ConvMixer是次优的,因此本文没有进行任何超参数调优。
从Table 1可以看到在参数相近的情况下ConvMixer的精度十分具有竞争力,ConvMixer-1536/20优于ResNet-152和ResMLP-B24,尽管它们具有较少的参数,并且与DeiT-B具有竞争力。
ConvMixer-768/32只使用了ResNet-152参数的三分之一,但同样准确。
请注意的是,与ConvMixer不同,DeiT和ResMLP结果涉及超参数调优。同时训练时间更久,但仅比COnvMixer精度提升0.2%.
但是COnvMixer推理时间更久,可能是因为patch-size更小,通过超参数调优可以缩小这一差距
。
此外本文还在更小规模的CIFAR-10上进行了实验,ConvMixer在参数量仅有0.7M时精度超过了96%.
Section IV Related Work
Isotropic Architecture
ViT激起了研究“各向同性”的新范式,即整个网络中使用同样大小和尺寸的输入,在第一层使用patch embedding来实现。这些模型像ViT一样,会不断重复Transformer模块,以及使用一些其他的操作代替SA以及MLP操作。
比如MLP-Mixer将替换为MLP,并进行通道和空间的混合;ResMLP则是类似的思路但是更加data-efficient.
CycleMLP,gMLP以及Vision permutator则是将SA和MLP操作替换为其他操作。
在Kytiazi的研究中提出了一个基于MLP的各向同性的视觉模型,并且任务patch embedding可能才是性能提升的真正原因;ResMLP将线性层替换为卷积核更小的卷积操作后性能也获得了提升,但是它保留了通道混合层,也没有进一步探索使用卷积的效果。
根据本文的研究表明,前人的这些工作取得的提升,可能将patch embedding与工作中提出的新操作起到的作用混到了一起。
之前也有研究搭建了各向同性的MobileNetv3模型,也实现了patch emebdding操作,只不过当时还不叫这个名字。这篇工作的实验结果也与我们的实验观察结果吻合,只不过他们的基本模块比我们的复杂的多。
Patches aren’t all you need
也有的工作通过将patch embedding替换为其他操作提升了ViT的心梗,比如使用卷积操作或者结合周围patch的信息进行嵌入。但是也是将使用patch embedding的效果与添加卷积或其他操作的作用混在了一起,本文则专注于研究patch的作用。
CNNs meet ViTs
研究者们已经在将卷积网络的特征融合进Transformer方面做了诸多探索。比如将SA进行卷积能类似的初始化或正则化,以及向Transformer中添加卷积操作,或者搭建金字塔形网络。
此外也有的探索将类似SA的注意力来补充或替换ResNet中的卷积操作,这些工作都取得了这样那样的成功,但是都与本文的工作内容正交,本文强调的是搭建一个表征能力较弱得到网络来聚焦patch embedding的作用。
Section V Conclusion
本文提出的ConvMixer是一种极简的模型,只使用了标准卷积,patch embedding以及进行了空间混合、通道混合。本文还受到ViT和MLP-Mixer大感受野的启发,使用大的卷积核可以获得实质性的性能提升。
本文并没有特别的进行超参调整来提升精度或速度,但表现的结果已经超过了ViT和MLP-Mixer,可以与ResNet,Deit等相媲美。
本文的实验结果表明搭建各向同性的网络同时结合patch embedding就是一种强大的DL模板。patch embedding使得降采样操作一次完成,使得中间分辨率极具下降,这样可以有效提升感受野,也使得长程信息的混合更加容易。
本文的标题虽然有点夸张,但它表明注意力并不是从语言处理到CV迁移的唯一有效的地方,表计划、patch embedding也是一种强大且有效的方式。
虽然本文的模型并不是SOTA,但是其patch-mixing操作十分有吸引力。
本文希望ConvMixer可以作为一种基于patch的基准架构,护着为新的模型提供一种基础模板。
Future Work
本文对这种观点持乐观态度,即得到充分训练、正则化以及调参后,具备更大patch、更深的Mixer可以更好的权衡精度、参数量、吞吐量。比如使用更大的卷积核可以大大提升吞吐量,而通过增加瓶颈部分或者使用更强大的分类器,可以进一步提升性能。
鉴于ConvMixer较大的内部分辨率、各项通行的设计,可能特别适合语义分割任务。
也可以设计实验测试做目标检测等其他任务的效果,以及进一步验证patch embedding的效果。特别是为了更深入的与ViT,MLP-Mixer做对比,还可以研究ConvMixer在大规模预训练上的性能,因为前面两者在大型数据集上训练时表现出色。
A note on paper length.
好奇为什么本文只有4页么?也不是匆忙提交的版本,本文是希望简明的阐明一个有效的想法,真的需要8-10页吗?因为本文提出的框架够简洁,要阐明的观点也十分简单:patch embedding会在卷积网络中表现良好。
本文认为4页半的长度就足够了,实验和架构细节在附录中,供有需要者仔细阅读。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









