







Transformer用于时间序列
- Abstract
- Section I Introduction
- Section II Preliminaries of the Transformer
- Section III 时间序列的Transformer模型
- Section IV Network Mdification for Time Series
- Section V Applications of Time Series Transformers
- Section VI Experimental Evaluation and Discussion
- Section VII Future Research Opportunities
- Section VIII Conclusion
From 阿里达摩院
Abstract
Transformer在自然语言处理和计算机视觉等许多任务中都取得了优异的表现,这也引起了将其用于时间序列的研究兴趣。最吸引人的是Transformer对远程依赖关系的建模,本文系统的回顾了Transformer用于时间序列建模的各种方案,从两个角度对研究进行综述。从网络结构修改的角度总结了时间序列Transformer的模块结构和网络结构;从应用的角度将时间序列Transformer按应用场景:检测、分类等进行了综述。本文主要对比了模型健壮性、模型规模、研究趋势等来总结Transformer在时间序列中的应用,最终本文讨论了未来的研究方向以提供有益的研究指导。
Section I Introduction
Transformer在捕获长程依赖和序列元素间交互作用方面显示出惊人的能力,吸引了诸多研究将其用于时间序列任务,如异常检测、分类等。周期性是时间序列的一大特性,如何有效的在建模长短期的时间依赖性的同时捕获周期性是时间序列任务的一大挑战。由于时间序列Transformer是一个新兴领域,对时间序列的Transformer模型进行系统、全面的调查将极大的有利于整个科研社区的研究,本文注意到这方面有相关的研究,如预测任务、分类任务、异常检测任务、数据增强等,但很少甚至没有对时间序列Transformer进行深度分析。
本文旨在填补这一空白。本文首先简要介绍原始的Transformer模型,然后从网络结构和应用两个视角对时间序列Transformer模型进行综述。在网络结构方面主要介绍了针对时间序列做的Transformer调整和高级体系结构的优化;在应用方面则是根据应用场景进行分类。对于每个序列模型都会分析各自的优势和局限性。为了进一步为在时间序列中使用Transformer进行指导,本文进行了一些实证研究,包括鲁棒性分析、模型尺寸和周期性分解分析。最后提出未来的研究建议,包括时间序列的归纳偏执、时间序列的Transformer和GNN网络、预训练Transformer和NAS搜索时间序列Transformer。
据我们所知本文是第一个对时间序列Transformer进行综述的文章,希望本文的研究能够对未来时间序列Transformer提供一定帮助。
Section II Preliminaries of the Transformer
Part 1 Vanilla Transformer
Transformer最初由Vaswani等人于2017年提出,是一种编解码结构来处理序列模型,编码器和解码器包含多个相同的Transformer模块 ,每个编码器块由一个多头自注意力模块和一个位置前馈的神经网络组成,每个解码器模块在多头自注意力模块和位置前馈网络之间还插入了一个交叉注意力模块。
Positional Encoding
与LSTM或RNN的区别在于Transformer没有任何迭代或卷积操作,而是使用位置编码来为输入嵌入位置信息,主要由以下编码方案:
绝对位置编码
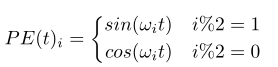
其中wi代表频率另一种是为每个位置学习一组更灵活的位置嵌入方案
相对位置编码
根据输入元素之间的相对位置关系比元素的绝对位置更有效,因此提出了相对位置编码方案,即向注意力机制的key中增加一个相对位置嵌入项。
此外还有一些使用混合位置编码方案,即将上述方法组合在一起;一般位置编码会被添加到token embedding中,随后送入Transformer.
Multi-head Attention
多头注意力计算基于Q-K-V模型,注意力的计算表达为:
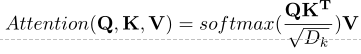
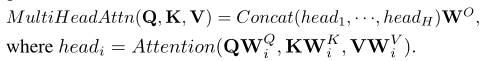
多头注意力则是不同注意力头处理的结果及连在一起的结果。
前馈网络及残差连接
位置前馈网络是一个全连接层,注意力的输出在FFN中会经过ReLU激活,并且而菏泽儿都会经过层归一化。
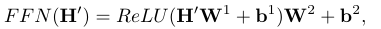
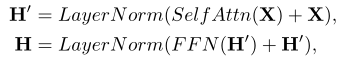
Section III 时间序列的Transformer模型
本文分别从网络结构和应用场景两个角度对时间序列Transformer模型进行综述,如Fig 1所示。

首先回顾现有的Transformer模型,从网络结构的角度总结了目前模块级别和网络级别做的改进;从应用场景来看分成了预测、异常检测、分类、聚类等应用场景。
Section IV Network Mdification for Time Series
Part 1 Positional Encoding
由于Transformer的输入序列不包含位置信息,但是时间序列的顺序又十分重要,因此位置编码就变得格外重要。常见的处理方法是将位置信息编码为向量,附加到输入的时间序列中。主要有3种编码方案:
(1)原始的位置编码
即参考原始Transformer中直接将位置编码附加到输入序列后送入Transformer,但不能充分利用时间序列数据信息,也不能适应不同的数据。
(2)Learnable Positional Encoding
有的研究发现通过学习每个位置的一组位置嵌入能表征更丰富的位置信息,这样学习到的位置嵌入更灵活,能够适应特定的任务。如Zerveas等人使用嵌入层来学习每个位置索引的嵌入表示,并与模型参数一起学习;Lim等人则是使用LSTM网络对位置嵌入进行编码,这样可以为时间序列输入提供归纳偏执信息。
(3)Timestamp Encoding
在实际应用场景中通常可以获得时间戳信息,如日历时间或一些特殊的节日、事件时间戳等,但在Transformer中几乎没有得到利用。
Informer就提出将时间戳进行位置编码,使用可学习的嵌入层学习时间戳特征;Autoformer和FEDformer也使用了这种编码方案,因为可以有效利用全局的时序信息。
Part 2 Attention Module
注意力模块作为Transformer的核心组件,有非常灵活的机制来处理输入。可以将注意力模块看做一个全连接层,权重来自于输入之间的依赖关系动态生成;因此它具有与全连接层同样的路径长度但参数量却少的多,因此适合建模长程依赖关系。
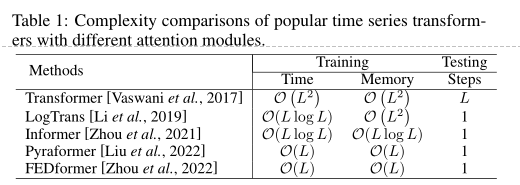
原始Transformer的时间和内存复杂度是O(L^2)L是输入序列长度,许多模型尝试减少这一计算复度,主要依赖稀疏性或者低秩近似的方式,详情参见Table 1.
Part 3 Architecture-Level Innovation
还有一些研究致力于在结构上进行创新,比如Zhou等人尝试考虑多分辨率的时间序列作为输入,这样Transformer也要变成层次化结构,还有的在注意力模块之间插入步长为2的最大池化层这样可以将时间序列长度减半;还有的建立树结构,不同深度代表不同粒度的时间序列;Pyraformer分别计算同一尺度和不同尺度之间的注意力,这样来构建输入时间序列的多分辨率表示。分层结构的优点有:
(1)可以以较低的计算复杂度处理较长序列;
(2)层次建模可以获得多分辨率表示,对特定任务是有用的。
Section V Applications of Time Series Transformers
Part 1 Transformers in Forcasting
时间序列预测
预测是时间序列最常见也是最重要的应用,LogTrans等人提出使用因果卷积生成自注意力中的k和q,此外还使用了系数偏置来降低模型计算量。
Informer则是使用KL散度来计算q-k之间的相似程度,这样可以在O(logL)复杂度下选择合适的q,也是为了减少计算复杂度,此外Inormer还使用了一个生成式解码器来生成长序列输出,避免积累误差。
AST使用生成对抗的编解码网络结构来训练稀疏Transformer模型进行预测,结果表明使用对抗训练可以直接通过调整输出分布来提升预测效果,也可以避免一次性推理带来的误差。
AutoFormer则是将时间序列的自相关性作为注意力模块,测量的是输入元素之间的时延相似性,对最相似的k个子序列进行聚合,从而将计算复杂度降维O(LlogL)
FEDformer使用了两个注意力模块分别对输入进行小波变换和傅里叶变换,傅里叶变换部分引入了一个random mode模式来达到线性复杂度。上述两个工作主要是为了说明时间序列的频域特性也引起了诸多研究者的兴趣。
TFT这一多水平预测模型包含静态协变量编码器,门控特征选择模块和实践自注意力解码模块,从各种协变量中编码和选择有用的信息进行预测,同时提供了全局、时间和事件的可解释性。
SSDNet将Transformer与状态机联系起来进行概率预测,Transformer部分负责建模时间关系,估计SSM参数,并使用SSM部分进行周期预测。
Pyraformer则是搭建了一个基于二叉树跟踪路径的层次化的金字塔模型来捕捉具有线性时间和内存复杂度的时序依赖关系。
Aliformer则是引入知识引导注意力分支来对注意力图谱进行修改、去噪。
时空预测
时空预测需要同时考虑时间依赖性和空间依赖性。Trappoc搭建了一个编解码的Transformer来捕获这一部分关联;Traffic Transformer则使用Transformer捕捉时间以来,使用图神经网络捕获空间依赖;Spatial-Temporal Transformer思路类似。
事件预测
实际应用中有众多不规则或异步时间戳的序列,不像规则的序列数据可以等间隔采样。事件预测指的是根据过去的历史来预测未来的事件或标记,通常根据时间点过程(TPP)来建模的。Zhang等人使用自注意Hawkes过程来提升事件预测的性能,还有用Transforemr来汇总历史时间的影响,以此计算事件的强度函数。ANDTT则是一种更灵活的计算时间和事件注意力的Datalog方案,实验结果表明可以更好的捕获复杂事件的依赖关系。
Part 2 Transformers in Anomaly Detection
深度学习的发展也激发了异常检测算法的发展,核心是学习一个神经网络可以将源输入分布映射到实际的输入分布,异常得分由重构误差定义,如果重构误差太高说明存在异常。
近期Meng等人揭示了Transformer比其他传统的时间依赖模型的优点
(1)Transformer的并行性可以减少80%的时间,与LSTM相比
(2)具有更高的F1分支指标
还有的研究将Transformer与生成模型结合用于异常检测,如TranAD,MT-RVAE,TransAnomoly
TransAS提出一种对抗的训练过程来放大重建误差,因为如果仅使用Transformer可能会遗漏一些异常的小偏差,整个网络包含两个Transformer encoder和decoder,进行对抗训练,来增强稳定性。消融实验结果表明如果替换掉Transformer的结构F1分数会下降11%,充分说明了Transforemr架构对TransAD的巨大贡献。
MT-RVAE则是将VAE与Transformer结合,这样可以更加并行化,将训练时间减少近80%.MT-RVAE还使用了多尺度变换来克服传统变换导致的只能提取局部序列信息的缺点,采用多尺度特征融合可以更好的提取不同层次的全局时间序列信息。
还有的研究将Transforemr与图神经网络节起来,比如图神经网络不适合维度很少或者关联不密切的序列,MT-RVAE则修改了位置编码方式,引入特征学习模块来弥补GNN的不足,这样可以考虑全局信息。 AnomalyTrans则是将Transformer与高斯先验相关联,这样可以更容易区分异常。因为与正常情况相比,异常情况与相邻的时间点更容易建立强联系。
Part 3 Transformers in Classification
Transformer被证明在分类任务也有用,通常是一个简单的编码网络,其中注意力层负责学习表征,FFN层生成类别概率。 GTN使用了两个Transformer结构分别学习时间和通道注意力,两种特征的结合则是使用一个可学习的加权连接,可以用于13种多元时间序列上的分类,还有的研究证明基于Transformer的分类模型用于卫星时间序列分析取得了优于卷积和RNN的性能。 也有的研究致力于预训练Transformer分类模型.比如使用自监督的预训练O型来进行卫星图像时间序列的分类,还有的使用吴建武框架结合预训练的Transformer模型,迁移到下游任务。
Section VI Experimental Evaluation and Discussion
本节将通过实验分析Transformer如何处理时间序列数据的,主要就是在基准数据集ETTm2上使用不同的配置来验证不同的算法。
Part 1 Robustness Analysis
许多研究为了降低注意力计算复杂度一般使用小规模的输入,本文质疑这种方法的有效性。因此本文进行了一个鲁棒性测试,逐渐输入不同长度的输入序列,对比结果参见Tabel 2,可以看到当输入序列长度变化是许多算法性能会迅速恶化,这种现象使得许多精心设计的Transformer模型在长序列的实际应用中不切实际,因为他们不能有效的利用长序列输入信息,需要进行更多的研究来充分适应长输入序列。

Part 2 Model Size Analysis
Transformer在用于时间序列之前已经是NLP,CV的主流模型,一个主要改进方向就是通过增加模型大小来提升模型预测能力,通常模型容量由Transformer层数控制,CV和NLP中层数通常设置在12到128层之间,本文比较了不同层数的Transformer模型,结果参见Table 3,可以看到3-6层的浅层次Transformer获得了最优结果,同时也提出一个问题,即如何设定一个合适的深度来提高模型的容量、获得最好的预测性能。

Part 3 Seasonal-Trend Decomposition Analysis
最新的研究中尝试使用Transformer进行周期分析,本文使用Wuetal提出的滑动平均来评估不同算法,对比结果参见Table 4.可以看到seasonal-trend decomposition模块可以大幅度提升算法性能,提升高达50%-80%,这一独特的模块值得进一步研究。
Section VII Future Research Opportunities
Part 1 Inductive Biases for Time Series Transformer
原始的Transformer模型不包含数据模式或者特征的先验知识,但是却需要大量的训练数据。时间序列数据具有明显的时间依赖性,往往表现出复杂的季节或周期特性,因此最近的一些研究表明将序列的周期性或者频域特点加入Transformer结构可以带来性能提升。因此未来一个有前景的发展方向就是对特定时间序列和任务特点进行分析,采用最有效的方式引入先验知识,从而获得更优的Transformer架构。
Part 2 Transformer and GNN for Time Series
多元时空序列越来越多在不同场景出现,这需要额外的技术来处理这种高维数据,尤其是捕获维度之间的潜在关系。引入图神经网络GNN是一种建模空间依赖性和维度间关系的方式。近期的研究表明GNN与Transformer结合可以显著提升性能,还可以进行多模态预测、深入了解动态失控特征,因此二者的结合指的进一步研究。
Part 3 Pre-trained Transformer for Time Series
Transformer用于NLP需要大规模的预训练,从大量数据中捕获先验知识,然后微调迁移到下游任务。但是对于时间序列的预训练Transformer模型研究有限,主要集中在时间序列的分类上,仍有很大的研究空间。
Part 4 Transformers with NAS for Time Series
Transformer结构设计具有挑战性,因为嵌入尺寸、注意力头数、层数都会影响最终性能,人工调整这些超参数十分费时费力。借助NAS可以有效解放人工,Chen等人的研究发现对于高维度的长序列模型设计内存高效计算高效的Transformer模型十分有必要,因此如何利用NAS自动设计高效的时间序列Transformer是值得研究的。
Section VIII Conclusion
本文对各种任务的时间序列Transformer模型进行了全面综述,从两种分类视角进行对比分析,分别是网络结构修改和应用场景。并且通过实验对比了不同算法的优势和局限,最后对未来的研究方向进行了探讨。















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









