







图一 faster rcnn结构图
知乎上的这篇文章写的挺详细的,记录下。。
https://zhuanlan.zhihu.com/p/31426458
这里借用github上scutan90的深度学习500问中的图,Faster R-CNN的结构可分为四个部分:
- 特征提取网络CNN。
- 区域建议网络RPN。
- ROI pooling,这一步主要是将ROI映射到特征图上,然后进行分片,再对每个片maxpooling,主要作用是将不同大小的ROI统一成固定长度的输出。
- 分类和回归
特征提取网络
这里没什么好说的,就是使用经典的几个网络对输入图片提取特征,最后输出feature map。如VGG16、res50、res101等。
区域建议网络RPN

图2 RPN网络
RPN是Faster R-CNN的核心所在,它是一个全卷积网络,输入是前面cnn提取的特征图,使用3*3的卷积核在特征图上滑动,步长为1,padding为2。同时要引入Anchors的概念。具体操作是在对特征图卷积的同时,以每个卷积核的中心点为anchors的中心,为每个特征点生成长宽比为[1:1,1:2,2:1]的共9个矩形,如下图所示:
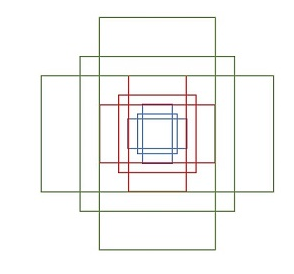
图3 anchors
在生成完候选roi之后,要进行分类和回归,对于分类层,要判断每个roi是前景还是背景,因此对每个特征点会有2*9个打分,而对于回归层,每个anchor都对应[x,y,w,h]这四个值,因此回归的时候会有4*9个coordinates,这里就对应图2中的2k scores 和4k coordinates, k默认值为9。
RPN Classification
这是一个二分类器,需要识别是前景还是背景,既然是classification,就需要监督信息,这里的监督信息通过计算anchor与ground truthIOU获得,规则为:
若Anchor与ground truth的IOU>0.7,则记为正样本
若Anchor与ground truth的IOU<0.3,则记为负样本
0.3~0.7之间的Anchors不参与训练
此外,覆盖到feature map边界的Anchors也不参与训练
损失函数为
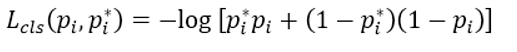
即目标和非目标的对数损失。
RPN Regression
regression的目的是得到前景的大致区域,更精确的区域通过后面的Proposal layer得到,再经过了前一步的Anchors打标签后,只需要对正样本的Anchors做回归。此时我们需要对anchors和ground truth建立表达式关系,设我们的目的是寻求一种变换F,使得
也就是说要对anchors进行平移和缩放以尽可能的接近ground truth。原文中的平移因子和尺度因子
如下所示:
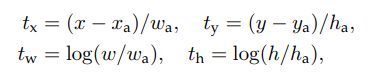
接下来的任务是使用线性回归的模型表示出这个变化,也就是输入X,学习到一组参数W,使得X与Y接近,即Y=W*X,这里的输入经过predict anchors的feature map,记为,输出是ground truth的feature map,记为d,这里的*表示x,y,w,h每个变化对应的变换函数。
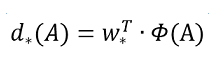
那么,损失函数可以设计为:
![]()
其中,,R是smooth L1函数,如下所示,
表示ground truth。
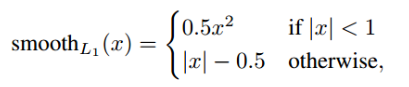
那么RPN网络最终的损失函数就是
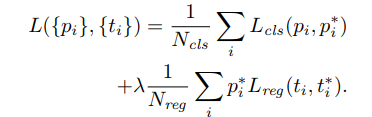
Proposal layer
再得到了proposal的大致位置后,下一步的任务是对位置做更精确的回归。但是在计算大致位置之前,首先需要对anchors进行筛选,这样可以减少不必要的计算,筛选步骤如下:
- 按照foreground softmax scores由大到小排序,提取钱6000个
- 将anchors映射回原图,提出超出边界的foreground anchors
- 使用nms
经过筛选的foreground anchors就可以继续计算精确位置了,精确位置回归的公式和bounding box regression的计算方式完全相同,只不过将predict anchors换成了proposal anchors。
ROI pooling

图4 ROI pooling 示例图
这一次的主要作用是将不同大小的RoI转换为统一大小的输出,以便后续的分类。
具体操作为:
- roi映射,首先将roi映射到特征图的相应位置;
- 对映射后的roi分片
- 对每个片进行maxpooling操作
如图4所示,此时的特征图大小为8*8,roi投影后的对应位置为(0,3),(7,8),再将该区域划分为(2*2)个sections,注意这里的2*2是根据要求输出的大小确定的,然后对每个section做maxpooling操作,这样就得到了固定大小的输出。
训练过程
最后想再来讲一下整个网络的训练过程,作者提出的训练过程有四步:
- 使用ImageNet的预训练模型,初始化RPN,单独训练RPN网络;
- 使用ImageNet的预训练模型初始化Fast Rcnn,同时将第一步RPN的输出作为Faste RCNN的输入;
- 使用第2部的模型再次训练RPN网络,要求固定住公共网络部分,只更新RPN的参数;
- 使用上一步的结果微调Faste RCNN,同样是固定公共网络不变,只更新检测网络。
参考博客
https://blog.csdn.net/zj15939317693/article/details/80569160
https://blog.csdn.net/qq_17448289/article/details/52871461
https://blog.csdn.net/weixin_40449426/article/details/78141635















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









