







灰狼优化算法(Grey Wolf Optimizer, GWO)
由澳大利亚格里菲斯大学(Griffith University)研究学者 Seyedali Mirjalili 于 2014 年提出,是一种模拟自然界中灰狼的等级制度与狩猎行为的群智能优化算法,具有操作简单、调节参数少、编程易实现等特点。首先介绍了 GWO 的仿生学原理及其进化公式,然后对 GWO 的进化过程进行描述,最后给出 GWO 的伪代码与时间复杂度分析。
标题灰狼优化算法原理
灰狼是社会性的捕食者,具有严格的社会阶级划分,在一个狼群中,灰狼可分为alpha、beta、delta 和 omega 四个等级,上级的灰狼支配下级的灰狼,下级的灰狼服从并执行上级灰狼的决策。如图 2.1 的金字塔型结构所示:

α
\alpha
α 位于顶端,代表狼群中的头狼,负责做出狩猎,休息等决策;由于其它的狼需要服从
α
\alpha
α狼的命令,所以
α
\alpha
α狼也被称为支配狼。另外,
α
\alpha
α 狼不一定是狼群中最强的狼,但就管理能力方面来说,
α
\alpha
α 狼一定是最好的。
β
\beta
β是
α
\alpha
α 的从属者,它们的职责是协助
α
\alpha
α 做出决策,当已有的
α
\alpha
α 失去优势时,它们也是代替其成为新的
α
\alpha
α 的最佳候选者;在
α
\alpha
α狼去世或衰老后,
β
\beta
β 狼将成为
α
\alpha
α 狼的最候选者。虽然
β
\beta
β 狼服从
α
\alpha
α 狼,但
β
\beta
β 狼可支配其它社会层级上的狼。
δ
\delta
δ支配底层的
ω
\omega
ω,但服从于
α
\alpha
α 和
β
\beta
β 的指令;
ω
\omega
ω 位于底端,狼群中的大部分灰狼属于这一阶级,它们负责执行以上三个等级灰狼的决策,协调狼群内部的关系。
优化过程将包围、追捕、攻击三个阶段的任务分配给各等级的灰狼群来完成捕食行为,从而实现全局优化的搜索过程。下面对这三个阶段分别进行介绍:
1.包围:
在 GWO 中,灰狼在狩猎过程中利用以下位置更新公式实现对猎物的包围 :
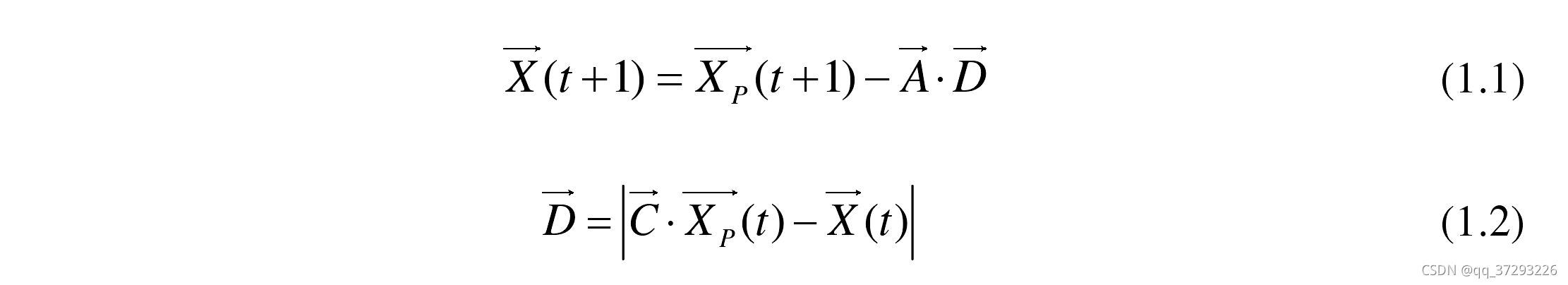
其中, X 表示灰狼的位置;t 为当前迭代次数;
X
p
\ X_p
Xp表示猎物的位置; D 表示灰狼与猎物之间的距离,其计算方式见公式(1.2)。 A 和 C 是两个协同系数向量, 其计算见公式(1.3)和公式(1.4):
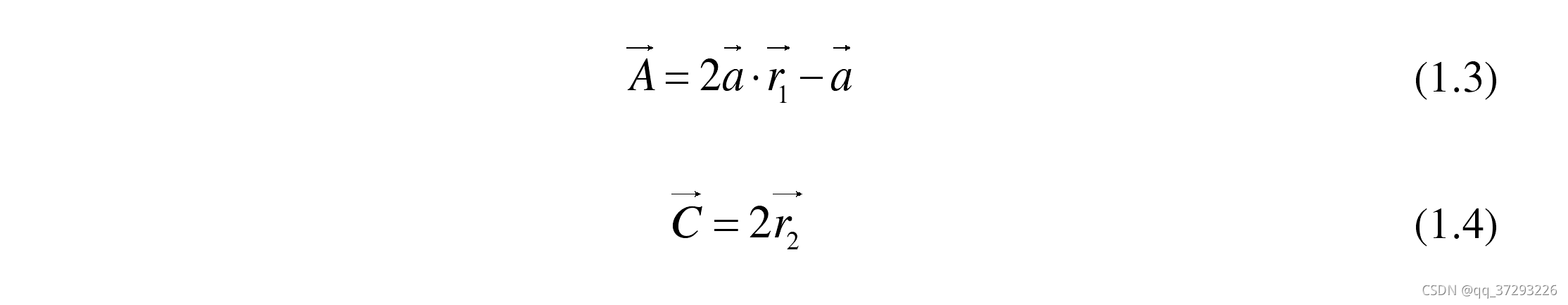
其中,
r
1
→
\overrightarrow{r_1}
r1、
r
2
→
\overrightarrow{r_2}
r2是两个一维分量取值在[0,1]内的随机数向量,向量 A 用于模拟灰狼对猎物的攻击行为,它的取值受到
a
→
\overrightarrow{a}
a 的影响。收敛因子
a
→
\overrightarrow{a}
a 是一个平衡GWO 勘探与开发能力的关键参数.
a
→
\overrightarrow{a}
a 的取值随着迭代次数的增大从 2 到 0 线性递减,计算公式如(1.12)所示。
2.追捕:
在自然界中,虽然狩猎过程通常由头狼在
α
\alpha
α 狼引导,其它等级的狼配合对猎物进行包围、追捕和攻击,但在演化计算过程中,猎物(最优解)位置
X
p
\ X_p
Xp是未知的,因此在 GWO 中我们认为最优的灰狼为
α
\alpha
α,次优的灰狼为
β
\beta
β,第三优的灰狼为
β
\beta
β,其余的灰狼是
ω
\omega
ω,根据
α
\alpha
α(潜在最优解)、
β
\beta
β 和
δ
\delta
δ对猎物的位置有更多知识的这一特性建立模型,迭代过程中采用
α
\alpha
α、
β
\beta
β 和
δ
\delta
δ 来指导
ω
\omega
ω 的移动,从而实现全局优化。利用
α
\alpha
α、
β
\beta
β 和
δ
\delta
δ的位置
X
α
→
\overrightarrow{X_\alpha}
Xα、
X
β
→
\overrightarrow{X_\beta}
Xβ 和
X
δ
→
\overrightarrow{X_\delta}
Xδ ,使用下述方程更新所有灰狼的位置:
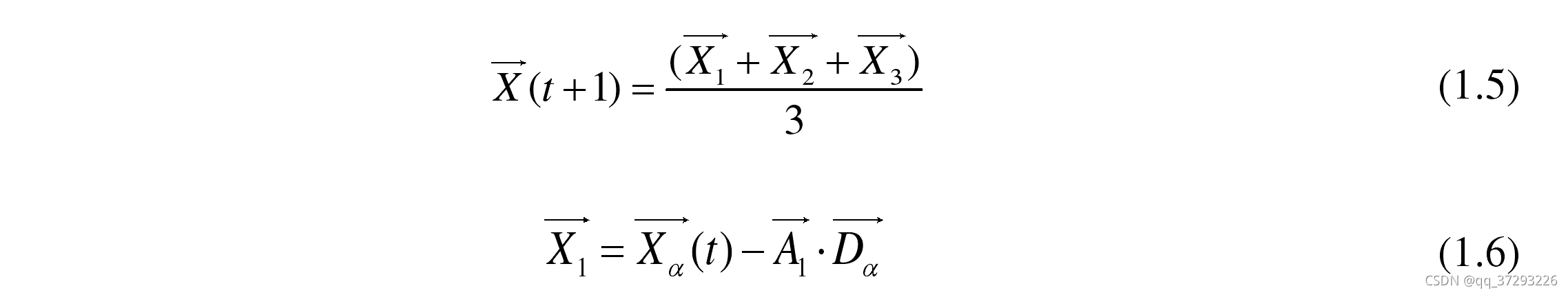
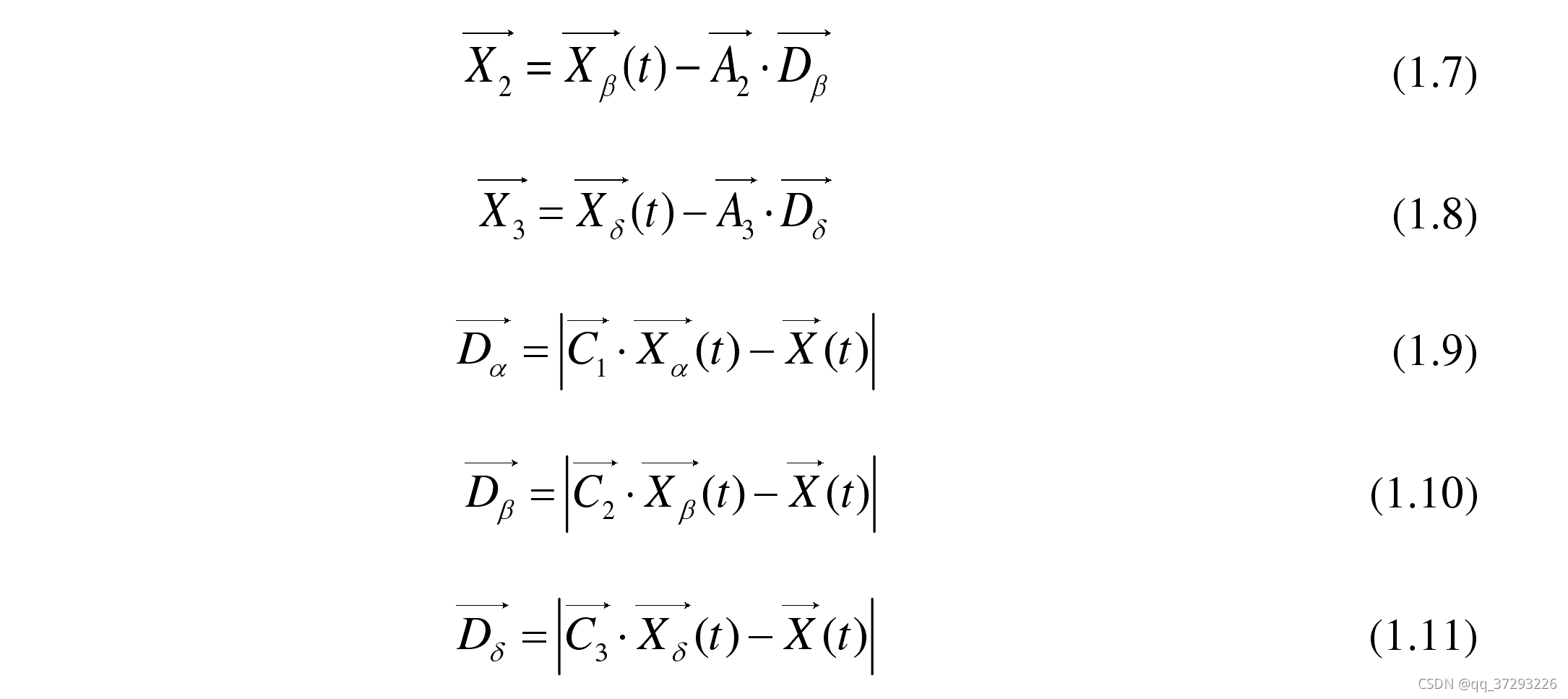
灰狼的位置更新方式[10]可以用下图形象地表示。
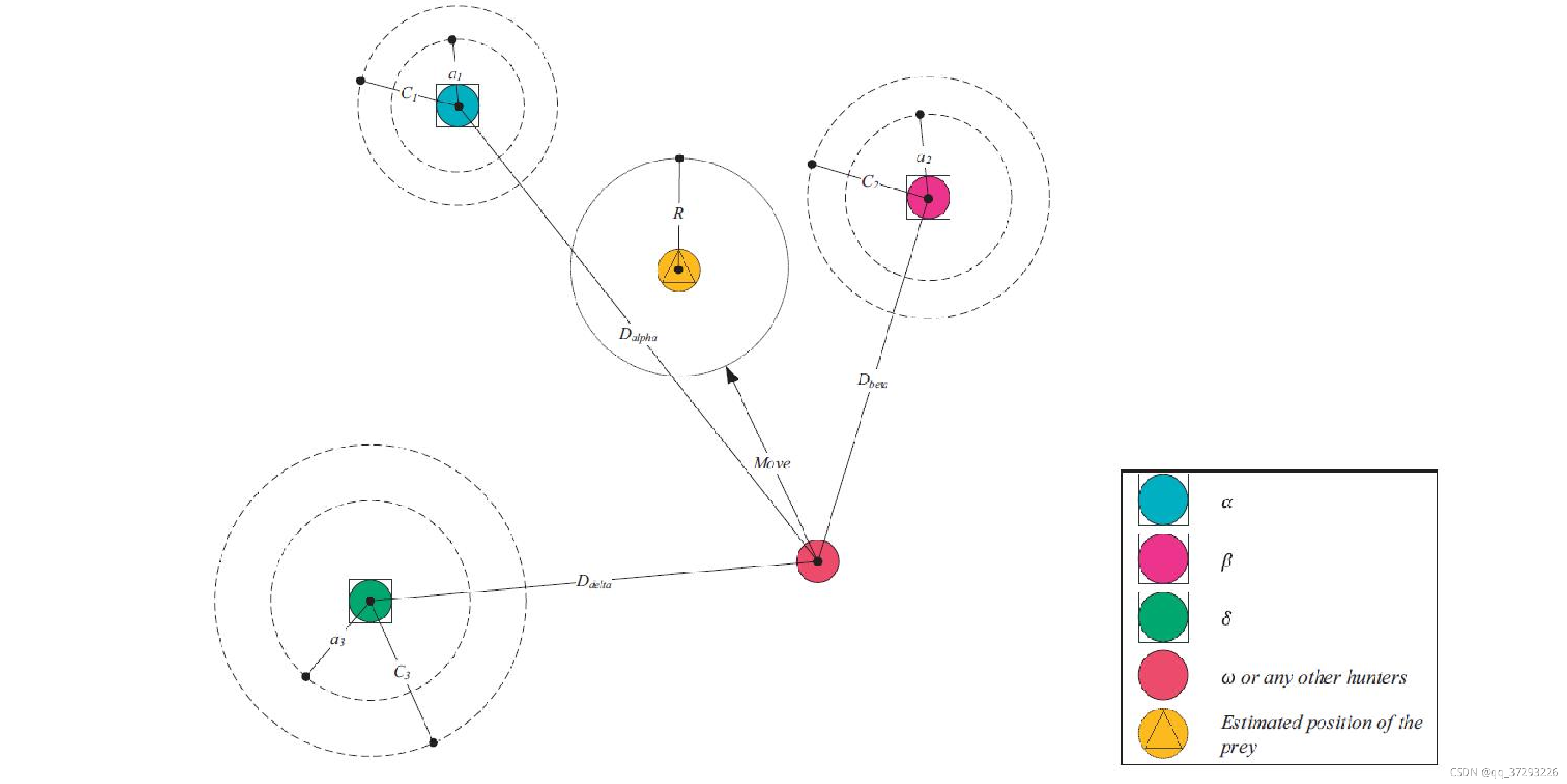
图2 灰狼位置更新方式
3.攻击
在下面的公式(1.12)中,t 表示当前迭代次数,T 为设定的最大迭代次数。当
a
\ a
a 的值从 2 递减至 0 时,其对应的 A 的值也在区间[-a, a]变化:
a
\ a
a 的取值越大则会使灰狼远离猎物,希望找到一个更适合的猎物,因而促使狼群进行全局搜索(|𝐴| > 1),若
a
\ a
a 的取值越小则会使灰狼靠近猎物,促使狼群进行局部搜索(𝐴| < 1)。

参考文献:
1.李泽文. 灰狼优化算法研究及应用[M],河北地质大学
2.张森.灰狼优化算法研究及应用[M],广西民族大学














 3630
3630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









