







python学习:
🚩 python处理excel数据常见问题
🐌 行名、列名重命名
1️⃣ :
import pandas as pd
import numpy as np
df=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=["a","b","c"])
print("df\n",df)

将df的列名[“a”,“b”,“c”]更改为大写的[“A”,“B”,“C”],具体如下:
将df的行名[0,1,2]更改为[0,“a”,“c”],具体如下:
df.rename(columns={"a":"A","b":"B","c":"C"},inplace=True) ##inplace=True 在原数据上更改并覆盖
df.rename(index={1:"a",2:"b"},inplace=True)
print("df\n",df)

将df的列名[“a”,“b”,“c”]更改为大写的[“A”,“B”,“C”,“D”],增加一列并将其填充为100,具体如下:
将df的行索引更改,[0,“a”,“b”,“c”],增加一行并将其填充为100,具体如下:
df2=df.reindex(index=[0,'a','b','c'],columns=['A','B','C','D'],fill_value=100,copy=True)
print("df2\n",df2)

💡 注意输出,相同索引的元素保持不变,新索引通过参数fill_value填写缺少的值为100。
2️⃣ :
列名重新定义,并将原来的列名作为第一行,原始数据向下平移,长度增加1
df=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=["a","b","c"])
new_columns = ["一","二","三"]
old_columns = df.columns
df.columns = new_columns ## 设置新的列名
df_new = df.shift(1) ##数据后移一行,-1表示前移一行
print("df_new\n",df_new)
df_new.iloc[0,:] = old_columns ##将第一行赋值为原来的列名
print("df_new\n",df_new)
df_new = pd.concat( [df_new,df.iloc[-1:, :]],axis=0).reset_index(drop=True) ## 拼接为新的DataFrame
print("df_new\n",df_new)

3️⃣ :
读取excel数据时:第二行作为列名,并删除第一行
df = pd.read_excel("xxx.xlsx",header=1)
🐌 不同的DataFrame合并为一个DataFrame
1️⃣ 示例 1:
横向拼接
pd.merge(df1,df2,on=['x'],how='left').reset_index(drop=True) ## reset_index(drop=True)使index会被reset,on=['x']其中X为df1和df2相同的列名
pd.concat([df1,df2],axis=1) ## axis=1为横向拼接
💡 注意:其中merge的使用方法有很多种,横向合并还可以使用 join。
2️⃣ 示例 2:
纵向拼接
pd.concat([df1, df2],axis=0).reset_index(drop=True) ## axis=0 纵向
pd.concat([df1, df2],axis=0,ignore_index=True) ### ignore_index=True等价与reset_index(drop=True)
df1 = df1.append(df2,ignore_index=True)
🐌 数据操作
1️⃣ 示例 1:
判断数据是否为空
df.empty: ## 判断DataFrame是否整体为空
np.any(df.isnull()) ##判只要有一个空值就会返回True, 否则为False
np.sum(pd.isnull(df["xx"]))>0 ##判断某一列,有空值计算空值个数大于0,无空值为0
pd.isnull(df["XX"]).any() ##判断某一列,有空值为True, 否则为False
np.any(df["a"].isnull()) ##判断某一列,有空值为True, 否则为False
2️⃣ 示例 2:
数据删除
df=pd.DataFrame([[0,0,0],[0,0,0],[0,0,0]],index=["A","B","C"],columns=["a","b","c"])
df.drop(index=["A"],inplace=True) ## 删除行,inplace=True原数据改变
df.drop(columns=["a"],inplace=True) ## 删除列
3️⃣ 示例 3:
数据增加
df=pd.DataFrame([[0,0,0],[0,0,0],[0,0,0]],index=["A","B","C"],columns=["a","b","c"])
df.loc["D"]=[1,2,3] ## 增加一行
df["d"] = [4,5,6,7] ## 增加一列
4️⃣ 示例 4:
重置行索引
df = df.reset_index(drop=True)
5️⃣ 示例 5:
筛选具体位置的数据
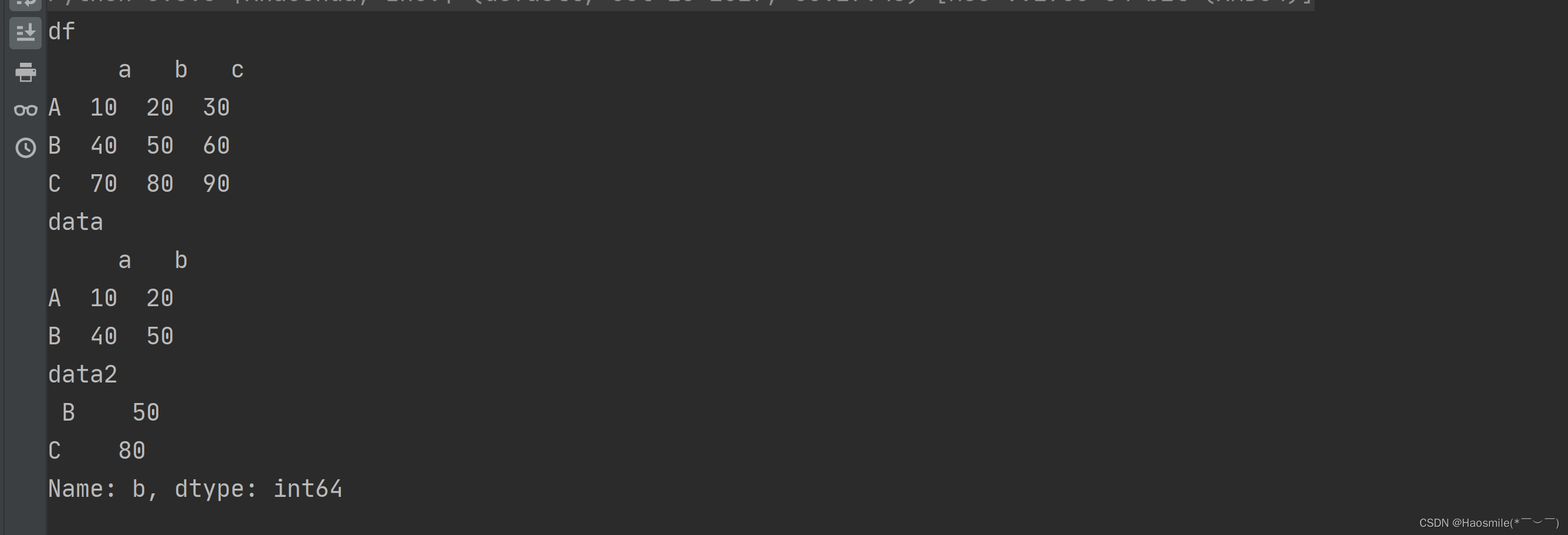
df=pd.DataFrame([[10,20,30],[40,50,60],[70,80,90]],index=["A","B","C"],columns=["a","b","c"])
print("df\n",df)
data = df.iloc[0:2,0:2] ##获取第一行到第二行第1-2列的数据
print("data\n",data)
data2 = df.loc["B":"C","b"] ## 获取B-C行b列的数据
print("data2\n",data2)
6️⃣ 示例 6:
lambda函数
df["d"] = df["c"].apply(lambda x: get_sum(x)) ## 对c列+2得到d列

数据类型分组
df_new = df.groupby(by=['date','time'])['a','b'].sum().reset_index() ## 按照日期时间对a和b 进行同时刻求和
7️⃣ 示例 7:
文档复制和重命名
import os
os.rename(path1 +old_name,path2 + new_name) ## path1+old_name为原文件的路径和名称,怕她会+new_name为将文件重新保存的新路径和名称
import shutil
os.getcwd() #获取根目录
shutil.copy(older_path + name,new_path + name} ## 将文件从olderpath复制到新的newpath路径下
8️⃣ 示例 8:
将不同的DataFrame保存到同一个excel中的不同sheet中
df1=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],index=["A","B","C"],columns=["a","b","c"])
df2=pd.DataFrame([[10,20,30],[40,50,60],[70,80,90]],index=["A","B","C"],columns=["a","b","c"])
df3=pd.DataFrame([[100,200,300],[400,500,600],[700,800,900]],index=["A","B","C"],columns=["a","b","c"])
sheet_name_list = ["A","B","C"]
data_list = [df1,df2,df3]
write = pd.ExcelWriter("data_result\\123.xlsx")
for da, sh_name in zip(data_list, sheet_name_list):
da.to_excel(write, sheet_name=sh_name, index=False)
# 必须运行write.save(),不然不能输出到本地
write.save()
💡 注意:这里是一次就能得到不同的数据,比如数据分别在不同的表想合并到一张表。
9️⃣ 示例 9:
读取多个sheet
#获取文件的sheep_name
sheep_name=pd.ExcelFile('123.xlsx')
sheet_names=sheep_name.sheet_names
print(sheet_names)
#获取文件的sheep_name
df=pd.read_excel('123.xlsx',sheet_name=None) #要想获取所有sheets名称 这个必须设置为None
sheet_names=list(df)
print(sheet_names)
for i in sheet_names:
df = pd.read_excel('123.xlsx', sheet_name=i)
print(df)
















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









