










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于机器手机外观缺陷视觉检测算法 -YOLO
课题背景和意义
实现技术思路
一、机器视觉缺陷检测方法
传统的机器视觉缺陷检测方法
传统的机器视觉缺陷检测方法主要是研究图像的特征选取 特征的选择以及特征的识别这三个方面。在图像特征选取方面.主要研究内容是图像特征的提取 特征的选择和图像的识别。在特征提取时有根据统计量来提取的,也有根据信号域来提取的。获取图像 图像处理和图像反馈三部分组成的,先用特殊的专业相机去获取清晰度高的图像。
基于深度学习的缺陷检测方法
基于深度学习的缺陷检测方法通过卷积计算,将图片的特征参数化,提高了算法的实用性和有效性,可以再通过优化参数从而来提高算法的精准度。将现有的 FCN(FullyConvolutional Network)进行改进,构建了一套适合裂纹检测的全卷积神经网络 Crack FCN,该网络保留FCN网络的优点,输入的图片没有限制。
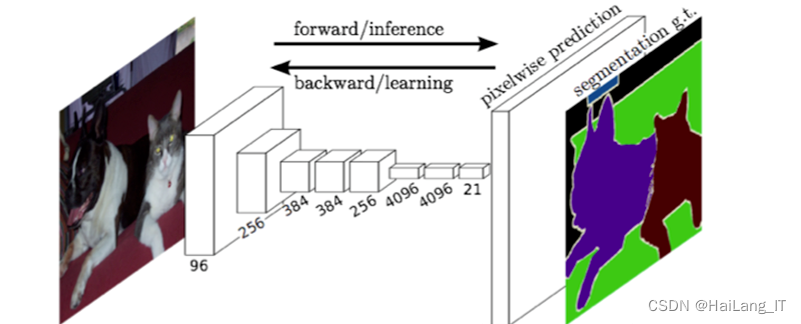
CNN(Convolutional Neural Network)算法, CNN属于前馈神经网络 是一种包含了卷积计算的深度学习网络。CNN网络一般包括了卷积层、池化层和全连接层。卷积神经网络的主要模型包括LeNet模型、 AlexNet模型,VGGNet模型和ResNet模型等。
二、YOLO-q-v3 算法
YOLO-q-v3 算法采用 53层卷积层.其中卷积层由 filters 过滤器和激活函数构成.通过设定Glter 的数值,按照设置的步长不断地提取冬片的特征,从局部特征再到总体的特征,从而完成终像的识别。卷积层的参数包括了卷积核的大小 步长和填充。卷积层里面有多个卷积核,卷积核的大小影响了选择区域的大小即感受野的大小卷积核越大提取的图片特征越复杂。全连接层的作用是将经过卷积层和池化池处理后的数据串联起来,再对串联出的结果进行识别和分类。全连接层接受卷积层或者池化层的输入,并输出一个多维向量。
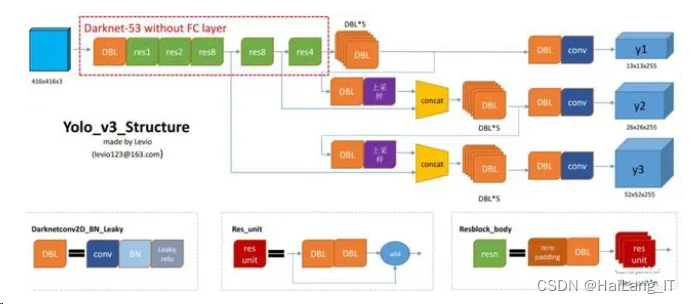
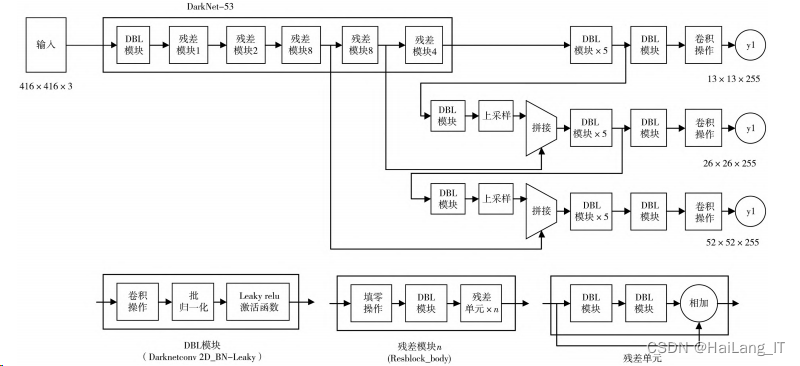
YOLO-q-v3 算法设计
YOLO-q-v3 算法中用于提取特征的主要网络是卷积神经网络 DarkNet-53。DarkNet-53 提取了 ResNet 网络的优点,它在某些卷积层之间添加了一条快捷路径.这条路径和卷积层形成了残差组件。残差组件可以使得网络层数相应减少 参数减少从而减少计算量,使得 DarkNet-53 的性能得到了较大提升。

YOL0-q-v3 算法还采用了FPN(Feature Pyramid Net- works)的结构改善对较小物体的检测结果,每一个特征图被拿来做了边界框回归,其中尺寸最小的顶层特征用来检测较大的物体而尺寸较大的特征图则用来检测较小的物体。如果是单一尺度检测器.尺度太大而数据集上特征过小就会导致生成的锚框对小特征检测效果不好。
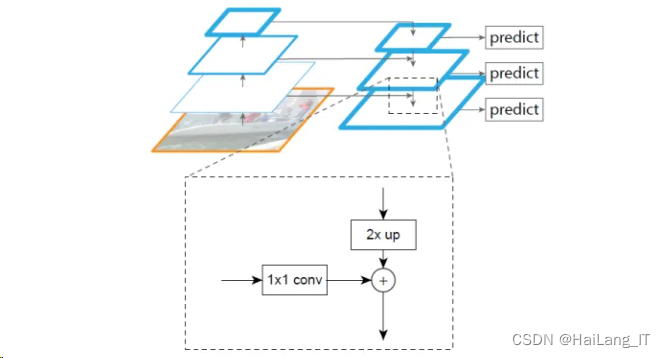
算法实现
Y0L0-q-v3 算法实现步骤如图所示,首先通过特征提取网络DarkNe-53 对输入的图像进行特征提取,得到不同尺度大小的特征图,然后对图像的特征图进行网格划分.划分出来的网格可以负责来预测落在该网格中的真实边界框中的目标。每个目标有固定数量的边界框在YOLO-a-y3中有3个边界框:最后使用逻辑回归来确定预测的同归框。
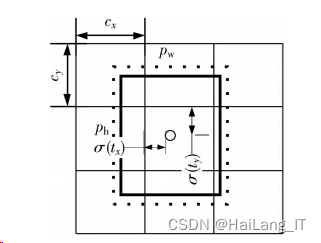
1)检测框预测
如图改进算法直接预测相对位置,预测出b-box中心点相对于网格单元左上角的相对坐标。
根据anchor的预测值来预测宽和高的公式如下:

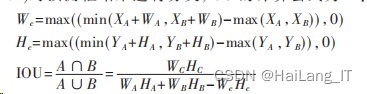
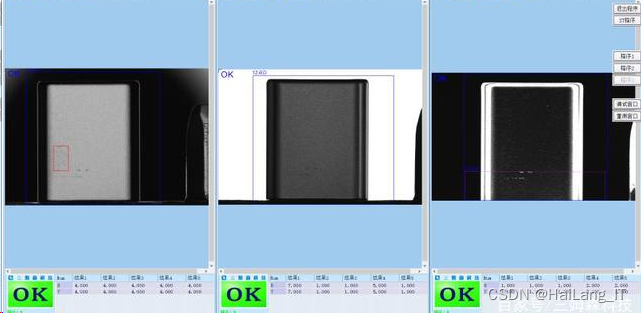
实现效果图样例
智能视觉手机缺陷检测系统是维视图像:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









