







 本文介绍了基于深度学习的蜜蜂识别算法系统,涉及卷积神经网络理论、目标检测技术、数据集构建与扩充,以及实验环境搭建和模型微调的过程。重点讲解了如何使用EfficientDet和迁移学习技术来提高蜜蜂识别的准确性和鲁棒性。
本文介绍了基于深度学习的蜜蜂识别算法系统,涉及卷积神经网络理论、目标检测技术、数据集构建与扩充,以及实验环境搭建和模型微调的过程。重点讲解了如何使用EfficientDet和迁移学习技术来提高蜜蜂识别的准确性和鲁棒性。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的蜜蜂识别算法系统
课题背景和意义
随着生态保护和农业生产的不断发展,蜜蜂作为重要的授粉昆虫,其生态价值和经济效益日益凸显。然而,由于环境变化和人为因素的干扰,蜜蜂的生存环境面临威胁,其种群数量逐年下降。因此,实现对蜜蜂的准确、高效识别对于生态保护、农业生产和蜜蜂养殖具有重要意义。基于深度学习的蜜蜂识别算法系统利用先进的计算机视觉和深度学习技术,可以实现对蜜蜂的自动识别和计数,为蜜蜂研究和生态保护提供技术支持。
实现技术思路
一、算法理论基础
1.1 卷积神经网络
卷积网络,又称为卷积神经网络,是一种用于处理具有网状结构数据的神经网络模型。它主要应用于处理时间序列数据和图像像素数据,这两类数据都具有网状结构。卷积神经网络最早被广泛应用于处理二维像素网格数据和一维时间序列数据,随着研究人员的不断投入和深化网络结构,后续也逐渐扩展到其他类型的数据。
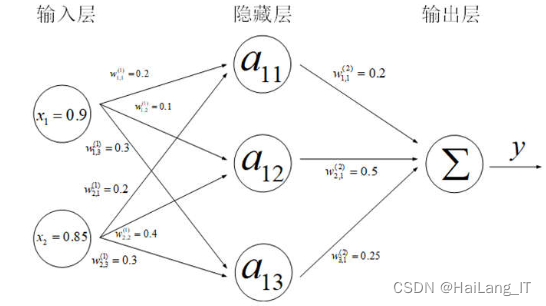
卷积神经网络中的核心操作是卷积运算,它是一种线性运算。神经网络的最小单元是神经元,它通过加权求和的方式将输入信号转换为输出信号。权重参数是神经元的主要参数,通过优化过程对权重参数进行调整,以使输出信号更好地匹配输入数据的标签。
经典卷积神经网络的基础组件可以分为简单层和复杂层两类。在简单层中,每个层对应不同的操作步骤,并包含不同的参数。卷积运算是其中的核心操作,它是一种特殊的线性计算。简单层中的卷积层经过多次卷积运算产生线性激活响应,然后通过非线性函数进行激活。最后,池化层通过池化函数调整输出结果。
基础卷积神经网络可以分为三级:
- 第一级:并行计算多个卷积运算产生的线性激活响应。
- 第二级:探测级,将上一级产生的激活响应通过非线性函数进行激活。
- 第三级:池化层,通过池化函数对输出结果进行调整。
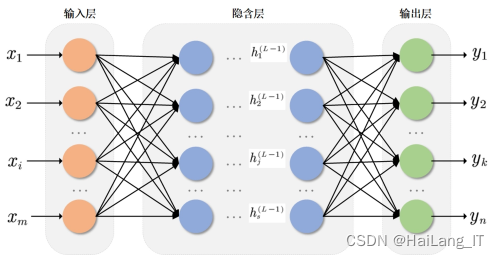
在简单全连接神经网络中,一个神经元可以同时接收多个输入,但只有一个输出。每个神经元与网络中的其他神经元按照全连接的方式进行连接。整个网络可以分为三个部分:输入层、隐藏层和输出层。输入层是网络的起点,包含输入数据的节点。隐藏层由多个层次的神经元堆叠而成,每个隐藏层接收上一层的输出作为输入。图中的隐藏层只包含一层,是一个相对简单的网络结构。输出层是网络的最后一层,通常使用激活函数将输入映射为输出概率值。在图中的示例中,输出层只有一个节点,表示网络的最终输出。
简单全连接神经网络通过多个神经元的组合和堆叠来实现对输入数据的处理和特征提取。每个神经元接收多个输入,并通过计算得到一个输出值,这个输出值又可以作为其他神经元的输入。这样的全连接结构使得神经网络能够学习输入数据的复杂关系和表示。
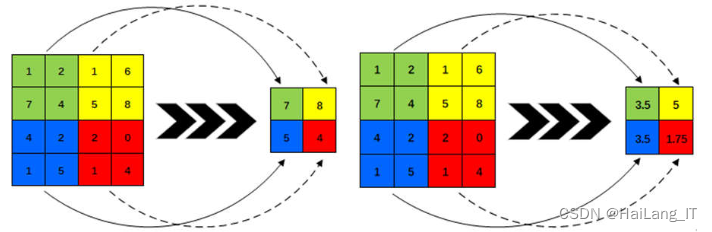
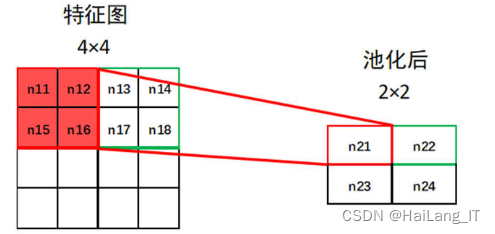
对于全连接层,权重的确定过程与多层神经网络类似,需要进行迭代步骤来确定最优值。多个全连接层的堆叠也需要按照链式法则从上到下进行调整和更新。在池化层中,误差传播的方式可以看作是将池化层转换为全连接层。例如,对于一个4×4的特征图通过最大池化后得到2×2的特征图。如果将池化层修改为全连接层,其中红色框和绿色框内的元素会进行全连接操作。这意味着红色框中的元素与一个特定的神经元相连,绿色框中的元素与另一个神经元相连。因此,可以将池化层视为部分全连接的全连接层。
1.2 目标检测算法
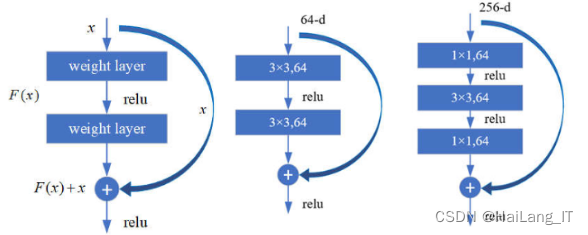
在深层的神经网络中,如GoogLeNet和VGG-16,经常会遇到梯度消失和梯度爆炸等问题。为了解决这些问题,ResNet提出了残差结构,通过引入残差函数来连接网络的不同层,使得可以训练更深层次的网络结构,并有效减少梯度消失和梯度爆炸的发生。
ResNet的核心部分是快捷连接,即通过跨层的直接连接来传递残差信息。在ResNet中,整体结构被称为组件(building block)。右侧的结构被称为瓶颈设计(bottleneck design),ResNet模型结构由左至右逐渐转变,引入了特有的快捷连接。这种设计有效地降低了模型参数的数量,并解决了在加深模型过程中出现的梯度消失或梯度爆炸的问题。
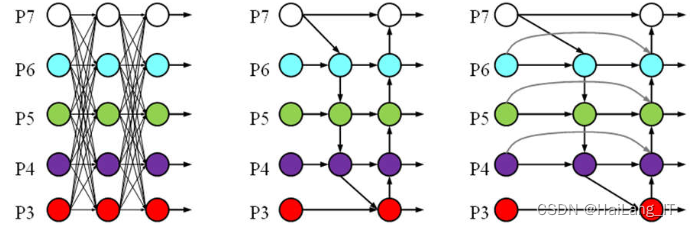
BiFPN是一种用于目标检测任务的特征融合网络层。BiFPN层在每个金字塔层级上进行了一系列的操作,包括跨层连接、特征融合和特征调整。它通过跨层连接捕捉不同分辨率的特征,然后使用注意力机制进行特征融合,以平衡不同层级的特征权重。接下来,BiFPN层使用双向的特征传播机制,在自底向上和自顶向下的方向上调整特征图的分辨率和语义信息,以增强目标检测的性能。
BiFPN层的引入有效地提升了目标检测算法在小目标检测和多尺度目标检测方面的性能。它能够更好地处理不同尺度的特征,提高目标检测的准确性和鲁棒性。
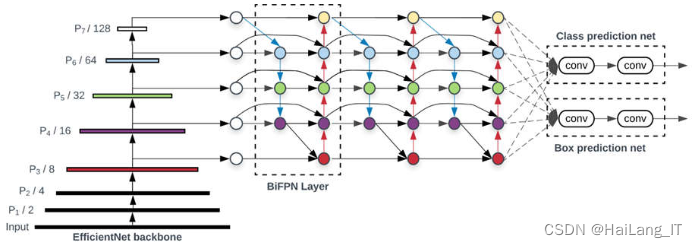
EfficientDet模型是由EfficientNet主干网络、BiFPN堆叠层和分类回归网络组成的。主干网络采用EfficientNet系列,包括EfficientNet-B0到B7八个类别,通道数按指数形式增加,深度线性增加。分类回归网络与BiFPN具有一致的宽度。输入图像的分辨率必须是128的倍数,每层的图像大小为输入图像的1/2。综上所述,EfficientDet模型通过EfficientNet主干网络、BiFPN堆叠层和分类回归网络的组合,实现目标检测任务,并具有较高的性能。
二、 数据集
2.1 数据集
为了实现基于深度学习的蜜蜂识别算法系统,我们首先面临的是数据集的问题。由于蜜蜂种类繁多、形态各异,且其图像在自然环境中受到多种因素的影响,如光照、背景等,导致现有公开数据集中的蜜蜂图像数量有限且质量参差不齐。因此,我们决定自制一个蜜蜂图像数据集。在自制数据集的过程中,我们采用了多种数据来源,包括蜜蜂养殖场的实地拍摄、网络上的公开蜜蜂图像等。为了确保数据集的多样性和准确性,我们对图像进行了严格的筛选和标注,去除了质量不佳和标注不准确的图像。

2.2 数据扩充
数据扩充是一种在深度学习中常用的技术,旨在增加训练数据的多样性和数量,以提高模型的泛化能力。在蜜蜂识别算法系统中,我们采用了多种数据扩充方法来增强数据集的质量。例如,通过旋转图像可以改变蜜蜂的姿态和方向;通过缩放图像可以模拟不同距离的拍摄效果;通过裁剪图像可以去除背景干扰,突出蜜蜂的特征。此外,我们还采用了色彩抖动和噪声添加等技术来改变图像的亮度和对比度,以及模拟实际拍摄中可能出现的干扰因素。这些数据扩充方法有助于模型更好地学习到蜜蜂的特征和模式,提高识别准确性和泛化能力。

三、实验及结果分析
3.1 实验环境搭建

3.2 模型训练
本研究中的数据规模足够满足微调条件,预训练的Mini-EfficientDet模型是基于自制数据集进行训练的,因此可以通过微调这个模型来适应新的数据集。可以使用自制数据集来微调整个网络模型。综上所述,可以使用预训练的Mini-EfficientDet模型,并通过自制数据集进行微调,以适应新的目标检测任务。
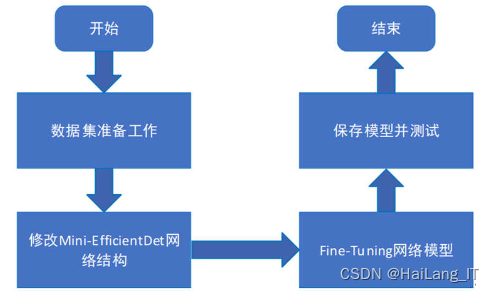
基于迁移学习的Mini-EfficientDet检测算法的微调具体实施步骤如下:
- 整理图像数据集,确保所有图像尺寸大小一致。
- 修改模型结构,将分类子网络中的最后一个卷积层改为全连接层,并设置类别数为3。将回归子网络的最后一个卷积层改为全连接层,并设置输出数量为9。
- 使用迁移学习算法,将在数据集上训练得到的Mini-EfficientDet模型作为主干模型。在训练过程中,首先冻结该模型中浅层网络的权重参数,然后随机初始化修改后的子网络层。在自制数据集上单独训练模型中的任务子网络。训练过程中,确保使用的参数均小于初次训练模型时(使用数据集训练时)的参数。采用学习率较小的随机梯度下降法(SGD)和较小的批量大小进行训练。通过多次训练修改参数,并保证每次参数更新的幅度较小,有助于模型对自制数据集进行学习。最终得到的训练数据的学习率为0.0001,训练轮次设置为50轮,调节因子γ为2,平衡因子α为0.25。
- 测试迁移后的模型精度。

相关代码示例:
# 构建分类子网络
classification_layer = tf.keras.layers.Dense(3, activation='softmax', name='classification')(backbone_model.output)
# 构建回归子网络
regression_layer = tf.keras.layers.Dense(9, activation='linear', name='regression')(backbone_model.output)
# 创建微调模型
model = tf.keras.Model(inputs=backbone_model.input, outputs=[classification_layer, regression_layer])
# 编译模型
optimizer = SGD(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss=['categorical_crossentropy', 'mse'], metrics=['accuracy'])
# 在自制数据集上进行微调训练
train_dataset = prepare_train_dataset() # 准备自制数据集训练数据
num_epochs = 50
batch_size = 32
model.fit(train_dataset, epochs=num_epochs, batch_size=batch_size)
# Step 4: 测试迁移后的模型精度
test_dataset = prepare_test_dataset() # 准备测试数据集
results = model.evaluate(test_dataset, batch_size=batch_size)
print('Test accuracy:', results[1])海浪学长项目示例:





最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









