







这里写自定义目录标题
git 文件存储位置
想要了解如何存储,首先需要知道存储位置。
当我们通过 git init 创建 git 仓库时,会创建.git 目录,.git 的目录结构如下:
├─hooks
├─info
├─logs
│ └─refs
│ ├─heads
│ └─remotes
│ └─origin
├─objects
│ ├─07
│ ├─13
│ ├─2b
│ ├─2d
│ ├─3b
│ ├─5a
│ ├─5e
│ ├─7e
│ ├─94
│ ├─fa
└─refs
├─heads
├─remotes
│ └─origin
└─tags
其中 objects 目录中存储了所有的 git 对象,也是直接涉及数据文件存储的目录,其他目录在此不做讨论。
那么,想要了解 objects 目录中如何存储文件,就需要首先了解 git 的数据模型。
git 数据模型
git 数据模型分为三种:
- blob 对象:存储文件数据,一个 blob 对象代表一个文件数据
- tree 对象:存储文件和子目录的目录对象
- commit 对象:也即快照,包含两个指针,分别指向 parent 以及 tree,此外还有作者以及提交信息
通过伪代码来认识这三个对象
type blob = array<byte>
type tree = map<string, tree|file>
type commit = struct {
parent: array<commit>
author: string
message: string
snapshot: tree
}
示例分析
使用我本地的一次提交为例,分析一下这三种对象的效果。
分析前准备
命令
分析过程主要使用到两条命令。
-
git 中提供了 git cat-file 用来查看 git 对象,分析时主要使用的参数有:
- -t 查看对象的类型
- -p 查看对象的具体内容
-
git 还有 git log 可以查看提交记录,快速找到 commit 对象。
哈希值
git 在存储文件/目录之前,会首先根据文件/目录计算 40 位哈希值。其中:
- 前两位为子目录
- 后三十八位为文件名称
git 存储信息时以该哈希值做索引,而不是文件名。
哈希值通过 SHA-1 计算得出。
具体示例
- 首先通过 git log 获取提交历史
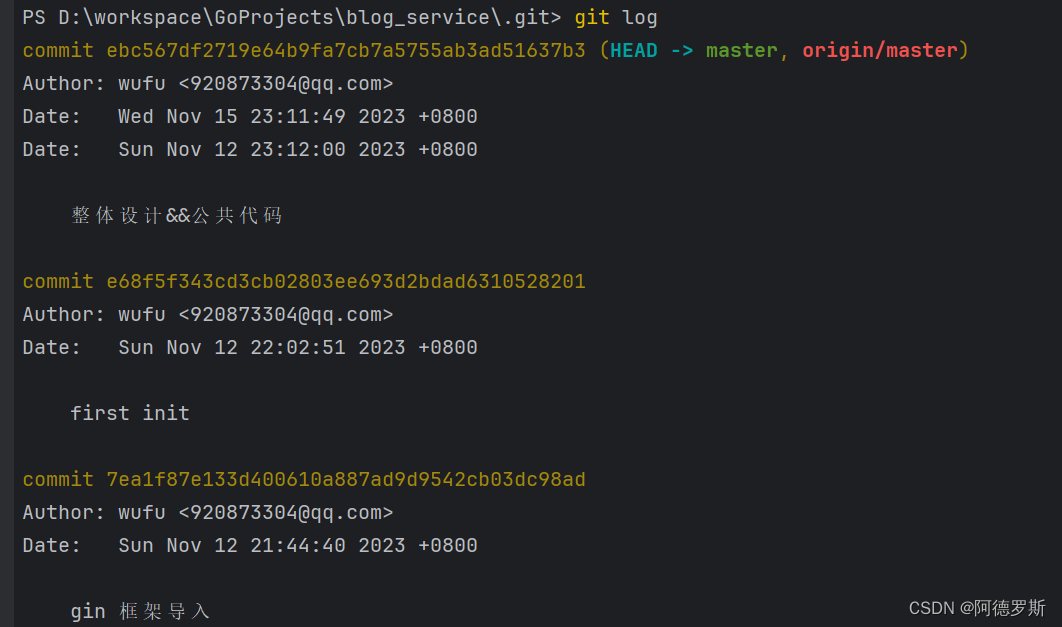
可以看到最初的一次提交对应的 commit 对象为 7ea1f87e133d400610a887ad9d9542cb03dc98ad。 - 查看 commit 对象
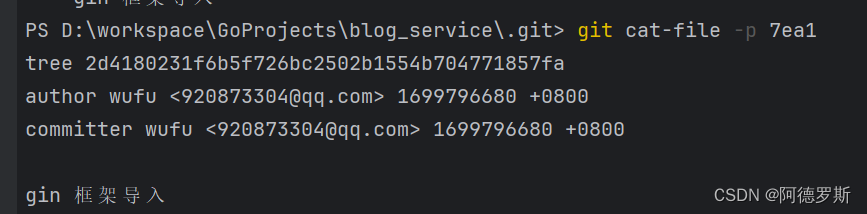
可以看到 commit 对象中包含了 tree 指针、作者、提交者、提交信息等内容,由于第一次提交,所以并没有 parent 指针。 - 查看 tree 对象

可以看到,该 tree 对象下还有一个 tree 对象以及三个文件 blob 对象。 - 查看 blob 对象
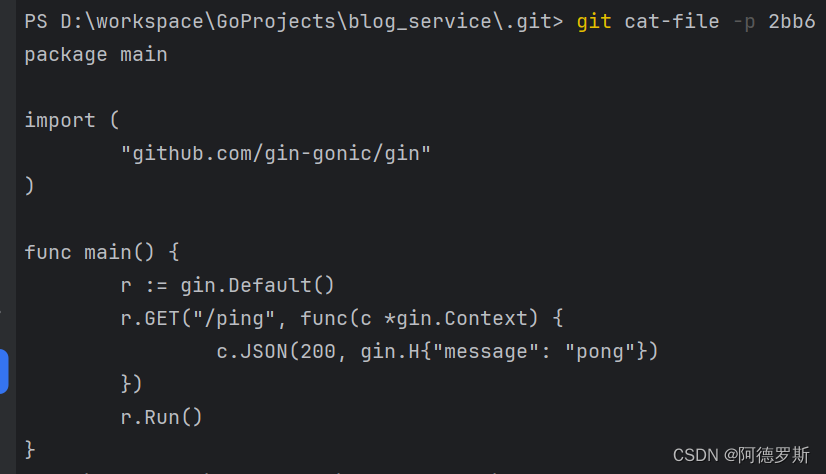
可以看到是一个非常简单的 go 文件。 - 查看第二次提交对象

此处已经有 parent 对象,指向了第一次提交 commit 对象。
通过上述过程,我们大体可以得出以下结论:
- commit 对象以链式结构串联,代表了不同提交的版本信息
- commit 对象中保留的 tree 对象包含了当前仓库的全部信息
不同版本的提交,git 做了什么工作?
以下图为例,数据库代表 commit 对象,目录代表 tree 对象,文件代表blob 对象。该图代表的场景为:
- 第一次提交时,commit1 对象指向 tree1 对象,tree1 对象中包含了 blob1对象以及 tree1-1对象。
- 第二次提交时,仅仅改变了 blob1 所代表的文件内容,其余并没改动。
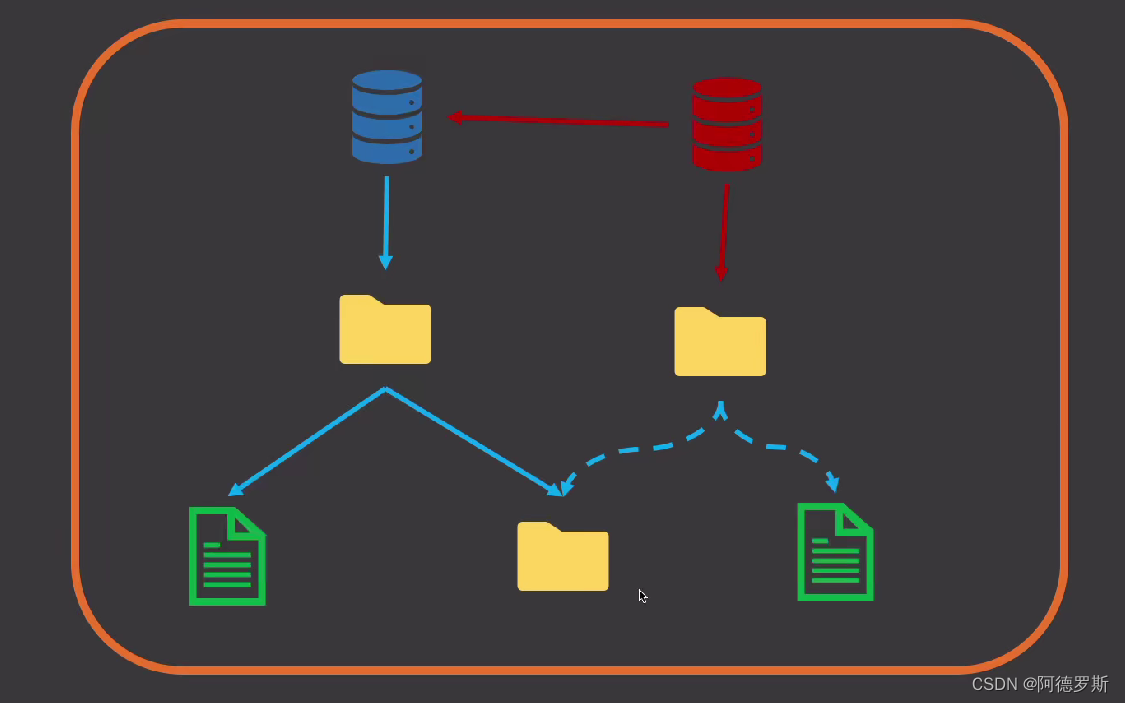
从中可以看到,当第二次提交时, commit 对象(commit2)下创建一个新的 tree 对象(tree2)。对于第二次提交而言,tree1-1并未改动,因此 tree2 直接使用指针指向原有地址,blob1发生变动,则生成一个新的 blob 对象(blob2),并让 tree2 指向它。
完成上述操作后,commit2 对象包含了当前仓库的所有信息,这也就是当前时刻的 snapshot。
snapshot vs delta-based vs backup
对三者做一个简易对比。
- snapshot 基于快照,
- 每次记录当前时刻仓库状态
- 获取当前版本信息,直接获取,因为每个版本都拥有整个仓库的所有信息
- delta-based 基于差异,
- 每次更新记录该版本和上个版本的差异,
- 想获取当前版本信息,需要进行差异计算。
- backup 备份
- 最原始的管理方法,每做一次改动,将代码全量备份到另一个位置
- 找某个版本数据,手动查找,无法(很难)得知版本差异。
参考资料
- https://cloud.tencent.com/developer/article/1923502
- git book














 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









