







Chp1.1-numpy基础
1.NumPy是用于科学计算的一个开源Python扩充程序库,它为Python提供了高性能的数组与矩阵运算处理能力.NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库处理这些数组。它将常用的数学函数都支持向量化运算,使得这些数学函数能够直接对数组进行操作,将本来需要在Python级别进行的循环,放到C语言的运算中,明显地提高了程序的运算速度。
2.pandas库大量依赖NumPy数组来实现其Series以及DataFrame对象。
NumPy同时也支持分片(slice )以及向量化操作。
所以我们在学习pandas前先来了解一下NumPy。
- 任意维数的数组对象(ndarray)
- 通用函数对象(ufunc)
基础ndarray
import numpy as np#导入Numpy库并取一个别名为np
4.NumPy的核心功能是"ndarray"(即多维数组),特点:
- 连续内存分配
- 向量化操作
- 布尔选择
- 分片(sliceability)
ndarray.ndim:数组轴的个数(秩)
ndarray.shape:数组的维度。shape属性(2,3)表示2排3列的矩阵。这个元组的长度显然是秩。
ndarray.size:数组元素的总个数,等于shape属性中元组元素的乘积。
ndarray.dtype:一个用来描述数组中元素类型的对象
ndarray.itemsize:数组中每个元素的字节大小。float64的数组itemsiz属性值为8(=64/8)
ndarray.data:包含实际数组元素的缓冲区
6.#创建ndarray,可以将普通的python列表转换成ndarray
t =[1,2,3,4,5]
X = np.array( t )
X
得到:array([1, 2, 3, 4, 5])
7.#输出x的类型
type(x)
得到:numpy.ndarray
8.#ndim为ndarray数据的维度
x.ndim
得到:1
9.#shape是ndarray数据的形状
x.shape
得到:(5,)
10.#size是ndarray数据里面的元素个数,比如数据是3*3的ndarray矩阵,那么size就是9
x.size
得到:5
11.#ndarray数据在内存当中的存放地址
x.data
得到:<memory at 0x0000015EC5266640>
12.#定义一个二维矩阵,下面的写法是用一个python列表转化成二维矩阵
#原始python列表是拥有2个子列表,每个子列表拥有5个元素
y=np.array([[1,2,3,4,5],[6,7,8,9,10]])
y
得到:array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
y.ndim:2、y.shape:(2,5)、y.size:10、np.size(y,0):2、np.size(y,1):5
创建 ndarray
1.#python列表转化为ndarray
#在python中*符号在列表表示为重复运算符
ee =[1]*5 #ee为[1,1,1,1,1]
x2=np.array(ee)
x2
得到:array([1, 1, 1, 1, 1])
2.#使用numpy的zeros方法生成若干个全是0的ndarray
np.zeros(10)
得到:array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
3.#使用python的整数列表生成器range生成整数列表(0-10,包括0,不包括10),再转化为ndarray
np.array(range(10))
得到:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
4.#使用python的整数列表生成器range生成整数列表(0-10,包括0,不包括10,数据之间间隔2),再转化为ndarray
np.array(range(0,10,2))
得到:array([0, 2, 4, 6, 8])
5.#使用python的整数列表生成器range生成整数列表(10-0,包括10,不包括0,数据递减1),再转化为ndarray
np.array(range(10,0,-1))
得到:array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
6.#使用numpy的等差数组生成器linspace生成整数数据(0-10,0开始,10结束,等分5段)
np.linspace(0,10,5)
得到:array([ 0. , 2.5, 5. , 7.5, 10. ])
7.#numpy的zeros方法生成全是0的ndarray数据,多维时需要将各个维度用()包裹
np.zeros((2,3))
得到:array([[0., 0., 0.],
[0., 0., 0.]])
8.#numpy的ones方法生成全是1的ndarray数据,多维时需要将各个维度用()包裹
np.ones((2,3,4),dtype=int)
得到:array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
9.#numpy的random.random方法生成随机数,随机数时都是从0-1中随机的浮点数
np.random.random(10)
得到:array([0.67332366, 0.78953161, 0.72219261, 0.80940748, 0.39322915,
0.09178667, 0.23835737, 0.56058627, 0.85657035, 0.93009838])
10.#numpy的random.randint方法生成随机整数,如下面的案例从0到5之间生成10个随机数#不包括右边
np.random.randint(0,5,10)
得到:array([4, 4, 2, 1, 2, 3, 3, 4, 2, 3])
11.#python自带的randomint 包括右边
import random
for i in range(10):
print(random.randint(0,5))
得到:
3
0
3
1
4
4
5
2
1
3
12.#numpy的数据生成和处理支持链式调用,可以将多步操作写在一行,reshape是变形函数,之后有详解
x2 = np.arange(0, 12).reshape(4, 3)
x2
得到:array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
选择数组中元素
1.#使用切片选取对应位置的元素,一维场景x array([1, 2, 3, 4, 5])
x[3]
得到:4
2.#二维场景,切片这里相当与使用每个维度的位置坐标y
#array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
y[1,3] y[0,] y[:,1] y[:,1:4]
得到:9 array([1, 2, 3, 4, 5]) array([2, 7]) array([[2, 3, 4],
[7, 8, 9]])
布尔选择器
1.#numpy的ndarray数据类型支持布尔选择器
x = np.array([1,2,3,4,5])
x<3
得到:array([ True, True, False, False, False])
2.#如果要使用多个条件需要每个条件都加()
#以下用法错误
x<2 or x>4
3.# 或运算使用符号 | ,ndarray不支持 or
(x<2) | (x>4)
得到:array([ True, False, False, False, True])
4.#保存布尔选择器的结果
mask = x<3
mask
得到:array([ True, True, False, False, False])
5.#只想得到小于3的数据数据,只需要将布尔选择器的结果当成切片写入即可
x[mask]
得到:array([1, 2])
6.#使用numpy求满足条件的个数
np.sum(x<4)
得到:3
7.#numpy的ndarray数据的加减乘除运算是矩阵运算,也就是对应坐标位置的对应数学运算
a1 = np.arange(9).reshape(3, 3)
a2 = np.arange(9, 0 , -1).reshape(3, 3)
print(a1)
print(a2)
#2个ndarray数据比较对应位置的数据大小
a1 < a2
得到:
[[0 1 2]
[3 4 5]
[6 7 8]]
[[9 8 7]
[6 5 4]
[3 2 1]]
array([[ True, True, True],
[ True, True, False],
[False, False, False]])
切片
1.#一维的ndarray和python列表的切片非常相似
x=np.arange(0,10)
x
得到:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
2.#从3取到9的位置,不包括9的位置
x[3:9] x[::2]
得到:array([3, 4, 5, 6, 7, 8]) array([0, 2, 4, 6, 8])
3.#取某些单独项 !!!注意写法,不要遗漏了一组[]
x[[1,2,4]]
得到:array([1, 2, 4])
4.#第二个冒号位置写-1,表示倒叙
x[::-1]
得到:array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
5.#以下是多维ndarray的切片情况,与python多维列表有显著不同,之前有一个案例,可以上翻查看
y=np.arange(0,16).reshape(4,4)
y
得到:array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
6.#逗号左边是选取行,右边是选取列,对应位置不写,则表示不限制
y[:,1:3]
得到:array([[ 1, 2],
[ 5, 6],
[ 9, 10],
[13, 14]])
reshape 变形
1.x=np.arange(0,9)
#将x由一维的变成3*3的形状
y=x.reshape(3,3)
x,y
得到:(array([0, 1, 2, 3, 4, 5, 6, 7, 8]),
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]))
2.#将3*3的形状转成1维度的
#注意这里不要写成了y.reshape(1),原始数据有多少个元素个数,就需要填入多少个,可以使用np.size(y)获取元素个数
y.reshape(9)
得到:array([0, 1, 2, 3, 4, 5, 6, 7, 8])
3.#reshape()方法不会改变原始数据的形状
#注意这里y的形状没有变,如果需要reshape后保存形状结果,则需要用变量保存即可,x= y.reshape(9)
y
得到:array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
4.#ravel()方法就是将数据展成一维的,用法更简洁。ravel同样方法不会改变原始数据的形状
y
y.ravel()
得到:array([0, 1, 2, 3, 4, 5, 6, 7, 8])
合并
1.a = np.arange(9).reshape(3, 3)
b = (a + 1) * 10
a,b
得到:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
array([[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
2.#2个ndarray横向合并
np.hstack((a, b))
得到:array([[ 0, 1, 2, 10, 20, 30],
[ 3, 4, 5, 40, 50, 60],
[ 6, 7, 8, 70, 80, 90]])
3.#2个ndarray竖向合并
np.vstack((a, b))
得到:array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
4.#使用concatenate可以根据参数,完成对应方向的合并
np.concatenate((a, b), axis = 0)//axis=1时同hstack
得到:array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
5.#根据2个ndarray的相同坐标位置进行合并
np.dstack((a, b))
得到:array([[[ 0, 10],
[ 1, 20],
[ 2, 30]],
[[ 3, 40],
[ 4, 50],
[ 5, 60]],
[[ 6, 70],
[ 7, 80],
[ 8, 90]]])
matrix
1.x = np.array([1,5,2])
y = np.array([7,4,1])
x + y
得到:array([8, 9, 3])
2.x * y
得到:array([ 7, 20, 2])
3.x - y
得到:array([-6,1,1])
4.x / y
得到:array([0.14285714, 1.25, 2.])
5.x % y 得到:array([1, 1, 0], dtype=int32)
通用函数
1.#平均值,标准差,方差
a = np.arange(1,10)
a.mean(), a.std(), a.var()
得到:(5.0, 2.581988897471611, 6.666666666666667)
2.#sum求和 prod是所有元素的乘积
a.sum(), a.prod()
3.#累计和 累计乘
a.cumsum(), a.cumprod()
Chp2.1-pandas series数据类型
import numpy as np
import pandas as pd
Series
1.Series 是pandas中的两种基础数据结构之一,可以理解为一维带标签数组.
数组中数据可以为任意类型(整数,字符串,浮点数,Python objects等).
数组中数据为同一类型
2.创建Series
建立一个Series
- s = pd.Series(data, index=index)
这里data可以是 - list
- array
- dictionary
3.#将python列表转换成Series
p= [15280,45888,15692,55689,28410,27566]
print§
#Series是一维的带标签的数组,标签如果没有指定,则默认从0开始编号
#这里是编号,可以暂时理解为数字下标,但是最好理解为一个普通的"标签"
price = pd.Series§
price
得到:[15280, 45888, 15692, 55689, 28410, 27566]
0 15280
1 45888
2 15692
3 55689
4 28410
5 27566
dtype: int64
4.#这是pandas的head方法,可以查看开头几项数据,默认5项目,可以传递参数比如head(10)就是看10项
price.head()
得到:
0 15280
1 45888
2 15692
3 55689
4 28410
Name: price, dtype: int64
5.#查看最后的几项数据
price.tail(3)
6.#将python的字典转化为Series,key就当标签用,value就当值用
temp = {‘Mon’: 33, ‘Tue’: 19, ‘Wed’: 15, ‘Thu’: 89, ‘Fri’: 11, ‘Sat’: -5, ‘Sun’: 9}
pd.Series(temp)
得到:
Mon 33
Tue 19
Wed 15
Thu 89
Fri 11
Sat -5
Sun 9
dtype: int64
7.#生成时间类型的数据
x=pd.Series([‘2016-01-01’,‘2017-01-01’])
print(x.dtype)
#字符串类型数据转换成时间类型
pd.to_datetime(x)
得到:object
0 2016-01-01
1 2017-01-01
dtype: datetime64[ns]
布尔选择器
1.#pandas的Series的布尔选择器的用法和numpy的ndarray的布尔选择器用法一致
Price
得到:
0 15280.0
1 45888.0
2 15692.0
3 55689.0
4 28410.0
5 27566.3
dtype: float64
2.#查看price中每个数据是否大于30000,并且将结果保存
#结果就是每个数据的检测状态,这个结果就是布尔选择器
mask = price<30000
print(mask)
得到:
0 True
1 False
2 True
3 False
4 True
5 True
dtype: bool
3.#将布尔选择结果或者条件当切片,即可得到筛选的结果
price[mask]
得到:
0 15280.0
2 15692.0
4 28410.0
5 27566.3
dtype: float64
4.mask2=pd.Series([True,False,True,True,False,True])
#布尔选择器“或”操作,使用|符号
mask | mask2
得到:
0 True
1 False
2 True
3 True
4 True
5 True
dtype: bool
5.#布尔选择器 且 操作,使用&符号
mask&mask2
#布尔选择器求反操作,使用~符号
~mask
6.# 注意在python的变量中 "或"操作可以使用 or 或者 "|"符号都可以,建议使用 or "且"操作可以使用 and 或者 "&"符号都可以,建议使用 and 求反操作使用not,不能使用~符号
t1= True
t2= False
print(t1 | t2)
print(t1 or t2)
print(t1 & t2)
print(t1 and t2)
#print(~t1) #出错
#这里注意常规python的列表没有布尔操作
temp = [True,False,True,True,False,False]
temp2 = [True,False,True,True,False,False]
temp & temp2 #出错
7.#多个条件同样需要将每个条件都用()符号包裹,以下是错误写法
price>20000&price<30000
8.#多个条件同样需要将每个条件都用()符号包裹
m = (price>20000)&(price<30000)
price[m]
得到:
4 28410.0
5 27566.3
dtype: float64
索引 index
1.price = pd.Series([15280,45888,15692,55689,28410,27566.3])
Price
#在上面的数据中,标签没有单独指定,默认从0开始编号,可以使用数字标签找到对应元素
price[2]
得到:15692.0
2.price = pd.Series([15280,45888,15692,55689,28410,27566.3],index=[‘wh’,‘sh’,‘hz’,‘bj’,‘gz’,‘nj’])
Price
得到:
wh 15280.0
sh 45888.0
hz 15692.0
bj 55689.0
gz 28410.0
nj 27566.3
dtype: float64
3.#在上面的数据中,使用index参数指定了标签,可以使用指定的标签找到对应元素
price[‘sh’]
#在上面的案例中,标签都是字符串,没有数字标签,所以也可以使用位置来找到元素
price[1]
得到:45888.0 45888.0
4.#查看所有的标签
price.index
得到:Index([‘wh’, ‘sh’, ‘hz’, ‘bj’, ‘gz’, ‘nj’], dtype=‘object’)
5.#定义日期类型的数据,以月为单位
dates=pd.date_range(‘2016-01-01’,‘2016-6-01’,freq=‘M’)
dates
得到:DatetimeIndex([‘2016-01-31’, ‘2016-02-29’, ‘2016-03-31’, ‘2016-04-30’,
‘2016-05-31’],
dtype=‘datetime64[ns]’, freq=‘M’)
6.#将上面定义的时间数据当标签
tempature=pd.Series([13,15,20,27,29],index=dates)
tempature
得到:
2016-01-31 13
2016-02-29 15
2016-03-31 20
2016-04-30 27
2016-05-31 29
Freq: M, dtype: int64
7.#人为定义一些数字形式的标签
temp=pd.Series([13,15,20,27,29],index=[0,2,2,3,4])
temp
#所以这里可以看出一个index的细节
得到:
0 13
2 15
2 20
3 27
4 29
dtype: int64
8.#在标签是纯数字或者字符串、数字混用这种情况下,切片就只能当标签用,如以下写入1就会报错
#因为1当标签用,上面的数据没有标签为1的数据,所以找不到就报错,而不是把1当位置用
temp[1] #出错
索引/切片
1.temp=pd.Series([13,15,20,27,29])
#使用loc方法,里面传入的数据强制当标签(也就是index索引)用
temp.loc[0]
得到:13
2.#loc方法是取索引而不是取位置,所以没有-1这种尾巴位置
temp.loc[-1] #想找倒数第一个位置,报错
3.#使用iloc方法,传入的参数,强制当位置用
temp.iloc[-1] #这是-1就是倒数第一个位置,就不会报错
4.#iloc就是数字切片,选取0,1,2这个位置
temp.iloc[0:3]
得到:
0 13
1 15
2 20
dtype: int64
5.temp=pd.Series([13,15,15,15,20,27,29],index=[‘M n’,‘T’,‘T’,‘T’,‘W’,‘T’,‘F’])
temp[‘M n’] ,temp[0]#如果index是非数字型的,那么标签和位置法都可以运行
得到:13,13
6.#使用标签选取元素,可以使用.方法,但是.方法有很大的限制,其中一个就是不支持标签之中有空格
temp.M n #报错
7.#使用标签切片可以正确找到标签是T的数据
temp[‘T’]
得到:
T 15
T 15
T 15
T 27
dtype: int64
8.#但是使用.方法就不能正确获取,
#因为容易和内置方法冲突,.T这里就变成了矩阵转置操作了
temp.T #transpose, check with dir(temp)
修改与删除Series中的值
定义price
city
wh 15280.0
sh 45888.0
hz 15692.0
bj 55689.0
gz 28410.0
nj 27566.3
dtype: float64
1.#找到标签的元素 直接修改
price[‘wh’]=16000
price
price.iloc[0]=15280
Price
2.#使用append方法也可以新增元素
price.append(pd.Series([9500],index=[‘cd’])) #!!!注意返回的是一个新Series
print(price)
得到:
city
wh 15280.0
sh 45888.0
hz 15692.0
bj 55689.0
gz 28410.0
nj 27566.3
dtype: float64
3.#如果这个标签在原始数据中没有,就是新增数据
price[‘xian’]=5000
Price
得到:
city
wh 15280.0
sh 45888.0
hz 15692.0
bj 55689.0
gz 28410.0
nj 27566.3
xian 5000.0
dtype: float64
4.#使用del方法删除对应标签的元素
del price[‘xian’]
数据分析
1.#pandas是基于numpy封装的,继承了numpy的数据计算方法,如:
#求和
price.sum()
#平均数
price.mean()
#最小值
price.min()
#最大值
price.max()
#中位数
price.median()
2.#使用describe()可以查看数据的大致情况,其中如25%就是数据大于25%整体数据时的数据大小
#比如15383大于25%的数据,41518大于50%的数据
price.describe()
得到:
count 6.000000
mean 31420.883333
std 16310.046401
min 15280.000000
25% 18660.575000
50% 27988.150000
75% 41518.500000
max 55689.000000
dtype: float64
3.#统计出现数据的个数
temp.value_counts()
得到:
15 3
13 1
20 1
27 1
29 1
dtype: int64
向量化操作与广播
1.#pandas的Series数据和numpy的ndarray一样,数据运算属于矩阵运算,对应坐标位置进行数据运算
price * 2
得到:
city
wh 30560.0
sh 91776.0
hz 31384.0
bj 111378.0
gz 56820.0
nj 55132.6
dtype: float64
2.uuu= [1,2,3]
ppp = [2,3,4]
#np.array(uuu)+np.array(ppp)
pd.Series(uuu)+pd.Series(ppp)
3.price+1000 #+,-,/,*
4.s=pd.Series([10,20,30,40])
s2=pd.Series([10,20,30],index=[2,3,4])
#两个Series根据对应的标签进行运算,如果有1个Series的某个标签在另一个Series中没有,那么运算结果就是NaN(not a number )#NaN 在pandas里面表示不是一个数字
s+s2
得到:
0 NaN
1 NaN
2 40.0
3 60.0
4 NaN
dtype: float64
iteration
1.#Series支持for循环迭代
s=pd.Series([10,20,30,40])
print(s)
for num in s:
print(num)
得到:
0 10
1 20
2 30
3 40
dtype: int64
10
20
30
40
In [76]:
2.#查看40是否在s的标签中
40 in s
得到:False
3.#查看40是否在s的数据中
40 in s.values
得到:True
4.#0是否在数据的标签中
0 in s #why? series是key-value存储,所以这里实际是index o
得到:True
5.li=[10,20,30,40]
40 in li
得到:True
6.# Series的迭代和python的字典用法一致
for k,v in price.items():
print(k,v)
得到:
wh 15280.0
sh 45888.0
hz 15692.0
bj 55689.0
gz 28410.0
nj 27566.3
Chp2.2-pandas data frame 数据类型
import numpy as np
import pandas as pd
1.#设置默认数据显示的最大行和列的数量
pd.set_option(‘display.max_columns’, 10)
pd.set_option(‘display.max_rows’, 10)
creation np.array, dict
1.#DataFrame就是具有行标签和列标签的数据
#python列表转成DataFrame
ff = [
[10,20],
[30,40]
]
df1=pd.DataFrame(ff)
df1
得到:
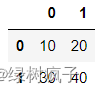
2.#可以将多个Series类型数据转成DataFrame
dd1 = pd.Series(np.arange(1, 8))
dd2 = pd.Series(np.arange(11, 18))
df3 = pd.DataFrame([pd.Series(np.arange(1, 8)),pd.Series(np.arange(11, 18))])
df3
得到:

3.#查看形状(维度)2行 7列
df3.shape
得到:(2, 7)
4.#使用index设置行标签,columns设置列标签
nn = np.array([[10,20],[30,40]])
df3=pd.DataFrame(nn,index=[‘a’,‘b’],columns=[‘c1’,‘c2’])
df3
得到:

5.#查看行标签、查看列标签
df3.index
df3.columns
得到:Index([‘a’, ‘b’], dtype=‘object’)
Index([‘c1’, ‘c2’], dtype=‘object’)
6.#标签也是一组列表,可以使用切片查看某些标签
df3.columns[1]
得到:‘c2’
7.#修改列标签,用这种方式修改标签,必须全部标签统一修改,不能只修改其中的一部分
df3.columns=[‘column1’,‘column2’]
df3

s1 = pd.Series(np.arange(1, 9, 2))
s2 = pd.Series(np.arange(2, 10, 2))
#用字典的形式创建DataFrame,字典的key当列标签用
df4=pd.DataFrame({‘c1’: s1, ‘c2’: s2})
df4
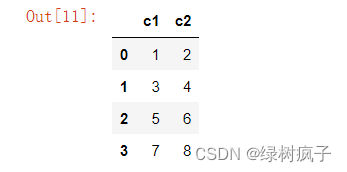
9.s3 = pd.Series(np.arange(5, 7), index=[1, 2])
s3

10.#多个Series一起创建DataFrame时,根据标签情况进行数据的分布,比如s3没有0和3位置的行,那么数据就是NaN
df5 = pd.DataFrame({‘c1’: s1, ‘c2’: s2, ‘c3’: s3})
df5
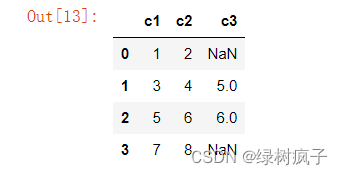
csv
1.#使用read_csv读取文件,使用read_csv方法也可以读取txt和exl格式的数据
#默认将第一行作为列标签,但是不会将第一列作为行标签,读取文件时使用index_col参数可以指定某列做行标签
eu12=pd.read_csv(‘…/data/Eueo2012.csv’,index_col=‘Team’)
2.#使用head()方法查看数据前若干行数据,默认5行
eu12.head(8)
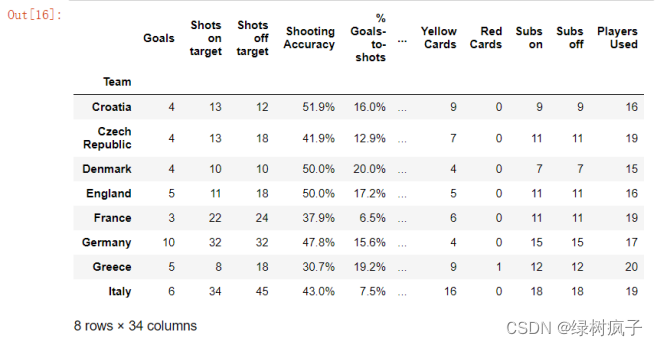
3.#使用tail()方法查看数据最后若干行数据,默认5行
eu12.tail(8)
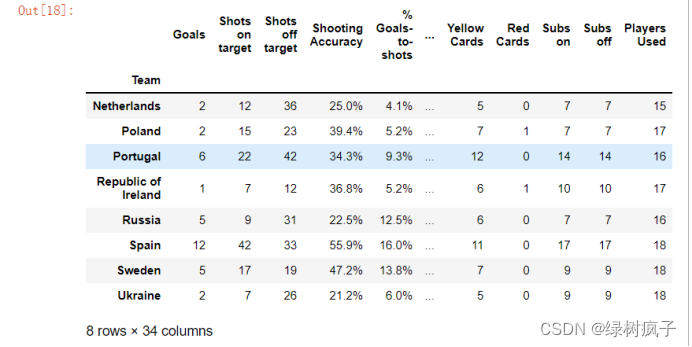
4.#查看数据的个数,这里用len查看行数,并不是指里面数据的单元格元素总数
len(eu12)
得到:16
5.#查看数据的形状 16行34列
eu12.shape
得到:(16, 34)
6.#查看元素有多少行
eu12.shape[0]
得到:16
7.#查看元素有多少列
eu12.shape[1]
得到:34
选择列
1.# 使用iloc。用位置做为切片,可以同时选择行和选择列,
eu12.iloc[1:4, 1:3].head()
#使用iloc时,数据不包括右侧数据
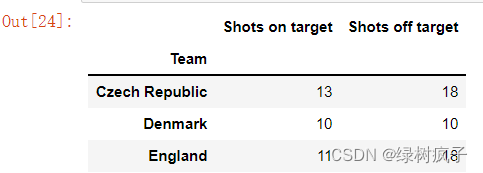
2.#使用标签时,是以列标签做为切片,以下案例是只选取’Shots on target’,'Shots off target’这两列数据
eu12[[‘Shots on target’,‘Shots off target’]].head()
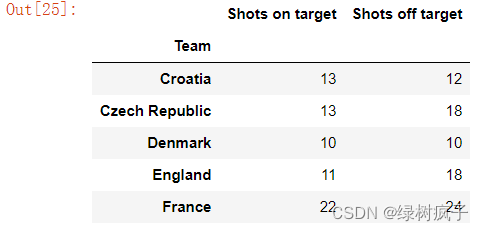
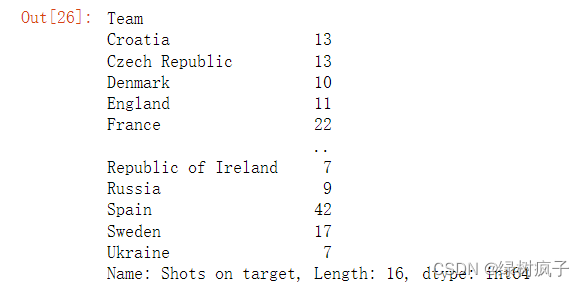
3.#使用标签时,是以列标签做为切片,以下案例是只选取’Shots on target’,这一列数据
eu12[‘Shots on target’]
4.#使用loc方法选择数据,可以同时使用行标签和列标签选择数据,注意写法,以下案例是单独选择标签
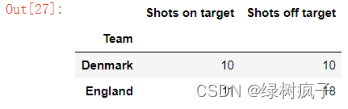
eu12.loc[[“Denmark”,“England”],[‘Shots on target’,‘Shots off target’]]
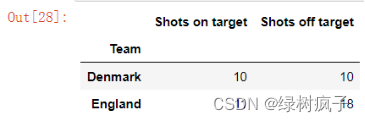
5.#以下案例是使用标签范围,比如行选择Denmark到England之间的数据,列选择s_on_targets到s_off_targets之间的数据
#使用loc时,数据包括右侧数据
eu12.loc[“Denmark”:“England”,‘Shots on target’:‘Shots off target’]
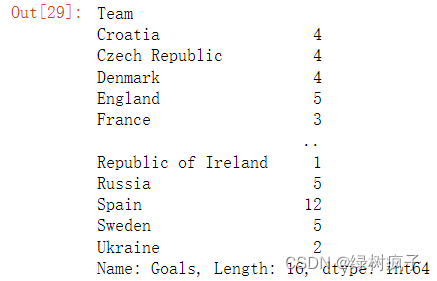
6.#使用.方法可以选择某个列,虽然这种方式不推荐,原因可以去翻翻Series那一节
eu12.Goals
#注意:这种用法是不推荐的
选择行
用[]分片选行
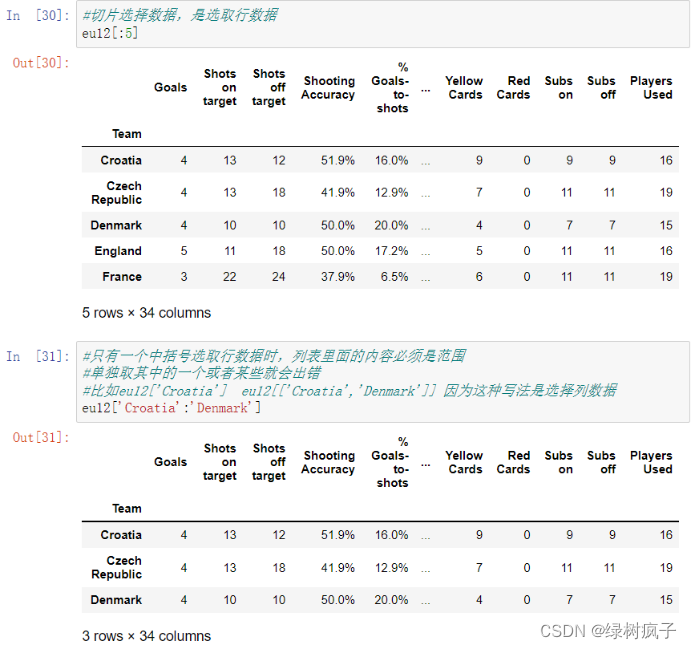
.loc[], .iloc[]
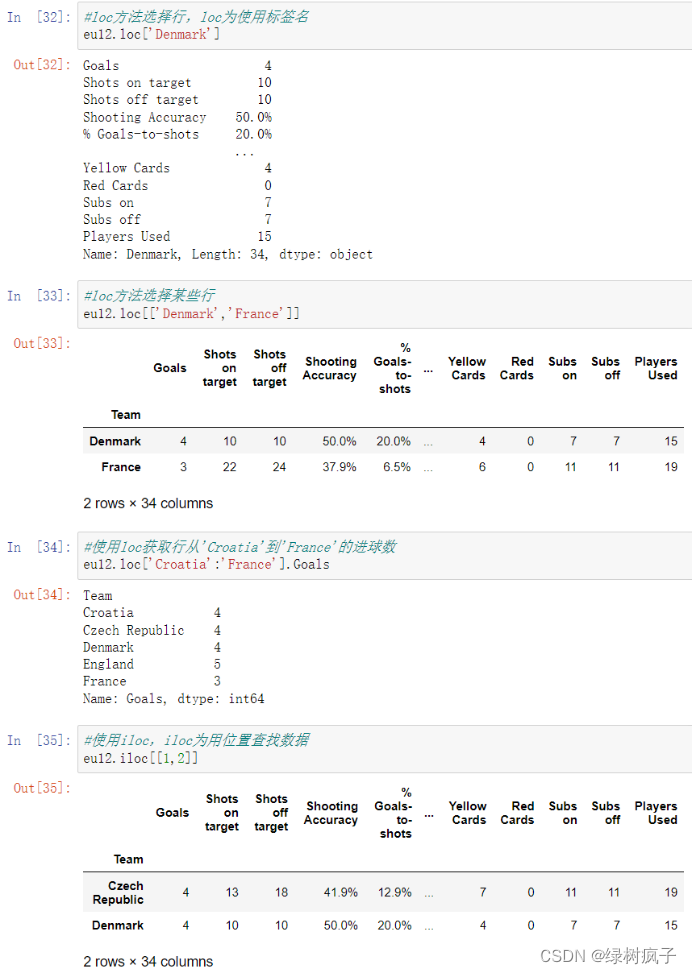
布尔选择器
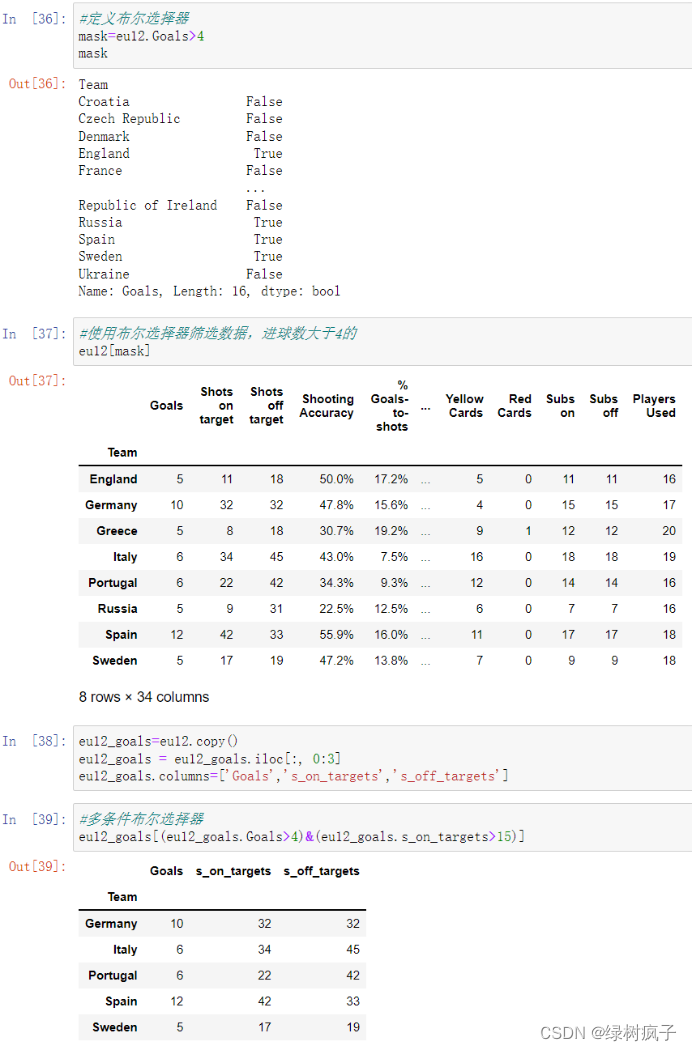
修改dataframe
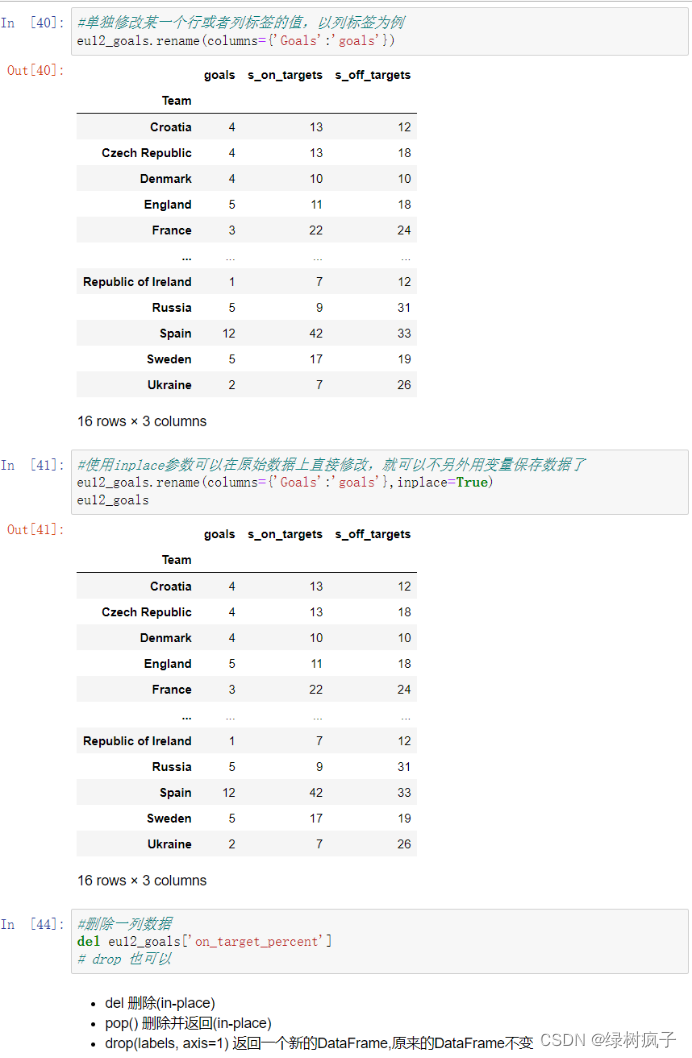
添加行
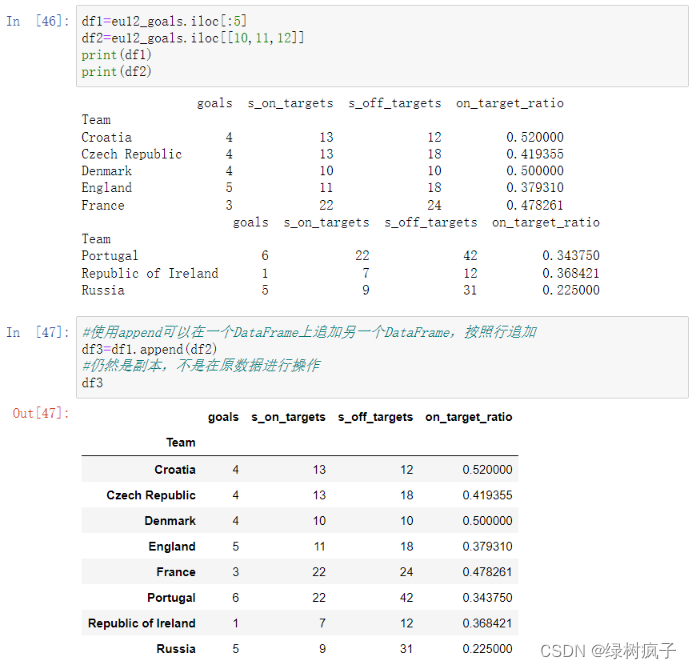
reset index
1.sp500=pd.read_csv(‘…/data/sp500.csv’)
sp500
2.#将Symbol列作为行标签(行索引)
sp500=sp500.set_index(‘Symbol’)
sp500.head()
3.#此时可以用行标签ACE找到对应行数据
sp500.loc[‘ACE’]
4.#使用reset_index可以将行标签取消,回到默认按照0开始编号
sp500=sp500.reset_index()
sp500.head()
5.#此时 ACE就不是行标签了,就找不到数据,报错
sp500.loc[‘ACE’]
sorting & filtering
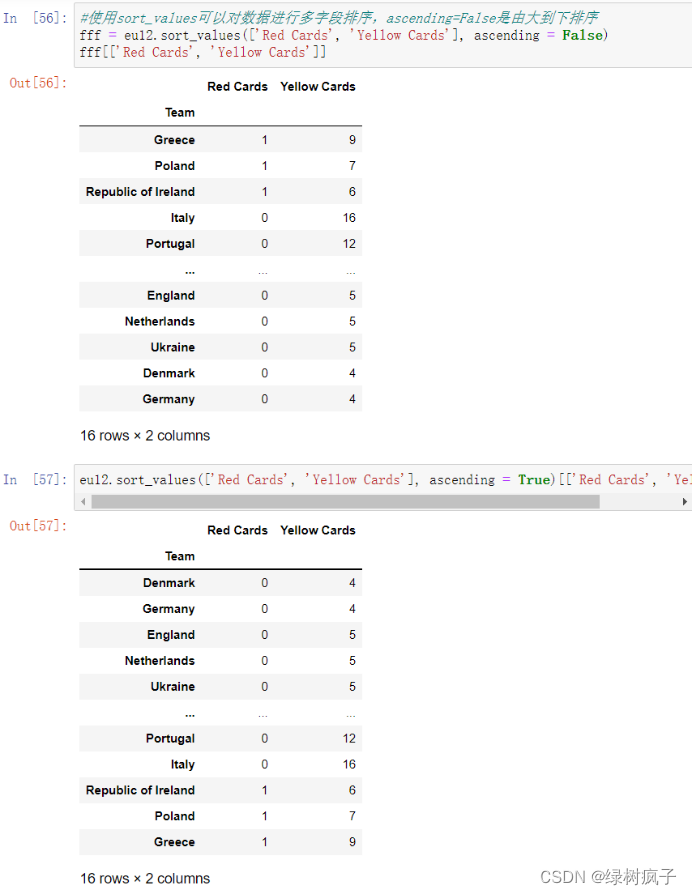
Chp2.3-pandas读写csv txt exl文档
读
- read_csv
- read_excel
- read_hdf
- read_sql
- read_json
- read_msgpack (experimental)
- read_html
写
- to_csv
- to_excel
- to_hdf
- to_sql
- to_json
- to_msgpack (experimental)
- to_html
其它数据源:
- 数据库
- 读取网页数据,网络文件
- 读取股票数据
- yahoo,世界银行等等
import numpy as np
import pandas as pd
csv, txt
1.#使用read_csv读取文件,使用read_csv方法可以读取txt和exl格式的数据
#默认将第一行作为列标签,但是不会将第一列作为行标签,读取文件时使用index_col参数可以指定某列做行标签
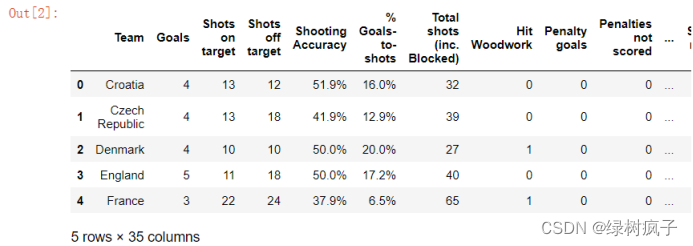
eu12=pd.read_csv(‘…/data/Eueo2012.csv’)
eu12.head()
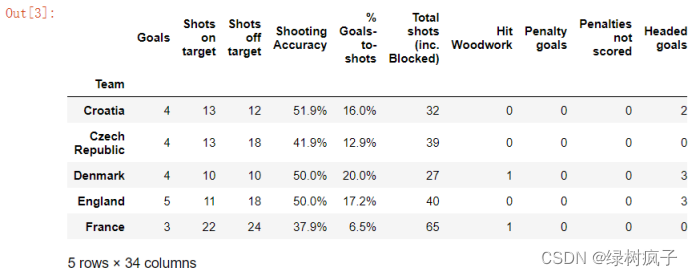
2.#可以使用index_col后面跟列的位置来指定行标签,在上一节2.3节文档中,使用index_col=‘Team’,通过列名指定行标签
eu12=pd.read_csv(‘…/data/Eueo2012.csv’,index_col=0)
eu12.head()
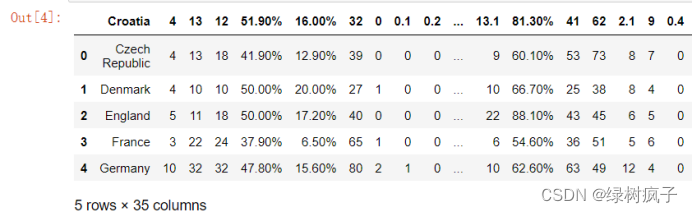
3.#读取了一个第一行是普通数据的文档,但是默认仍然将第一行作为列标签,很明显这样不太合适
eu12_header=pd.read_csv(‘…/data/Eueo2012_no_header.csv’)
eu12_header.head()
4.#可是使用参数header=None,这样就不会将第一行作为列标签了,此时列标签从0自动分布
eu12_header=pd.read_csv(‘…/data/Eueo2012_no_header.csv’,header=None)
eu12_header.head()
5.#将数据写入文档
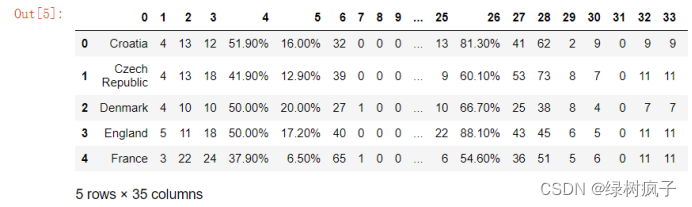
eu12.to_csv(‘…/data/Eueo2012_save.csv’)
进阶
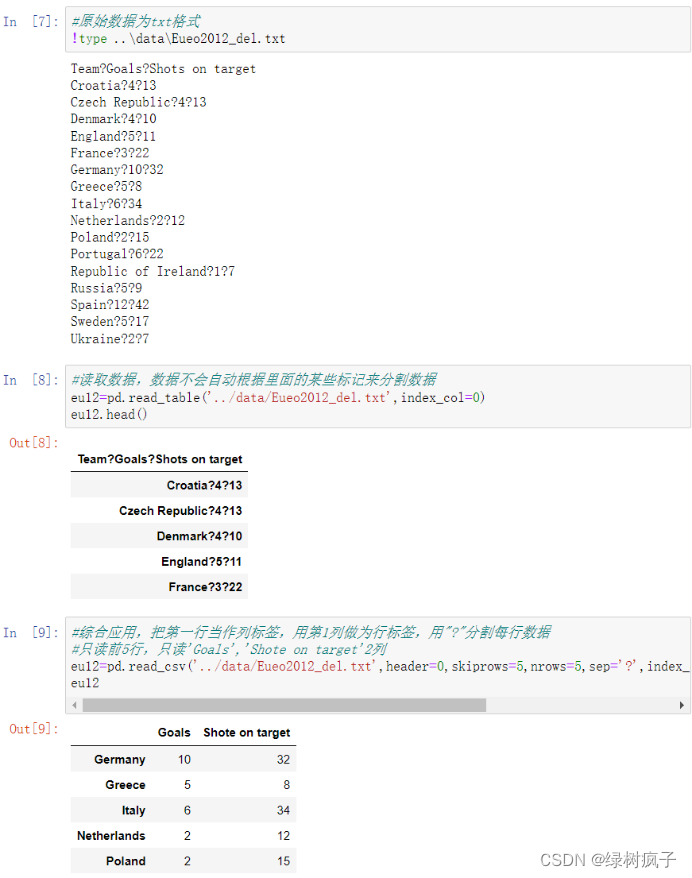
eu12=pd.read_csv(‘…/data/Eueo2012_del.txt’,header=0,skiprows=5,nrows=5,sep=‘?’,index_col=0,names=[‘Goals’,‘Shote on target’])
Excel
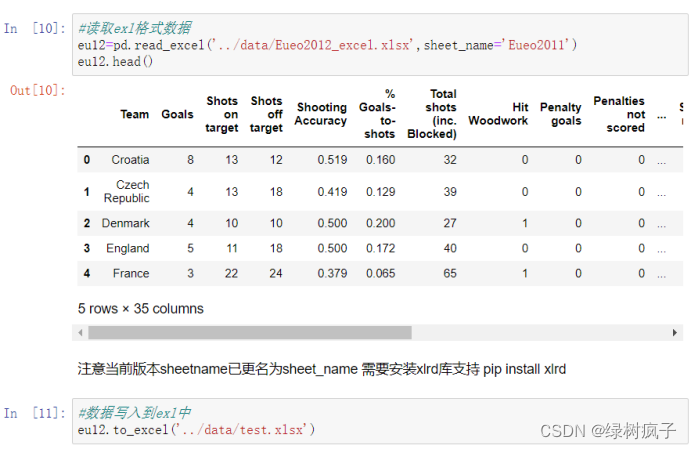















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









