






FLUX.1 模型的发布迅速走红全球,生成的图像质量超越了现有的开源模型,且支持通过简单操作进行微调,无需编程知识。Replicate 上已有数百个公开的 Flux 微调,还有数千个私有微调。
Flux 的一大亮点是能够微调面部图像,这是以前的开源模型(如 Stable Diffusion 或 SDXL)难以实现的功能。自 Dreambooth 以来,能够通过少量训练图像获得出色结果的微调方式再也没有如此简单。
本文将详细介绍如何在 Replicate 平台上使用自己的照片微调 FLUX.1 训练一个图像模型,生成各种风格的图片,如超级英雄、卡通角色或冒险者形象等。
关键步骤包括:
-
准备训练图片:至少10张不同角度和光线条件下的高质量面部照片。 -
选择触发词:创建一个唯一的“触发词”用于激活模型。 -
创建并训练模型:在 Replicate 上上传图片和触发词,训练大约需要 20 分钟。 -
生成图像:使用训练后的模型生成带有触发词的详细描述文本。

步骤 0: 准备工作
在开始微调 FLUX.1 模型之前,你需要准备:
-
一个 Replicate 账户 -
几张自己的照片 -
2-3 美元的模型训练费用
步骤 1: 收集训练图片
你需要收集几张自己的照片,推荐至少 10 张高质量面部照片,但最少需要 2 张。
图片要求:
-
格式:WebP、JPG、PNG -
分辨率: 1024×1024 或更高 -
文件名:随意命名,不影响训练 -
建议最少 10 张,图片越多效果越好 -
图片多样化:不同背景、服装、灯光和角度
准备步骤:
-
将图片存放在一个文件夹中,如 data。 -
将文件夹压缩为 .zip文件,命名为data.zip。

步骤 2: 选择唯一的触发词
微调 FLUX.1 模型时,需要选择一个唯一的触发词,后续生成图像时将使用它。
触发词要求:
-
独特,类似于 MY_UNIQ_TRGGR -
不应是现有的语言词汇,如 dog或cyberpunk -
不使用 TOK,以避免与其他微调冲突
例如,作者选择了 ZIKI 作为触发词。你可以根据个人喜好选择一个类似的唯一词。
步骤 3: 创建并训练模型
接下来,你将在 Replicate 平台上上传图片并开始训练。
网页训练步骤:
-
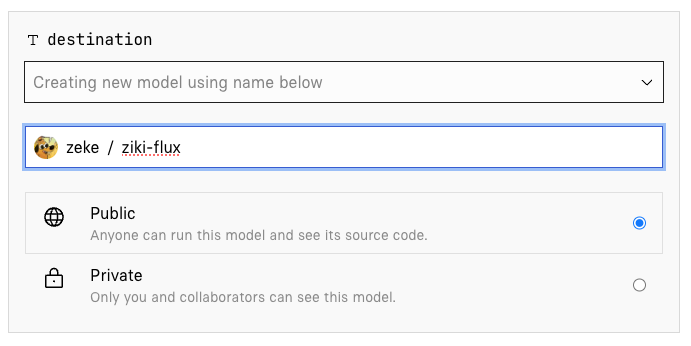
访问 Flux 微调表单。 -
选择模型发布位置:可以选择发布为公共或私有。 -
上传训练图片:在 input_images字段中,上传data.zip文件。 -
输入触发词:在 trigger_word字段中,输入之前选择的触发词。 -
选择训练步数:默认1000步,建议不要低于此步数。 -
点击 Create training 开始训练。
步骤 4: 等待训练完成
训练大约需要 20 分钟。在这期间,你可以休息片刻,等返回时模型就准备好了。
步骤 5: 使用网页生成图像
训练完成后,你可以通过网页表单生成图像:
-
访问 Replicate 平台 的 web playground。
-
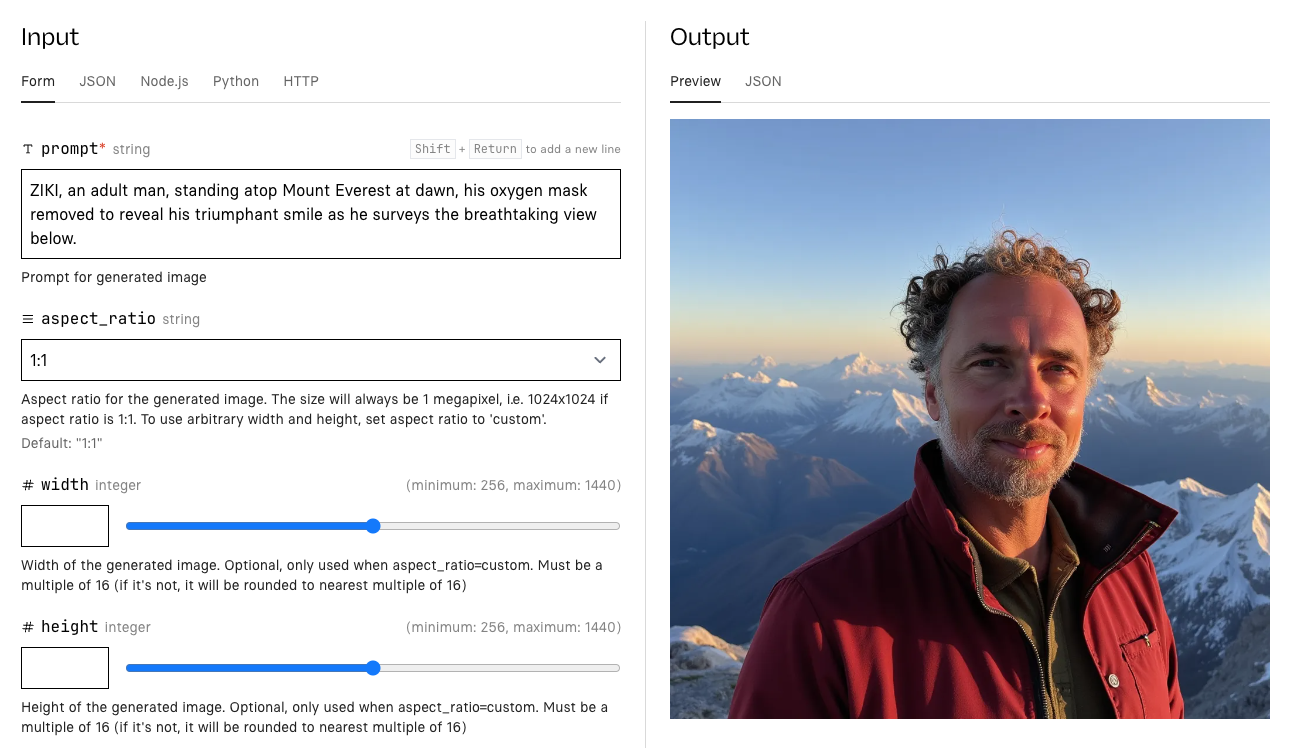
输入提示语,包括之前设置的触发词,例如:
"photo of ZIKI looking super-cool, riding a segway scooter"
FLUX 模型适合详细提示语,尽可能多描述。
本文由 mdnice 多平台发布


















 5058
5058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











