






一、简介
Kimi-Audio 是一种通用音频基础模型,能够在单一统一框架内处理多种音频处理任务。其核心特点包括:
1. 通用能力
支持以下多样化任务:
- 自动语音识别(ASR):将语音转换为文本。
- 音频问答(AQA):对音频内容进行理解和回答问题。
- 自动音频字幕生成(AAC):为音频生成描述性字幕。
- 语音情感识别(SER):识别语音中的情绪。
- 声音事件/场景分类(SEC/ASC):分类环境声或特定声音事件。
- 端到端语音对话:支持实时语音交互和多轮对话。
2. 最先进性能
在多项音频基准测试中取得 SOTA(最先进水平)成果(详见 评估部分 和 《技术报告》)。
3. 大规模预训练
基于 超过 1300 万小时 的多样化音频数据(语音、音乐、环境声)和文本数据进行预训练,实现强大的音频推理能力和语言理解能力。
4. 创新架构
- 混合音频输入:结合连续声学向量和离散语义 token。
- LLM 核心:采用并行处理文本和音频 token 生成的双头结构。
5. 高效推理
- 低延迟音频生成:基于流匹配(Flow Matching)的分块式流式反分词器,显著降低生成延迟。
6. 开源开放
- 代码与模型权重:开源预训练模型和指令微调版本。
- 综合评估工具包:提供完整评估工具,推动社区研究与开发。
二、架构设计
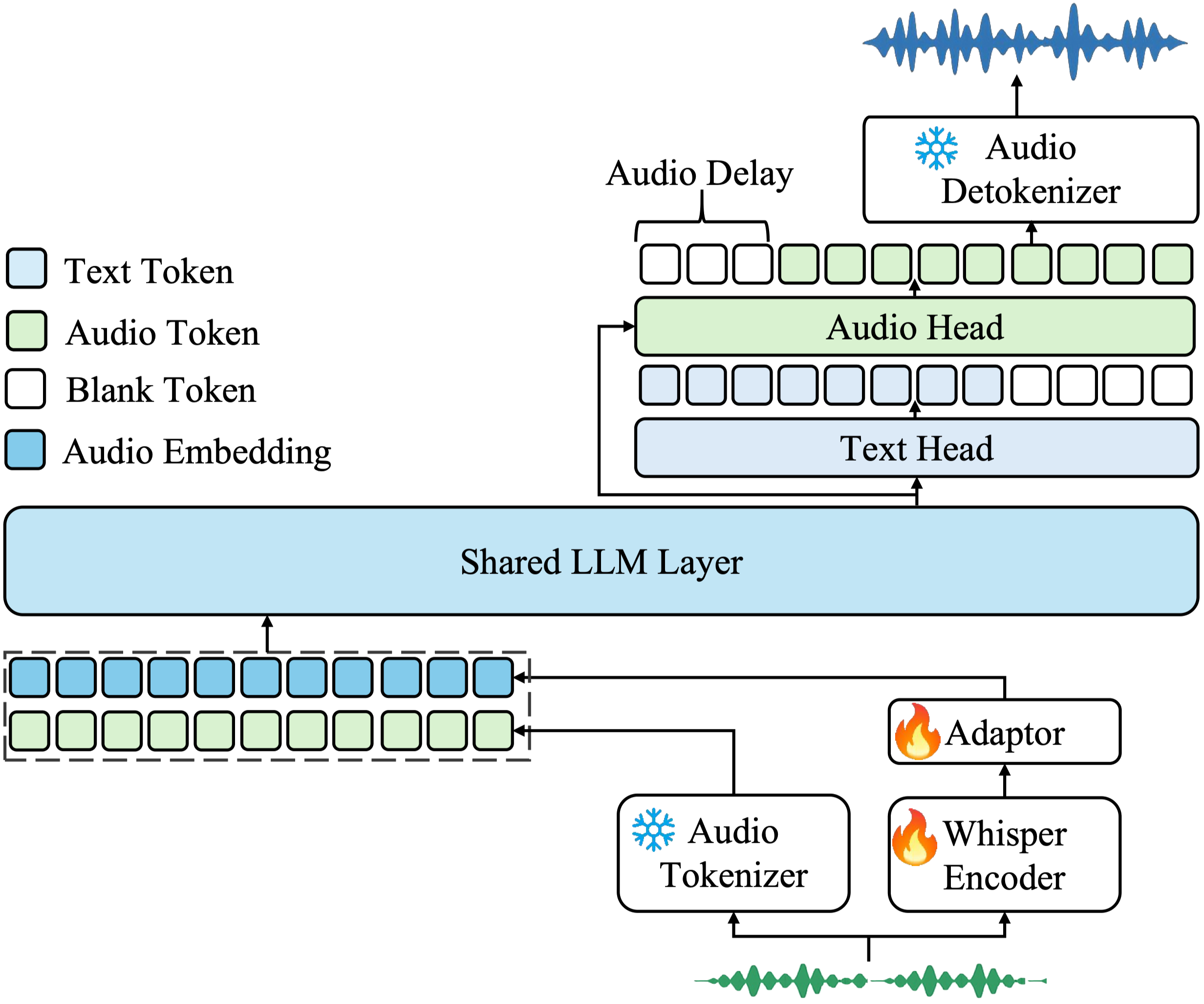
Kimi-Audio 由三个核心组件构成:
1. 音频分词器(Audio Tokenizer)
将输入音频转换为以下两种形式:
- 离散语义 token(帧率为 12.5Hz),通过矢量量化技术生成。
- 连续声学特征,基于 Whisper 编码器提取(下采样至 12.5Hz)。
2. 音频大模型(Audio LLM)
- 采用基于 Transformer 的模型架构,以预训练文本大语言模型(如 Qwen 2.5 7B)作为初始化基础。
- 共享层处理多模态输入(音频与文本),随后通过并行头生成:
- 自回归文本 token(用于文本输出)。
- 离散音频语义 token(用于语音生成)。
3. 音频反分词器(Audio Detokenizer)
- 利用流匹配模型和声码器(BigVGAN),将预测的离散语义音频 token 转换为高保真波形。
- 支持分块式流式处理,结合前瞻机制实现低延迟音频生成。
开始使用
步骤 1:获取代码
git clone https://github.com/MoonshotAI/Kimi-Audio.git
cd Kimi-Audio
git submodule update --init --recursive
pip install -r requirements.txt说明:
- 克隆仓库:通过
git clone命令将 Kimi-Audio 项目从 GitHub 下载到本地。 - 进入项目目录:使用
cd Kimi-Audio进入项目文件夹。 - 初始化子模块:
git submodule update --init --recursive确保项目依赖的子模块(如 Whisper 编码器)被正确下载和配置。 - 安装依赖:
pip install -r requirements.txt安装项目运行所需的 Python 库和工具。
三、快速入门
示例说明
此示例演示了 Kimi-Audio 的基础用法:
- 音频转文本(ASR):从音频生成文字。
- 语音对话生成:在对话回合中同时生成文本和语音。
代码实现
import soundfile as sf
from kimia_infer.api.kimia import KimiAudio
# --- 1. 加载模型 ---
model_path = "moonshotai/Kimi-Audio-7B-Instruct"
model = KimiAudio(model_path=model_path, load_detokenizer=True)
# --- 2. 定义采样参数 ---
sampling_params = {
"audio_temperature": 0.8, # 音频生成的随机性
"audio_top_k": 10, # 音频 token 采样范围
"text_temperature": 0.0, # 文本生成的随机性
"text_top_k": 5, # 文本 token 采样范围
"audio_repetition_penalty": 1.0, # 音频重复惩罚系数
"audio_repetition_window_size": 64, # 音频重复惩罚窗口大小
"text_repetition_penalty": 1.0, # 文本重复惩罚系数
"text_repetition_window_size": 16, # 文本重复惩罚窗口大小
}
# --- 3. 示例 1:音频转文本(ASR)---
messages_asr = [
# 可以提供上下文或指令
{"role": "user", "message_type": "text", "content": "请转录以下音频内容:"},
# 提供音频文件路径
{"role": "user", "message_type": "audio", "content": "test_audios/asr_example.wav"}
]
# 仅生成文本输出
_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")
print(">>> ASR 输出文本: ", text_output)
# 预期输出: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。"
# --- 4. 示例 2:音频-文本对话生成 ---
messages_conversation = [
# 以音频查询启动对话
{"role": "user", "message_type": "audio", "content": "test_audios/qa_example.wav"}
]
# 同时生成音频和文本输出
wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")
# 保存生成的音频文件
output_audio_path = "output_audio.wav"
sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # 假设输出采样率为 24kHz
print(f">>> 对话输出音频已保存至: {output_audio_path}")
print(">>> 对话输出文本: ", text_output)
# 预期输出: "A."
print("Kimi-Audio 推理示例完成。")四、评估
Kimi-Audio 在多个音频基准测试中实现了 最先进(SOTA)性能。
以下是整体表现:
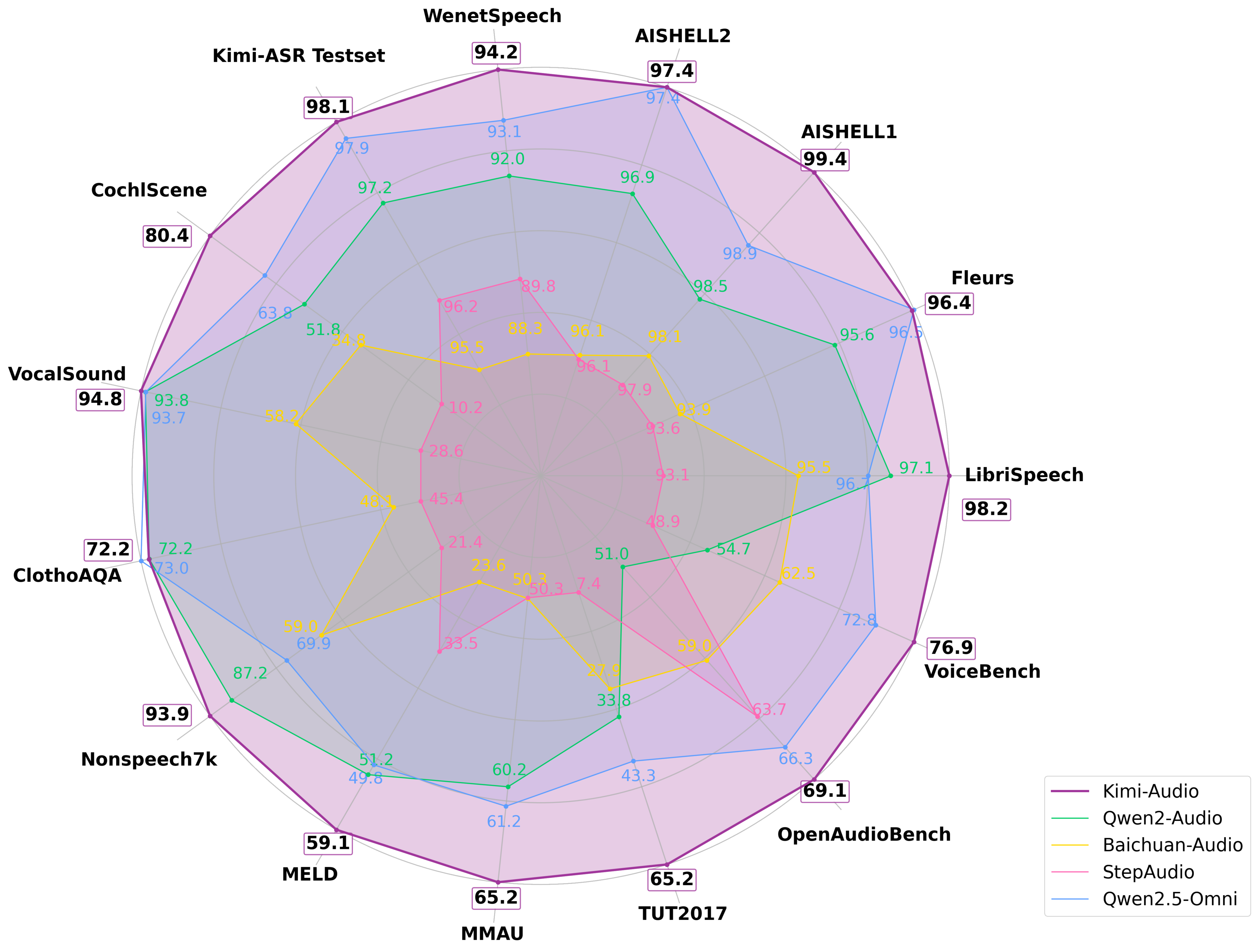
基准测试表现
以下是不同基准测试中的表现:
您可以轻松通过我们的 Kimi-Audio-Evalkit(详见评估工具包)复现我们的结果和基线模型:
自动语音识别(ASR)
| Datasets | Model | Performance (WER↓) |
|---|---|---|
| LibriSpeech test-clean | test-other | Qwen2-Audio-base | 1.74 | 4.04 |
| Baichuan-base | 3.02 | 6.04 | |
| Step-Audio-chat | 3.19 | 10.67 | |
| Qwen2.5-Omni | 2.37 | 4.21 | |
| Kimi-Audio | 1.28 | 2.42 | |
| Fleurs zh | en | Qwen2-Audio-base | 3.63 | 5.20 |
| Baichuan-base | 4.15 | 8.07 | |
| Step-Audio-chat | 4.26 | 8.56 | |
| Qwen2.5-Omni | 2.92 | 4.17 | |
| Kimi-Audio | 2.69 | 4.44 | |
| AISHELL-1 | Qwen2-Audio-base | 1.52 |
| Baichuan-base | 1.93 | |
| Step-Audio-chat | 2.14 | |
| Qwen2.5-Omni | 1.13 | |
| Kimi-Audio | 0.60 | |
| AISHELL-2 ios | Qwen2-Audio-base | 3.08 |
| Baichuan-base | 3.87 | |
| Step-Audio-chat | 3.89 | |
| Qwen2.5-Omni | 2.56 | |
| Kimi-Audio | 2.56 | |
| WenetSpeech test-meeting | test-net | Qwen2-Audio-base | 8.40 | 7.64 |
| Baichuan-base | 13.28 | 10.13 | |
| Step-Audio-chat | 10.83 | 9.47 | |
| Qwen2.5-Omni | 7.71 | 6.04 | |
| Kimi-Audio | 6.28 | 5.37 | |
| Kimi-ASR Internal Testset subset1 | subset2 | Qwen2-Audio-base | 2.31 | 3.24 |
| Baichuan-base | 3.41 | 5.60 | |
| Step-Audio-chat | 2.82 | 4.74 | |
| Qwen2.5-Omni | 1.53 | 2.68 | |
| Kimi-Audio | 1.42 | 2.44 |
音频理解
| Datasets | Model | Performance↑ |
|---|---|---|
| MMAU music | sound | speech | Qwen2-Audio-base | 58.98 | 69.07 | 52.55 |
| Baichuan-chat | 49.10 | 59.46 | 42.47 | |
| GLM-4-Voice | 38.92 | 43.54 | 32.43 | |
| Step-Audio-chat | 49.40 | 53.75 | 47.75 | |
| Qwen2.5-Omni | 62.16 | 67.57 | 53.92 | |
| Kimi-Audio | 61.68 | 73.27 | 60.66 | |
| ClothoAQA test | dev | Qwen2-Audio-base | 71.73 | 72.63 |
| Baichuan-chat | 48.02 | 48.16 | |
| Step-Audio-chat | 45.84 | 44.98 | |
| Qwen2.5-Omni | 72.86 | 73.12 | |
| Kimi-Audio | 71.24 | 73.18 | |
| VocalSound | Qwen2-Audio-base | 93.82 |
| Baichuan-base | 58.17 | |
| Step-Audio-chat | 28.58 | |
| Qwen2.5-Omni | 93.73 | |
| Kimi-Audio | 94.85 | |
| Nonspeech7k | Qwen2-Audio-base | 87.17 |
| Baichuan-chat | 59.03 | |
| Step-Audio-chat | 21.38 | |
| Qwen2.5-Omni | 69.89 | |
| Kimi-Audio | 93.93 | |
| MELD | Qwen2-Audio-base | 51.23 |
| Baichuan-chat | 23.59 | |
| Step-Audio-chat | 33.54 | |
| Qwen2.5-Omni | 49.83 | |
| Kimi-Audio | 59.13 | |
| TUT2017 | Qwen2-Audio-base | 33.83 |
| Baichuan-base | 27.9 | |
| Step-Audio-chat | 7.41 | |
| Qwen2.5-Omni | 43.27 | |
| Kimi-Audio | 65.25 | |
| CochlScene test | dev | Qwen2-Audio-base | 52.69 | 50.96 |
| Baichuan-base | 34.93 | 34.56 | |
| Step-Audio-chat | 10.06 | 10.42 | |
| Qwen2.5-Omni | 63.82 | 63.82 | |
| Kimi-Audio | 79.84 | 80.99 |
音频转文本对话
| Datasets | Model | Performance↑ |
|---|---|---|
| OpenAudioBench AlpacaEval | Llama Questions | Reasoning QA | TriviaQA | Web Questions | Qwen2-Audio-chat | 57.19 | 69.67 | 42.77 | 40.30 | 45.20 |
| Baichuan-chat | 59.65 | 74.33 | 46.73 | 55.40 | 58.70 | |
| GLM-4-Voice | 57.89 | 76.00 | 47.43 | 51.80 | 55.40 | |
| StepAudio-chat | 56.53 | 72.33 | 60.00 | 56.80 | 73.00 | |
| Qwen2.5-Omni | 72.76 | 75.33 | 63.76 | 57.06 | 62.80 | |
| Kimi-Audio | 75.73 | 79.33 | 58.02 | 62.10 | 70.20 | |
| VoiceBench AlpacaEval | CommonEval | SD-QA | MMSU | Qwen2-Audio-chat | 3.69 | 3.40 | 35.35 | 35.43 |
| Baichuan-chat | 4.00 | 3.39 | 49.64 | 48.80 | |
| GLM-4-Voice | 4.06 | 3.48 | 43.31 | 40.11 | |
| StepAudio-chat | 3.99 | 2.99 | 46.84 | 28.72 | |
| Qwen2.5-Omni | 4.33 | 3.84 | 57.41 | 56.38 | |
| Kimi-Audio | 4.46 | 3.97 | 63.12 | 62.17 | |
| VoiceBench OpenBookQA | IFEval | AdvBench | Avg | Qwen2-Audio-chat | 49.01 | 22.57 | 98.85 | 54.72 |
| Baichuan-chat | 63.30 | 41.32 | 86.73 | 62.51 | |
| GLM-4-Voice | 52.97 | 24.91 | 88.08 | 57.17 | |
| StepAudio-chat | 31.87 | 29.19 | 65.77 | 48.86 | |
| Qwen2.5-Omni | 79.12 | 53.88 | 99.62 | 72.83 | |
| Kimi-Audio | 83.52 | 61.10 | 100.00 | 76.93 |
语音对话性能
Kimi-Audio 与基线模型在语音对话任务中的性能表现。
| Model | Ability | |||||
|---|---|---|---|---|---|---|
| Speed Control | Accent Control | Emotion Control | Empathy | Style Control | Avg | |
| GPT-4o | 4.21 | 3.65 | 4.05 | 3.87 | 4.54 | 4.06 |
| Step-Audio-chat | 3.25 | 2.87 | 3.33 | 3.05 | 4.14 | 3.33 |
| GLM-4-Voice | 3.83 | 3.51 | 3.77 | 3.07 | 4.04 | 3.65 |
| GPT-4o-mini | 3.15 | 2.71 | 4.24 | 3.16 | 4.01 | 3.45 |
| Kimi-Audio | 4.30 | 3.45 | 4.27 | 3.39 | 4.09 | 3.90 |
五、学习资源链接
模型地址:https://github.com/MoonshotAI/Kimi-Audio
论文地址:https://github.com/MoonshotAI/Kimi-Audio/blob/master/assets/kimia_report.pdf

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









