









1.摘要

Kimi-Audio,这是一个开源的音频基础模型,在音频理解、生成和对话方面表现出色。其主要贡献点如下:
- 作者利用了12.5赫兹的音频分词器(Audio tokenizer),并设计了一种新型的基于LLM的架构,该架构以连续特征作为输入,以离散标记作为输出,并开发了一种基于流匹配的分块流式解码器。
- 作者策划了一个预训练数据集,包含超过1300万小时的音频数据,涵盖语音、声音和音乐等多种模态,并构建了一个用于构建高质量和多样化后训练数据的管道。
Kimi-Audio基于预训练的LLM进行初始化,并在音频和文本数据上进行了精心设计任务的持续预训练,随后进行了微调以支持多种音频相关任务。广泛的评估表明,Kimi-Audio在包括语音识别、音频理解、音频问答和语音对话在内的多种音频基准测试中达到了最先进的性能。
github地址:https://github.com/MoonshotAI/Kimi-Audio
权重地址:https://huggingface.co/moonshotai/Kimi-Audio-7B-Instruct/tree/main
论文地址:https://arxiv.org/pdf/2504.18425
评估基准:https://github.com/MoonshotAI/Kimi-Audio-Evalkit
-
-
2.论文详解
简介
传统的音频建模方法受到人工智能发展的限制,通常将每个音频处理任务(例如语音识别、情感识别、声音事件检测和语音对话)分开处理。然而,音频本质上是连续的序列,并且语音与文本之间存在严格的对应关系,这使得我们可以利用大型语言模型(LLMs)在音频建模方面的快速进展。正如自然语言处理所经历的那样,音频处理也迅速从为每个任务单独建模转变为由一个通用模型处理多种任务。
Kimi-Audio,这是一个开源的音频基础模型,能够处理多种音频处理任务。作者详细介绍了在构建最先进的音频基础模型方面的努力,主要涉及三个方面:架构、数据和训练。
- 架构。模型由三个组件构成:音频分词器和解码器作为音频的输入/输出,以及音频LLM作为核心处理部分。作者使用离散的语义音频标记作为音频LLM输入和输出的基本表示形式。同时,在输入中将语义音频标记与连续的声学向量拼接,以增强感知能力,并在输出中与离散的文本标记拼接,以增强生成能力。通过这种方式,可以在同时实现良好的音频感知和生成能力,促进通用音频建模。为了弥合文本和音频序列之间的差距,作者将音频中的每秒标记数量减少,并将语义和声学音频标记的压缩率均设置为12.5Hz。
- 数据。作者爬取并处理了一个大规模的音频预训练数据集。作者开发了一个数据处理流程,包括语音增强、说话人分离、转录、过滤等,以确保数据的高质量。为了支持多样化的音频处理任务,作者策划了大量针对特定任务的数据用于监督式微调(SFT)。
- 训练。为了在保持高知识容量和智能水平的同时实现良好的音频理解/生成能力,作者使用预训练的语言模型(LLM)初始化音频LLM,并精心设计了一系列预训练任务,以充分学习音频数据并弥合文本与音频之间的差距。具体来说,预训练任务可以分为三类:1)仅文本和仅音频的预训练,目的是分别从文本和音频领域学习知识;2)音频到文本的映射,鼓励音频和文本之间的转换;3)音频-文本交错,进一步弥合文本和音频之间的差距。在监督式微调阶段,作者开发了一种训练方案,以提高微调效率和任务泛化能力。
此外,作者还介绍了在Kimi APP中部署和提供音频基础模型推理服务的实践,作者在公平比较不同音频模型时遇到了一些棘手的问题,例如非标准化的评估指标、评估协议以及推理超参数。因此,作者开发了一个评估工具包,能够全面地对音频LLM进行基准测试。作者开源了这个工具包,以促进社区内公平的比较。评估结果表明,Kimi-Audio在一系列音频任务中均达到了最先进的性能,包括语音识别、音频理解、音频到文本的对话以及语音对话。
-
架构
Kimi-Audio 是一个音频基础模型,旨在通过统一的架构执行全面的音频理解、生成和对话任务模型由三个主要组件组成:
- 音频分词器(audio tokenizer),它将输入音频转换为通过矢量量化以 12.5Hz 帧率生成的离散语义标记。音频分词器还提取连续的声学向量以增强感知能力。
- 音频 LLM(audio LLM),它生成语义标记和文本标记,以提高生成能力,其特点是共享的 Transformer 层在分支到用于文本和音频生成的专用并行头部之前处理多模态输入
- 音频解码器(audio detokenizer),它使用流匹配方法将音频 LLM 预测的离散语义标记转换回连贯的音频波形。这种集成架构使 Kimi-Audio 能够在单一统一的模型框架内无缝处理从语音识别和理解到语音对话的各种音频 - 语言任务。
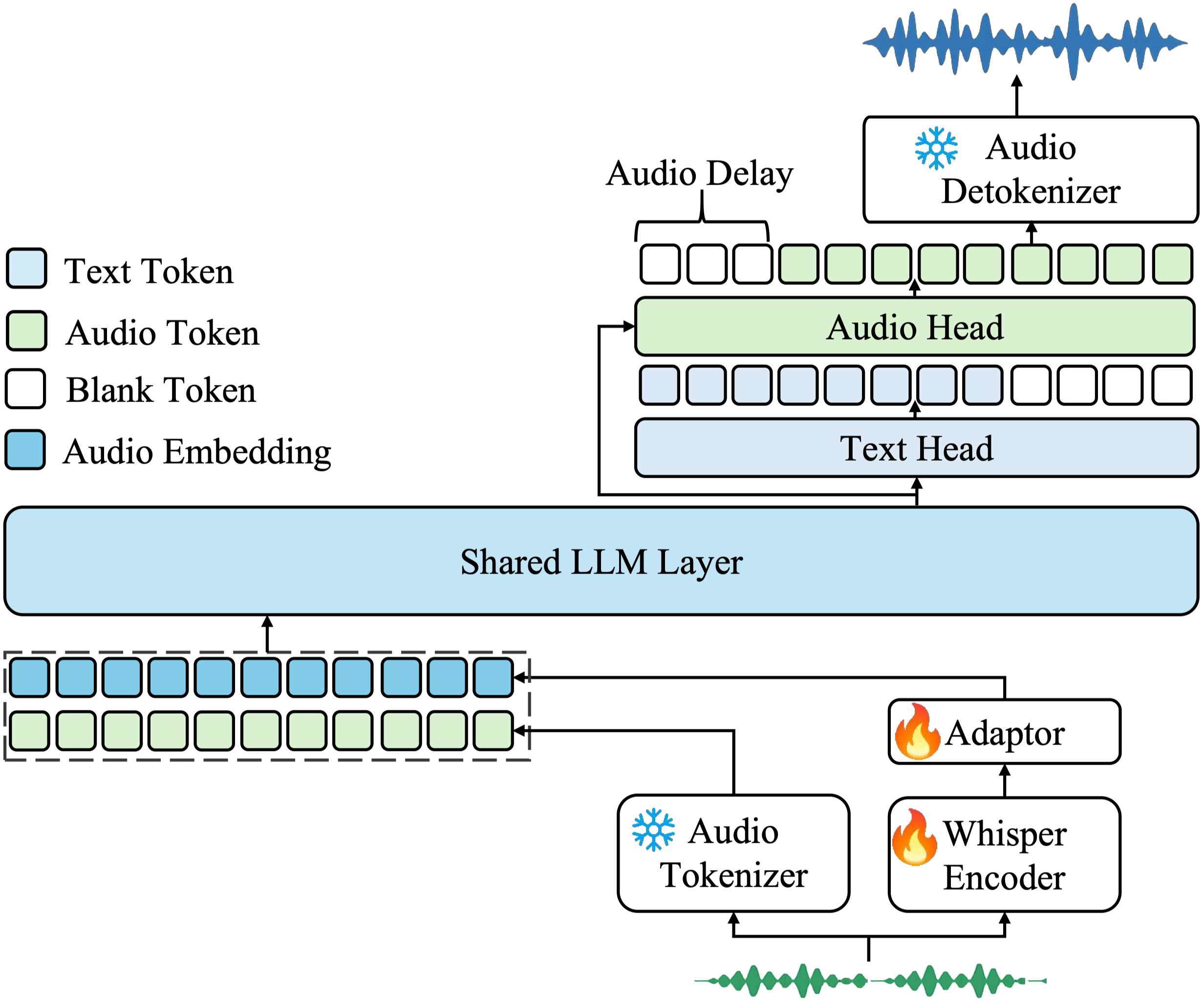
音频分词器
Kimi-Audio的音频基础模型采用了一种混合音频分词策略,将离散的语义标记与连续的声学信息向量相结合,以有效地表示用于下游任务的语音信号。这种分词方法使模型能够在利用离散标记的高效性和语义聚焦的同时,受益于连续表示所捕捉到的丰富声学细节。
作者采用了GLM-4-Voice提出的离散语义标记。该组件利用了来自自动语音识别(ASR)模型的监督式语音分词器。通过在Whisper编码器架构中引入一个矢量量化层,作者可以使用单个码本将连续的语音表示转换为低帧率(即12.5赫兹)的离散标记序列。
Whisper编码器是一种基于深度学习的音频特征提取模型,最初由OpenAI开发,主要用于语音识别任务。它通过将输入的音频信号转换为一系列连续的特征向量(通常称为“声学特征”或“音频嵌入”),为后续的语音处理任务提供丰富的语义和声学信息。在Kimi-Audio中,Whisper编码器被用作音频分词器的一部分,用于提取音频的连续特征表示。
12.5Hz的帧率意味着每秒生成12.5个特征向量。低帧率的特征表示可以减少计算复杂度,同时保留音频的关键信息。在Kimi-Audio中,作者选择12.5Hz的帧率是为了在计算效率和信息保留之间取得平衡。
为了补充离散语义标记,作者引入了来自预训练的Whisper模型的连续特征表示,以增强模型的感知能力。由于Whisper特征的帧率为50Hz,作者还在Whisper特征提取器的基础上引入了一个适配器,将特征从50Hz下采样到12.5Hz。下采样的特征与离散语义标记的嵌入相结合,作为音频LLM的输入。
通过结合离散语义标记和连续的Whisper特征,Kimi-audio既能从高效的、语义化的表示中受益,又能进行详细的声学建模,为多种音频处理任务提供了全面的基础。
音频LLM
Kimi-audio的内核是一个音频LLM,旨在处理上节中描述的分词策略生成的音频表示,并产生多模态输出,其中包括音频的离散语义标记以及相应的文本标记,以增强生成能力。
为了使模型能够生成音频语义标记以及相应的文本响应,作者通过将标准LLM架构划分为具有共享和专用功能的组件来对其进行调整。
- 原始Transformer架构的底部几层(即最初的几层)被用作共享层,这些共享层处理输入序列,并学习跨模态表示,整合输入或上下文中包含的文本和音频模态的信息。
- 基于这些共享层,架构分支为两个包含Transformer层的并行头部。第一个头部是文本头部(text head),专门负责自回归地预测文本标记,形成模型的文本输出。第二个头部是音频头部(audio head),用于预测离散的音频语义标记。这些预测的音频标记随后被传递给音频解码器模块,以合成最终的输出音频波形。
为了充分利用预训练文本LLM的强大语言能力,共享Transformer层和文本头部的参数直接从预训练文本LLM的权重初始化。音频头部的层则随机初始化。这种初始化策略确保了模型在学习有效处理和生成音频信息的同时,保留了强大的文本理解和生成能力。
音频解码器
音频解码器的目标是根据离散的语义音频标记生成高质量且富有表现力的语音。作者采用了与MoonCast中相同的解码器架构,它包含两部分:
- 一个流匹配模块,将12.5Hz的语义标记转换为50Hz的梅尔频谱图;
- 一个声码器,从梅尔频谱图生成波形。
分块自回归流式框架(Chunk-wise Autoregressive Streaming Framework)。为了减少语音生成的延迟,作者设计了一个分块流式解码器。在实时语音对话任务中,用户期望系统能够快速响应。如果直接处理整个音频序列,生成延迟可能会很高,导致用户体验不佳。通过将音频序列分成小块(例如每秒一个块),解码器可以逐块生成音频,从而实现低延迟的实时交互。用户在说话结束后可以立即听到系统的回应,而不是等待整个音频生成完成。
下面是分块自回归流式框架的数学形式,其流程和上段一样,可跳过。作者将音频分割成分块(例如,每个块1秒):,其中N是块的数量。
- 首先,为了匹配语义标记(12.5Hz)和梅尔频谱图(50Hz)之间的序列长度,作者通过4倍的速率对语义标记进行上采样。
- 其次,作者在训练和推理过程中应用分块的因果掩码,即对于块
,所有先前的块
(j < i)都作为提示。作者用
表示块
表示相应的离散语义音频标记。流匹配模型的前向步骤将mi与高斯噪声混合,后向步骤将去除噪声以获得干净的
- 在推理过程中,当LLM生成一个块时,作者使用流匹配模型对其进行detokenize以获得梅尔频谱图。最后,作者应用BigVGAN声码器为每个块生成波形。
直观上,作者可以将语义标记分割成块并分别解码它们,然而,在初步实验中,这种方法在块边界处遇到了间断性的问题。因此,作者提出了一个带有前瞻机制的分块自回归流式框架。
前瞻机制:通过初步研究,作者发现在块边界处生成的音频仍然存在间歇性问题。尽管在扩散去噪过程中已经看到了长距离的历史上下文,但由于块状因果注意力的本质,边界位置的未来上下文无法被看到,这导致了质量的下降。因此,作者提出了一种前瞻机制。
具体来说,对于块,作者从块
中取出未来的n(例如4)个语义token,并将它们连接到
的末尾,形成
。然后我们对
进行去标记化以生成梅尔频谱图,但只保留与ci相对应的梅尔频谱图。这种机制无需训练,并且只会将第一个块的生成延迟n个标记。
总结一下:如果一个token一个token的生成,可能延迟过高,因此作者选择分块,这样就能一批批生成,加快速度。但每个块的块间会有间隙,影响质量,因此每次从下一个块多取出几个token,拼在一起进行生成,这样就相当于没有间隙了,当然生成的结果只保留当前块token的,忽略多取的token生成的部分。
-
数据
预训练数据
预训练语料库包括单模态(仅限文本、仅限音频)和多模态(文本-音频)数据。仅限音频的预训练数据涵盖了广泛的现实世界场景,包括有声书、播客和访谈,由大约1300万小时的原始音频组成,这些音频包含了丰富的声学事件、音乐、环境声音、人类发声和多语言信息。
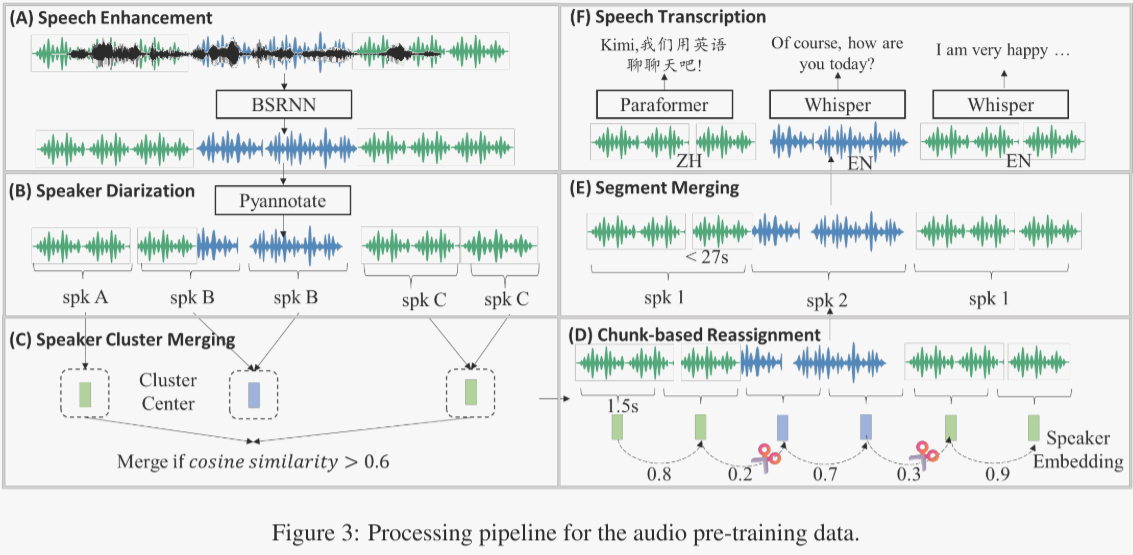
大多数音频语料库仅包含没有相应转录、语言类型、说话人注释和分割边界的原始音频。此外,原始音频通常包含不需要的伪影,如背景噪音、混响和说话人重叠。作者开发了一个高效的自动音频数据处理流程,以生成高质量的注释,从而形成多模态(音频-文本)数据。与主要侧重于生成没有上下文信息的高质量短音频片段的先前数据处理流程相比,作者的流程旨在提供具有一致的长期上下文的长格式音频注释。该流程包括以下关键组件:
- 语音增强。为了抑制不需要的背景噪音和混响,作者开发了一个基于频带分割循环神经网络(Band-Split RNN,简称BSRNN)架构的语音增强模型,如图3(A)所示。该模型被应用于执行48kHz的语音增强。根据经验,作者发现语音增强会去除环境声音和音乐,这可能对音频理解产生不利影响。因此,在预训练阶段,作者以1:1的比例随机选择原始音频或增强后的音频。
- 通过说话人分离进行分割。作者采用说话人分离驱动的方法来分割长音频。作者使用PyAnnote工具包进行说话人分离(见图3(B)),该工具包对音频进行分割并分配说话人标签。然而,原始输出并不理想,因此作者开发了一个后处理流程来解决先前分割结果中的问题:
- 说话人聚类合并。作者观察到PyAnnote有时会给同一个实际说话人分配多个说话人标签,这导致了说话人碎片化。作者为每个初始聚类计算代表性的说话人embedding,并将嵌入余弦相似度大于0.6的聚类对进行合并,如图3(C)所示。
- 基于块的重新分配。初始的说话人分离有时会产生包含多个说话人的段落。为了净化这些段落,1)作者首先将所有段落分成1.5秒的块,然后2)对于每对相邻的块,如果它们的余弦相似度低于0.5,就将它们视为属于不同的说话人,并将每个块重新分配给相似度最高的说话人聚类,如图3(D)所示。
- 段落合并。初始的说话人分离可能导致段落长度变化很大,有时甚至不切实际(短于1秒或长于100秒)。因此,作者迭代地合并被标记为同一说话人(重新分配步骤之后)的相邻段落。如果累积的段落长度超过27秒或两个段落之间的静音间隔大于2秒,合并过程将终止,如图3(E)所示。
-
语音转录。为了获取每个语音段落的语言类型和文本转录,作者首先应用Whisper-large-v3模型来检测所说的语言类型。在这项工作中,作者只保留了英语和普通话段落进行进一步的转录。对于英语段落,作者直接使用Whisper-large-v3生成转录和标点注释。对于普通话段落,作者利用FunASR工具包中的Paraformer-Zh模型生成转录以及字符级别的时间戳。由于Paraformer-Zh不能输出标点注释,作者采用以下策略添加标点注释:如果两个连续字符之间的时间间隔大于0.5秒但小于1.0秒,我们插入一个“逗号”;如果间隔超过1.0秒,我们插入一个“句号”。
-
实现。数据处理流程部署在由30个云实例组成的集群上。每个实例都配备了128个虚拟CPU(vCores)、1TB的RAM和8个NVIDIA L20 GPU,由支持向量化加速指令的Intel Xeon Platinum 8575C处理器提供动力,包括高级矩阵扩展(AMX)。总的来说,集群提供了3840个vCores、30TB的内存和240个NVIDIA L20 GPU。经过广泛的优化,该流程每天可以处理大约20万小时的原始音频数据。
SFT数据
在预训练阶段之后,作者进行监督微调(SFT)以增强Kimi-Audio在指令跟随和音频处理方面的性能。SFT数据主要可分为三个部分:音频理解、语音会话和音频-文本聊天。
音频理解
作者主要利用开源数据集来进行音频理解。收集的数据集包括6个任务:自动语音识别(ASR)、音频问答(AQA)、自动音频字幕(AAC)、语音情感识别(SER)、声音事件分类(SEC)和音频场景分类(ASC)。除了开源数据集,作者还使用了55,000小时的内部ASR数据和5,200小时的内部音频数据,这些数据涵盖了AAC/AQA任务。
语音会话
为了激活Kimi-Audio模型在不同对话场景中生成具有多样化风格和高表现力的语音的能力,作者构建了大量的语音对话数据,这些数据由一系列用户查询和助手响应组成的多轮对话构成。对于用户查询,作者指导LLM编写用户查询的文本,然后使用作者的Kimi-TTS系统将它们转换为语音,其中提示语音是从包含超过125K种音色的大型音色集中随机选择的。对于助手响应,作者首先选择一位声音演员作为Kimi-Audio发言人,并使用这种单一音色合成具有适当风格和情感的助手响应。
接下来,作者将介绍Kimi-Audio发言人的数据录制过程,以及用于合成具有多样化风格和表现力的助手响应的Kimi-TTS和Kimi-VC系统。
- Kimi-Audio发言人的数据录制。为了在生成的语音中实现多样化和高度表现力的风格和情感,作者选择了一位声音演员作为Kimi-Audio的发言人,并在专业录音室精心录制了这位发言人的数据集。作者预定义了超过20种风格和情感进行录制,每种情感进一步分为5个级别,以表示不同的情感强度。对于每种风格和情感级别,作者录制一个音频作为参考,以保持不同文本句子之间的情感和风格的一致性。整个录制过程由专业的录音导演指导。
- Kimi-TTS。作者开发了一个零样本文本到语音合成(TTS)系统,称为Kimi-TTS,只需3秒的提示音,就能生成保留提示语音的音色、情感和风格的语音。借助Kimi-TTS,作者可以合成1)具有大量音色集的多种说话人/音色的查询文本的语音;2)由Kimi选择的声音演员录制的、具有Kimi-Audio发言人风格和情感的响应文本的语音。与MoonCast的架构类似,Kimi-TTS采用LLM根据提示语音和输入文本生成语音标记。然后使用基于流匹配的语音解码器生成高质量的语音波形。作者在自动数据管道生成的大约100万小时的数据上训练Kimi-TTS,并应用强化学习进一步提高生成语音的鲁棒性和质量。
- Kimi-VC。由于声音演员很难录制任何风格、情感和口音的语音,作者开发了一个语音转换(VC)系统,称为Kimi-VC,将不同说话人/音色的多样化和野外语音转换为Kimi-Audio发言人的音色,同时保留风格、情感和口音。Kimi-VC建立在Seed-VC框架上,通过音色转换模型在训练期间引入源音色扰动,这减少了信息泄露并确保了训练和推理阶段之间的对齐。为了确保语音转换的高质量,作者使用Kimi选择的声音演员录制的语音数据对Kimi-VC模型进行微调。
音频-文本聊天
为了帮助Kimi-Audio掌握基本的聊天能力,作者从文本领域收集了开源的监督式微调数据,如表2所列,然后将用户查询转换为具有多种音色的语音,从而生成音频到文本的聊天数据,其中用户查询是语音而助手响应是文本。
考虑到一些文本不容易转换为语音,作者对文本执行了几个预处理步骤:
- 过滤掉包含复杂数学、代码、表格、复杂的多语言内容或过长内容的文本,
- 进行口语化改写,
- 将包含复杂指令的单轮问答数据转换为包含简单明了指令的多轮数据。
-
训练
预训练
Kimi-Audio的预训练阶段旨在从真实世界的音频和文本领域学习知识,并在模型的潜在空间中对齐它们,从而促进诸如音频理解、音频到文本的聊天和语音对话等复杂任务。为此,作者设计了几个预训练任务,包括以下方面:
- 在单模态(即音频和文本)中的预训练,以分别从每个领域单独学习知识;
- 学习音频-文本映射
- 进一步桥接两种模态的三个音频-文本交错任务。
形式上,给定一段原始音频A,数据预处理流程将其分割成一系列片段,每个片段
(i属于[1, N])由一段音频ai和相应的转录
组成。此外,对于音频片段
,作者提取出连续的声学向量
和离散的语义标记
。该设计采用离散语义音频标记作为输入和输出的主要表示形式,同时在输入中添加连续声学音频标记,在输出中添加离散文本标记,作者将训练序列表示为
,其中
表示第i段的语义音频、声学音频和文本序列。
作者确保音频和文本序列具有相同的长度,通过在较短序列后添加空白标记来实现。实际的预训练片段可以是中的一个或两个,例如
,
,
, 或
。
- 对于
,作者添加连续向量
和语义标记
(语义标记将使用查找表转换为嵌入以获得最终的音频特征
)。因此,作者用
- 对于
,作者添加语义标记和文本标记的查找嵌入作为输入,并使用各自的头部生成每个标记。
使用这种符号,作者在表3中制定了以下预训练任务:
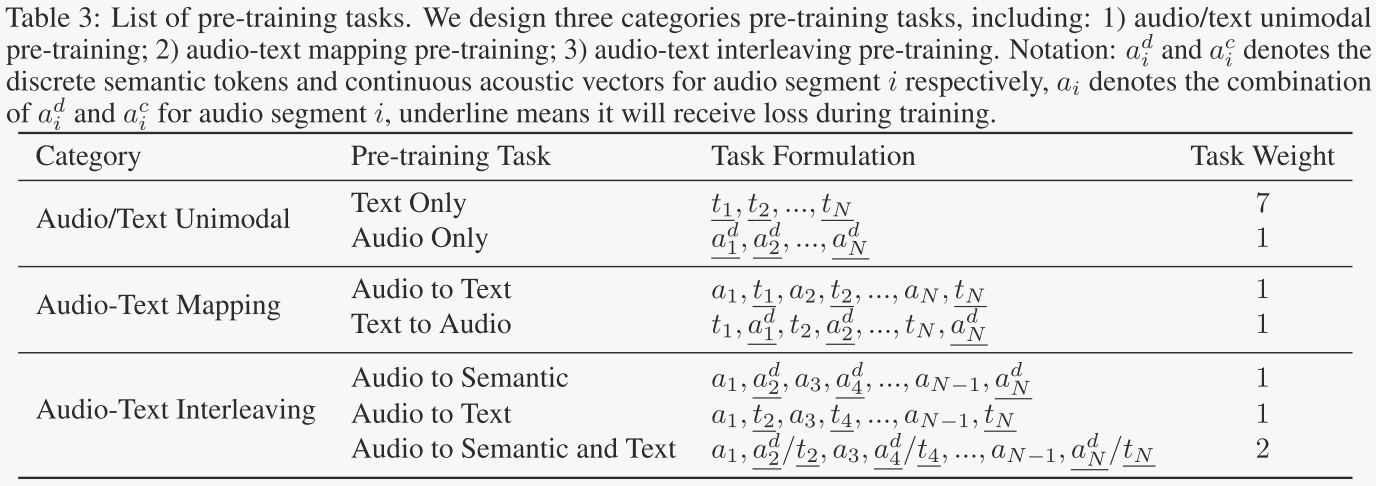
详细解释如下:
音频/文本单模态预训练
首先分别学习文本和音频的知识。对于文本预训练,作者直接利用MoonLight中的文本数据,这些数据高质量且全面,适合训练大型语言模型。包括两个任务:
- 仅对文本标记应用next-token预测。
- 对于音频预训练,对于每个片段
,对其离散语义标记序列
音频-文本映射预训练
直观地说,为了在统一的空间中对齐音频和文本,学习两种模态之间的映射是有帮助的。因此,作者设计了自动语音识别(ASR)和文本到语音合成(TTS)预训练任务。
- 对于ASR,作者将训练序列制定为
。
- 对于TTS,我们将训练序列制定为
。我们仅计算ASR的文本标记损失和TTS的音频语义标记损失。
音频-文本交错预训练
为了进一步弥合音频和文本模态之间的差距,作者设计了三个音频-文本交错的预训练任务。
-
音频到语义标记交错。作者制定训练序列为
。然后我们仅计算语义音频标记
的损失。
-
音频到文本交错。我们制定训练序列为{a1, t2, a3, t4, ..., aN-1, tN}。我们仅计算文本标记ti的损失。
-
音频到语义标记+文本交错。作者制定训练序列为
。对于
预训练配置
作者从预训练的Qwen2.5 7B模型初始化Kimi-Audio的音频LLM,并扩展其词汇表以包含语义音频标记和特殊标记。作者在上述预训练任务上执行预训练,相应的任务权重为1:7:1:1:1:1:2,如表3所示。作者使用585B音频标记和585B文本标记对Kimi-Audio进行预训练,共进行1个epoch。使用AdamW优化器,学习率计划从2e-5到2e-6,采用余弦衰减。使用1%的标记进行学习率预热。
音频分词器中的连续声学特征提取模块从Whisper large-v3初始化,可以捕捉输入音频信号中固有的细粒度声学特征。在模型预训练的初始阶段(大约20%的标记在预训练中),该基于Whisper的特征提取器的参数保持冻结。随后,特征提取器解冻,使其参数能够与模型的其余部分一起进行微调,从而更具体地适应训练数据的细节和目标任务的要求。
监督微调
在用大量真实世界的音频和文本数据预训练Kimi-Audio之后,作者执行监督微调,以使其具备指令跟随的能力。有以下设计选择:
- 考虑到下游任务的多样性,不设置特殊的任务切换操作,而是为每个任务使用自然语言作为指令;
- 对于指令,作者构建了音频和文本版本(即,音频是通过Kimi-TTS以零样本方式根据文本生成的)并在训练期间随机选择其中一个;
- 为了增强指令跟随能力的鲁棒性,作者通过LLM构建了200条用于ASR任务的指令和30条用于其他任务的指令,并为每个训练样本随机选择一条。
作者构建了大约300,000小时的数据用于监督式微调。
作者根据全面的消融实验结果,对每个数据源进行2-4个epoch的Kimi-Audio微调。使用AdamW优化器,学习率计划从1e-5到1e-6,采用余弦衰减。作者使用10%的标记进行学习率预热。
音频解码器的训练
作者分三个阶段训练音频解码器。
- 首先,作者使用预训练数据中的大约100万小时的音频,并预训练流匹配模型和声码器,以学习具有多样音色、韵律和质量的音频。、
- 其次,作者采用分块微调策略,在相同的预训练数据上进行动态分块大小为0.5秒至3秒的微调。
- 最后,作者使用来自Kimi-Audio发言人的高质量单一说话人录音数据进行微调。
-
推理和部署
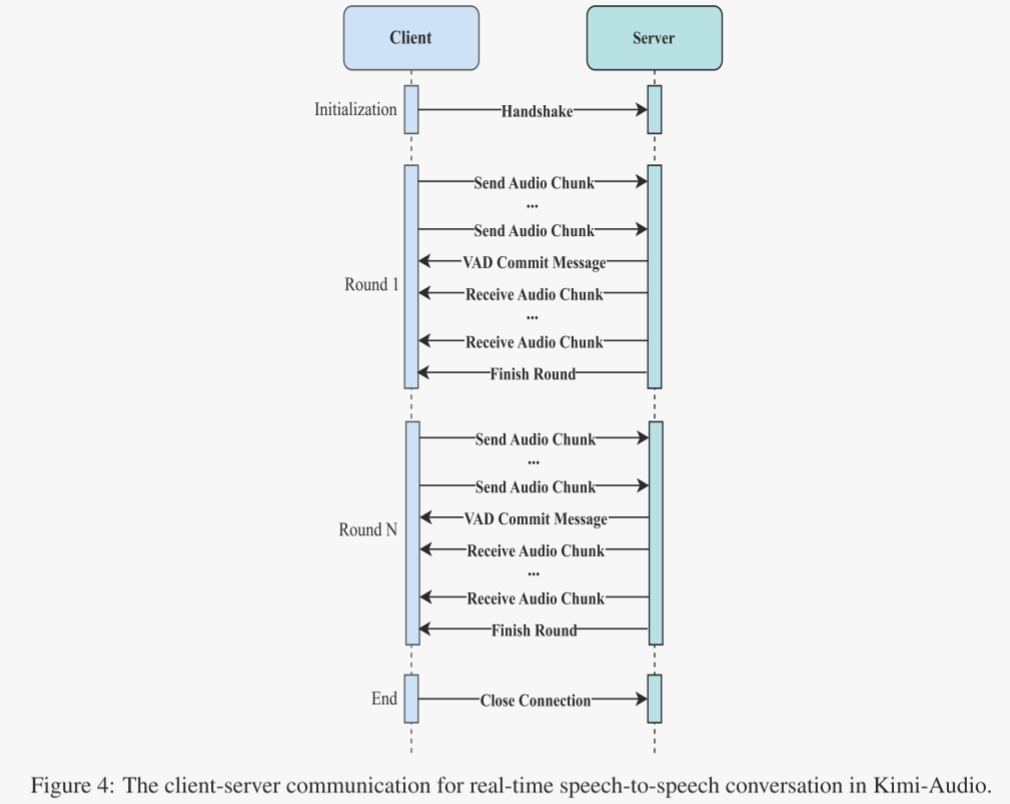
Kimi-Audio旨在处理各种与音频相关的任务,例如语音识别、音频理解、音频到文本的聊天以及语音到语音的对话。我们以实时语音到语音对话为例,来说明Kimi-Audio部署中的实践,因为与其他音频任务相比,这项任务在基础设施和工程努力方面更为复杂。首先介绍客户端(例如,Kimi APP或网页浏览器)与服务器(Kimi-Audio服务)之间实时语音对话的工作流程,然后描述产品部署的实践。
实时语音会话的工作流程
用户客户端(例如,Kimi APP或网页浏览器)与服务器(Kimi-Audio服务)之间的语音到语音对话的工作流程如图4所示。每轮对话的工作流程如下:
- 用户对客户端说话(例如,Kimi APP或网页浏览器),音频数据被收集并流式传输到服务器。
- 在服务器端,一个语音活动检测(VAD)模块确定用户是否已经说完。
- 一旦用户停止说话,服务器发送一个确认信号并启动Kimi-Audio模型的推理过程。
- 在推理过程中,客户端实时接收生成的音频块,并开始为用户播放这些音频。
- 客户端(手机或网页浏览器)将接收到的音频块播放给用户。
服务器端Kimi-Audio的每一轮推理过程遵循以下步骤。首先,输入音频使用音频分词器转换为离散语义标记和连续声学向量。接下来,通过将系统提示标记、音频标记和对话历史标记连接起来,组装成输入到音频LLM的数据。然后,将标记序列传递给音频LLM,生成输出标记。最后,使用解码器将输出标记转换回音频波形。
生产部署
如图5所示,在生产环境中,所有核心组件:音频分词器、音频LLM和音频解码器,都是计算密集型的,需要一个可扩展且高效的基础设施。为了解决这个问题,作者设计了如下的生产部署架构。
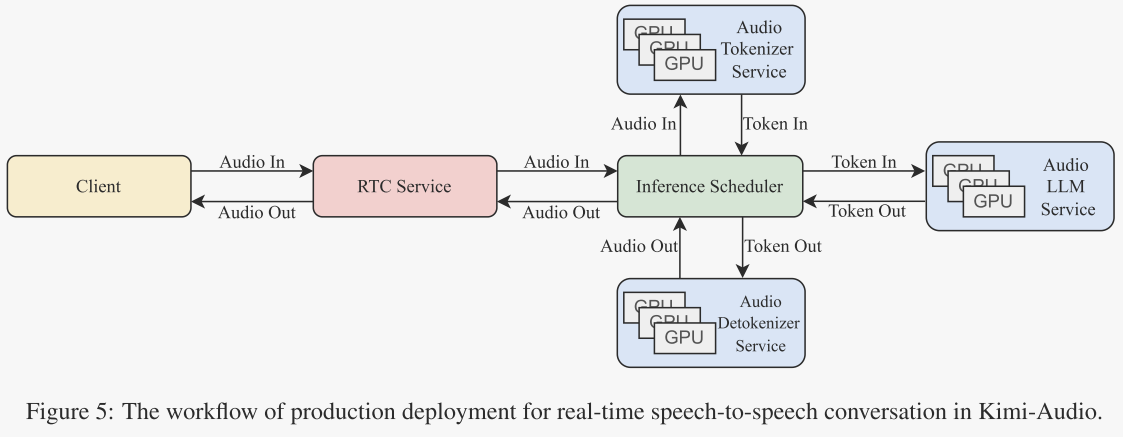
Kimi-Audio RTC服务。该服务与客户端接口,接收用户的音频,将其转发给推理调度器,并将生成的音频块返回给客户端。作者使用WebRTC协议来确保稳定且低延迟的连接。
推理调度器(Inference Scheduler)。推理调度器通过在存储后端维护对话历史的标记来管理对话流程。对于每一轮交互,它执行以下步骤:
- 调用分词器服务,将用户的音频转换为标记。
- 通过将新标记与对话历史结合,构建模型输入。
- 将输入发送到LLM服务,以生成响应标记。
- 调用解码器服务,将响应标记转换为音频输出。
此外,它还将所有输出标记存储为正在进行的对话历史的一部分,以确保对话的连续性。
分词器/解码器/LLM服务(Tokenizer/Detokenizer/LLM Service):这些服务处理模型推理,并配备了负载均衡器和多个推理实例以并行处理请求,确保了可扩展性。
这种模块化架构确保了Kimi-Audio能够有效地扩展,以满足实时语音交互的性能需求,同时在生产环境中保持低延迟和高可用性。
-
评估
评估音频基础模型并与以往的最先进系统进行比较是具有挑战性的,这是由于音频领域存在的一些固有问题。因此,作者首先开发了一个公平、可复现和全面的音频基础模型评估工具包,然后对Kimi-Audio在包括语音识别、通用音频理解、音频到文本的聊天和语音对话在内的多种音频处理任务上进行评估,并将Kimi-Audio与以往的系统进行比较,以展示其优势。
评估工具包
即使一个音频基础模型完全开源,要复现其论文或技术报告中报告的结果仍然很麻烦,更不用说那些闭源模型了。作者分析了在各种音频处理任务中评估和比较音频基础模型所面临的挑战如下:
- 指标的局限性。当前的做法受到不一致的指标实现(例如,由于不同的文本规范化导致单词错误率计算的变化)和不充分的评估方法(例如,仅依赖于精确字符串匹配来评估像音频问答这样的任务,无法捕捉复杂LLM响应的语义正确性)的困扰。
- 多样的配置。模型性能对推理参数(如解码温度、系统提示和任务提示)的高度敏感性严重阻碍了可复现性。
- 缺乏生成评估。虽然在理解任务方面已经取得了进展,但评估生成的音频响应的质量和连贯性仍然缺乏基准。
为了解决这些关键的局限性,作者开发了一个开源的音频基础模型评估工具包,用于音频理解、生成和对话任务。它目前集成并支持Kimi-Audio和一系列最近的音频LLMs,并可用于评估任何其他音频基础模型。该工具包提供以下功能和优势:
- 作者实现了标准化的单词错误率(WER)计算(基于Qwen-2-Audio),并集成了GPT-4o-mini作为智能评判用于音频问答等任务。这种方法克服了不一致的指标和简单字符串匹配的局限性,实现了公平的比较。
- 作者的工具包提供了一个统一的平台,支持多种模型和版本,简化了并排比较。它为定义和共享标准化推理参数和提示策略(“配方”)提供了关键结构,直接解决了评估设置中的不一致性,并促进了不同研究工作中更大的可复现性。
- 作者记录并发布了一个评估基准,用于测试音频LLM在语音对话方面的能力,包括1)情绪、速度和口音的语音控制;2)同理心对话;以及3)多样化的风格,如讲故事和绕口令。
作者将这个工具包开源给社区(https://github.com/MoonshotAI/Kimi-Audio-Evalkit)。
评估结果
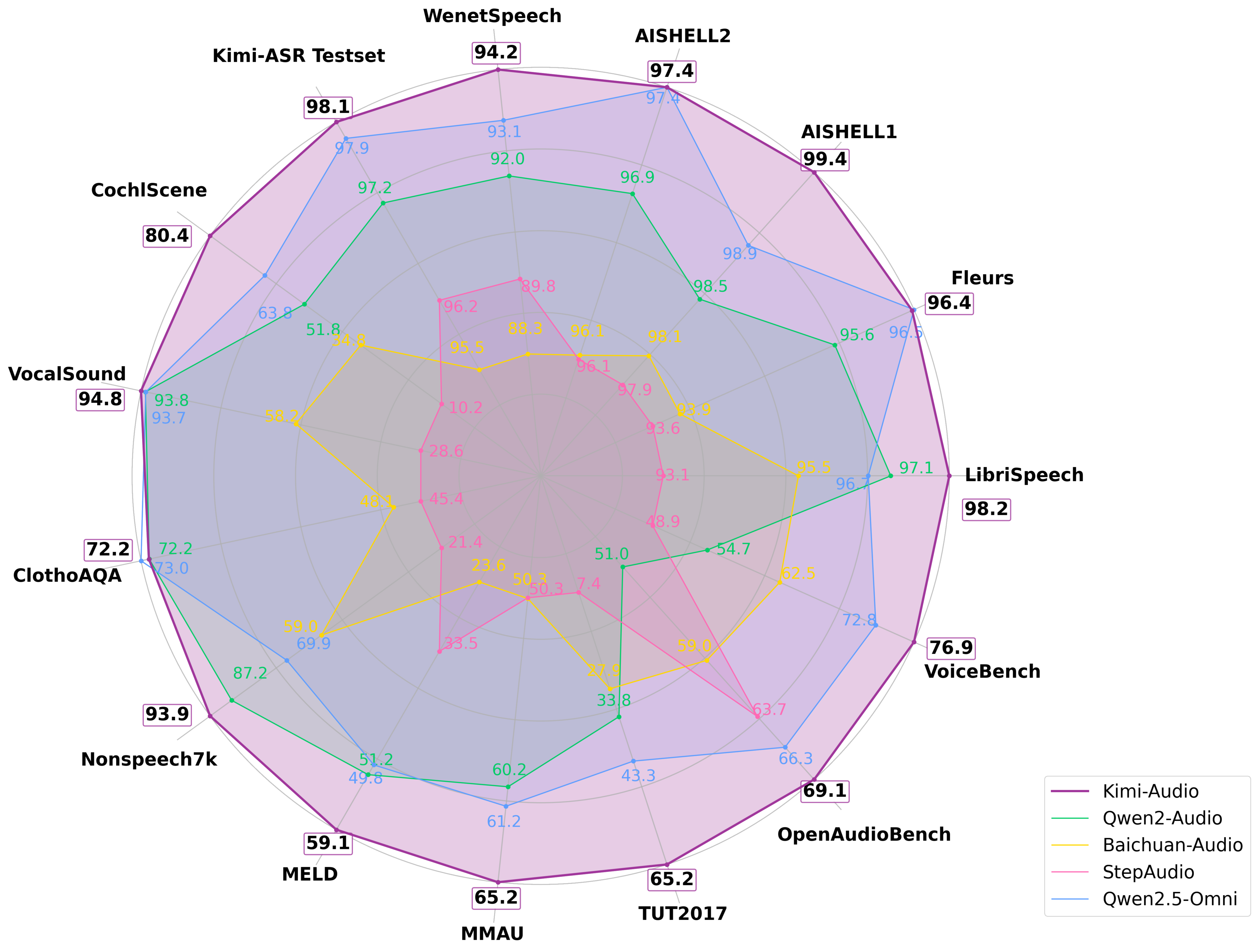
基于上文的评估工具包,作者详细介绍了Kimi-Audio在包括自动语音识别(ASR)、音频理解、音频到文本的聊天以及语音对话在内的一系列全面的音频处理任务上的评估。作者使用已建立的基准测试和内部测试集,将Kimi-Audio与其他音频基础模型(Qwen2-Audio、Baichuan-Audio、Step-Audio、GLM4-Voice和Qwen2.5-Omini)进行了比较。
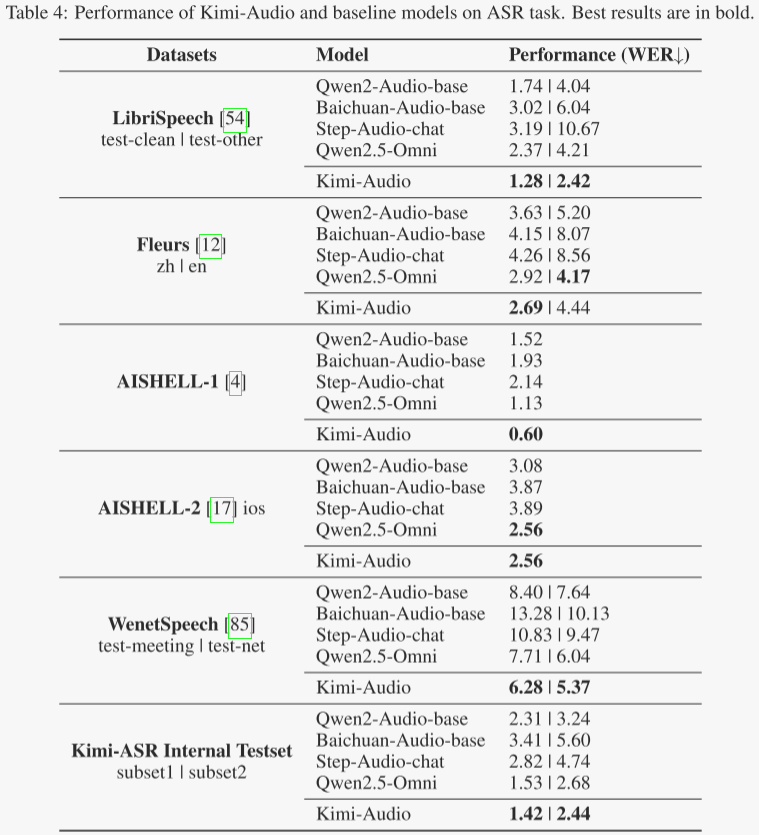
语音识别
Kimi-Audio的自动语音识别(ASR)能力在涵盖多种语言和声学条件的多样化数据集上进行了评估。如表4所示,Kimi-Audio与以往的模型相比,持续展现出更优越的性能。
作者报告了这些数据集上的单词错误率(WER),其中较低的值表示更好的性能。值得注意的是,Kimi-Audio在广泛使用的LibriSpeech基准测试上取得了最佳结果,在test-clean上达到了1.28的错误率,在test-other上达到了2.42的错误率,显著优于Qwen2-Audio-base和Qwen2.5-Omni等模型。对于普通话ASR基准测试,Kimi-Audio在AISHELL-1 (0.60)和AISHELL-2 ios (2.56)上设立了最新最佳结果(SOTA)。此外,它在具有挑战性的WenetSpeech数据集上表现出色,在test-meeting和test-net上都取得了最低的错误率。最后,在我们内部的Kimi-ASR测试集上的评估证实了模型的鲁棒性。这些结果证明了Kimi-Audio在不同领域和语言上的强大的ASR能力。
音频理解
除了语音识别之外,作者还评估了Kimi-Audio理解多样化音频信号的能力,包括音乐、声音事件和语音。表5总结了在各种音频理解基准测试中的性能,其中较高的分数通常表示更好的性能。在MMAU基准测试中,Kimi-Audio在声音类别(73.27)和语音类别(60.66)上展示了卓越的理解能力。同样,在MELD语音情感理解任务上,它也优于其他模型,得分为59.13。Kimi-Audio在涉及非语音声音分类(VocalSound和Nonspeech7k)和声学场景分类(TUT2017和CochlScene)的任务上也处于领先地位。这些结果突显了Kimi-Audio在解释复杂声学信息方面,不仅仅是简单的语音识别,还具有先进的能力。

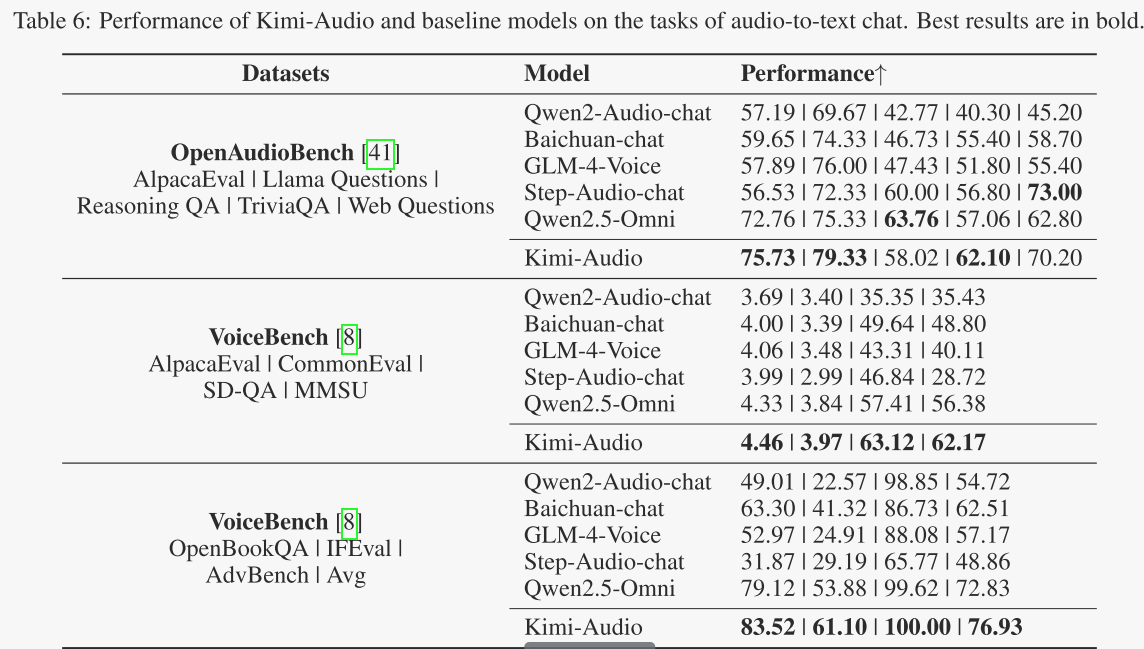
音频-文本对话
作者使用OpenAudioBench和 VoiceBench 基准测试来评估Kimi-Audio基于音频输入进行文本对话的能力。这些基准测试评估了指令遵循、问题回答和推理等多个方面。性能指标是特定于基准测试的,分数越高表示对话能力越好。结果在表6中呈现。
在OpenAudioBench上,Kimi-Audio在多个子任务上取得了最先进的性能,包括AlpacaEval、Llama Questions和TriviaQA,并在Reasoning QA和Web Questions上取得了极具竞争力的性能。VoiceBench评估进一步证实了Kimi-Audio的优势。它在AlpacaEval(4.46)、CommonEval(3.97)、SD-QA(63.12)、MMSU(62.17)、OpenBookQA(83.52)、Advbench(100.00)和IFEval(61.10)上始终优于所有比较的模型。Kimi-Audio在这些全面基准测试中的总体表现证明了它在基于音频的对话和复杂推理任务中的卓越能力。
音频对话
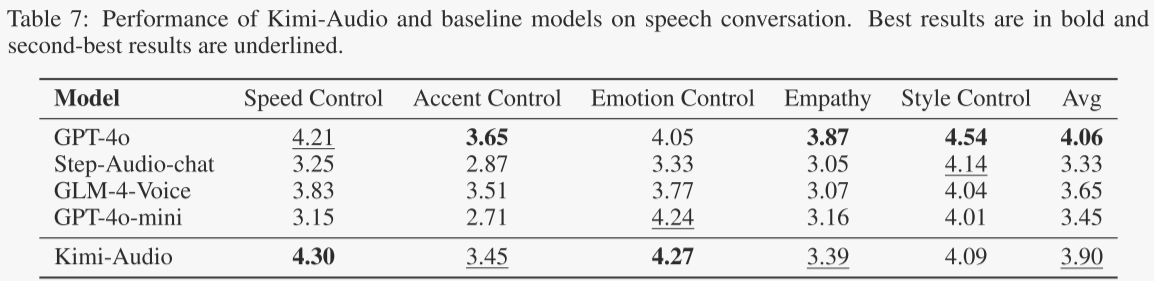
最后,作者基于多个维度的主观评估来评估Kimi-Audio的端到端语音对话能力。如表7所示,Kimi-Audio与GPT-4o和GLM-4-Voice等模型进行了基于人类评分(1-5分,分数越高越好)的比较。除了GPT-4o外,Kimi-Audio在情感控制、同理心和速度控制方面获得了最高分。虽然GLM-4-Voice在口音控制方面略胜一筹,但Kimi-Audio的整体平均得分达到了3.90。这个分数高于Step-Audio-chat(3.33)、GPT-4o-mini(3.45)和GLM-4-Voice(3.65),并且与GPT-4o(4.06)相差不大。总体而言,评估结果证明了Kimi-Audio在生成富有表现力和可控性语音方面的熟练程度。
-
-
3.代码
环境配置
下载代码和权重后,安装以下库
pip install -r requirements.txt
pip install ninja
根据你的版本,下载对应的whl包,然后安装flash-attn:
https://github.com/Dao-AILab/flash-attention/releases/
pip install flash_attn-2.7.3+cu11torch2.4cxx11abiFALSE-cp311-cp311-linux_x86_64.whl -
demo
下面是官方的例子,演示了如何使用kimi-audio将音频转换为文本或进行纯音频交互
import soundfile as sf
from kimia_infer.api.kimia import KimiAudio
# --- 1. 加载模型 ---
model_path = "Kimi-Audio-7B-Instruct"
model = KimiAudio(model_path=model_path, load_detokenizer=False)
# --- 2. 定义采样参数 ---
sampling_params = {
"audio_temperature": 0.8,
"audio_top_k": 10,
"text_temperature": 0.0,
"text_top_k": 5,
"audio_repetition_penalty": 1.0,
"audio_repetition_window_size": 64,
"text_repetition_penalty": 1.0,
"text_repetition_window_size": 16,
}
# --- 3. Example 1: 音频转文本 Audio-to-Text (ASR) ---
messages_asr = [
# You can provide context or instructions as text
{"role": "user", "message_type": "text", "content": "Please transcribe the following audio:"},
# Provide the audio file path
{"role": "user", "message_type": "audio", "content": "test_audios/asr_example.wav"}
]
# 纯文本生成
_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")
print(">>> ASR Output Text: ", text_output) # Expected output: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。"
# --- 4. Example 2: 音频转音频 Audio-to-Audio/Text Conversation ---
messages_conversation = [
# 以音频作为开头
{"role": "user", "message_type": "audio", "content": "test_audios/qa_example.wav"}
]
# 生成音频和文本
wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")
# 保存音频
output_audio_path = "output_audio.wav"
sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # 使用soundfile库将处理后的音频数据以24kHz采样率保存到output_audio_path指定的文件路径。
print(f">>> Conversational Output Audio saved to: {output_audio_path}")
print(">>> Conversational Output Text: ", text_output) # Expected output: "A."
print("Kimi-Audio inference examples complete.")-
generate()
model.generate()根据输入的历史对话内容(chats),生成相应的文本和/或音频输出。
-
检查输出类型:确保
output_type参数的值为"text"或"both"。 -
获取历史对话的提示信息并转换为张量格式:调用
self.prompt_manager.get_prompt方法,将对话历史转换为提示信息。将提示信息转换为张量格式,包括音频输入 ID、文本输入 ID、连续特征和掩码。 -
设置最大生成 token 数:根据
output_type和输入的max_new_tokens参数,动态计算最大生成 token 数。 -
调用
_generate_loop方法生成音频和文本 token:传入音频和文本输入 ID、最大生成 token 数、采样参数等,生成音频和文本的 token 序列。 -
过滤非法 token:
-
对生成的音频 token 进行过滤,移除小于
self.kimia_token_offset的非法 token。 -
对生成的文本 token 进行过滤,移除大于等于
self.kimia_token_offset的非法 token。
-
-
解码生成的文本和音频:调用
self.detokenize_text方法将文本 token 解码为文本字符串。如果output_type是"both"且self.detokenizer已初始化,则调用self.detokenize_audio方法将音频 token 解码为音频数据。 -
返回生成的音频和文本:返回生成的音频数据(
generated_wav)和文本内容(generated_text)。
@torch.inference_mode()
def generate():
assert output_type in ["text", "both"]
# 1.获取历史对话的提示信息,并转换为张量格式
history = self.prompt_manager.get_prompt(chats, output_type=output_type)
audio_input_ids, text_input_ids, is_continuous_mask = history.to_tensor()
audio_features = history.continuous_feature
generated_wav_tokens = []
generated_text_tokens = []
if output_type == "both": # 根据output_type设置最大生成token数max_new_tokens。
max_new_tokens = int(12.5 * 120) - audio_input_ids.shape[1]
else:
if max_new_tokens == -1:
max_new_tokens = 7500 - audio_input_ids.shape[1]
# 将输入数据移动到GPU设备。
audio_input_ids = audio_input_ids.to(torch.cuda.current_device())
text_input_ids = text_input_ids.to(torch.cuda.current_device())
is_continuous_mask = is_continuous_mask.to(torch.cuda.current_device())
audio_features = [f.to(torch.cuda.current_device()) for f in audio_features]
# 2.调用_generate_loop生成音频和文本token。
generated_wav_tokens, generated_text_tokens = self._generate_loop( # 调用 _generate_loop 方法生成音频和文本的 token 序列。
audio_input_ids=audio_input_ids,
text_input_ids=text_input_ids,
max_new_tokens=max_new_tokens,
audio_temperature=audio_temperature,
audio_top_k=audio_top_k,
audio_repetition_penalty=audio_repetition_penalty,
audio_repetition_window_size=audio_repetition_window_size,
text_top_k=text_top_k,
text_temperature=text_temperature,
text_repetition_penalty=text_repetition_penalty,
text_repetition_window_size=text_repetition_window_size,
is_continuous_mask=is_continuous_mask,
continous_feature=audio_features,
output_type=output_type,
)
# 3.过滤非法token
generated_wav_tokens = [
t for t in generated_wav_tokens if t >= self.kimia_token_offset
] # filter out the illegal tokens 对生成的音频 token 进行过滤,移除非法的 token
generated_wav_tokens = torch.tensor(generated_wav_tokens).unsqueeze(0)
generated_wav_tokens = generated_wav_tokens - self.kimia_token_offset
generated_text_tokens = [
t for t in generated_text_tokens if t < self.kimia_token_offset
]
# 4.解码生成的文本和音频。
generated_text = self.detokenize_text(generated_text_tokens)
if self.detokenizer is not None and output_type == "both":
generated_wav = self.detokenize_audio(generated_wav_tokens)
else:
generated_wav = None
return generated_wav, generated_text其中get_prompt() 的主要功能是处理消息列表messages,标记角色和结束标记,并将所有消息合并成一个最终的消息对象。
-
检查输出类型:确保
output_type参数的值为"text"或"both"。 -
初始化变量:
-
初始化一个空列表
msgs,用于存储处理后的消息对象。 -
初始化布尔变量
tokenize_role、has_ct_token和has_msg_end_token,用于控制消息的标记和结束标记。
-
-
遍历消息列表:
-
遍历输入的
messages列表,逐条处理消息。 -
根据当前消息的角色与前一条消息的角色是否相同,决定是否需要标记角色。
-
根据当前消息是否为最后一条消息,或者下一条消息的角色是否不同,设置是否需要添加结束标记。
-
-
处理每条消息:
-
调用
self.tokenize_message方法对每条消息进行处理,传入当前消息、角色标记标志、结束标记标志等参数。 -
将处理后的消息对象添加到
msgs列表中。
-
-
生成 AI 起始消息:调用
self.tokenize_message方法生成一个 AI 起始消息对象,并将其追加到msgs列表中。 -
合并所有消息:从
msgs列表的第一个消息对象开始,依次调用merge方法将所有消息对象合并成一个最终的消息对象ret_msg。
def get_prompt() -> KimiAContent:
assert output_type in ["text", "both"]
msgs: List[KimiAContent] = [] # msgs 存储处理后的消息
tokenize_role = True
has_ct_token = False
has_msg_end_token = False
previous_role = None
for msg_idx, message in enumerate(messages):
assert message["role"] in ["user", "assistant"]
if previous_role is None: # 根据当前消息与前一条消息的角色是否相同,决定是否需要标记角色 (tokenize_role)。
tokenize_role = True
else:
if message["role"] == previous_role:
tokenize_role = False
else:
tokenize_role = True
if msg_idx == len(messages) - 1: # 根据当前消息是否为最后一条或下一条消息的角色是否不同,设置 has_ct_token 和 has_msg_end_token。
has_ct_token = True
has_msg_end_token = True
else:
if messages[msg_idx + 1]["role"] != message["role"]:
has_ct_token = True
has_msg_end_token = True
else:
has_ct_token = False
has_msg_end_token = False
previous_role = message["role"]
msg = self.tokenize_message( # 对每条消息进行处理,并将结果添加到 msgs 列表中。
message=message,
tokenize_role=tokenize_role,
has_ct_token=has_ct_token,
has_msg_end_token=has_msg_end_token,
extract_whisper_feature=True,
output_type=output_type,
)
msgs.append(msg)
assistant_start_msg = self.tokenize_message( # # 调用 self.tokenize_message 方法生成AI起始消息,并追加到 msgs 列表。
message={
"role": "assistant",
"message_type": None,
},
tokenize_role=True,
has_ct_token=False,
has_msg_end_token=False,
)
msgs.append(assistant_start_msg)
ret_msg = msgs[0]
for msg in msgs[1:]: # 从 msgs 中的第一个消息开始,依次调用 merge 方法将所有消息合并成一个最终消息。
ret_msg.merge(msg)
return ret_msg其中_generate_loop() ,用于生成音频和文本的 token 序列。它是一个循环生成过程,每次生成一个 token,直到达到指定的最大生成数量或生成结束标记。
-
初始化采样器:创建
KimiASampler实例,用于生成文本和音频的下一个 token。 -
设置初始状态变量:初始化文本和音频的 token 缓存、解码器输入 ID、位置 ID 和其他相关变量。
-
循环生成 token:
-
在循环中,调用模型
self.alm.forward获取音频和文本的 logits。 -
使用采样器生成下一个文本和音频 token。
-
根据生成的 token 更新状态变量,并判断是否结束生成。
-
-
判断生成结束条件:如果文本流结束(
text_stream_is_finished)且输出类型为"text",或音频流结束(audio_stream_is_finished)且输出类型为"both",则提取有效 token 并返回。 -
更新解码器输入:如果未达到结束条件,更新解码器的输入 ID、位置 ID 和其他相关变量,继续生成下一个 token。
-
提取有效 token:循环结束后,从缓存中提取有效的文本和音频 token。
-
返回结果:返回生成的音频 token 和文本 token 列表。
@torch.inference_mode()
def _generate_loop(
self,
audio_input_ids: torch.Tensor, # input audio tokens
text_input_ids: torch.Tensor = None, # input text tokens if use multi-input
max_new_tokens: int = 50,
audio_top_k: int = 5,
audio_temperature: float = 0.0,
audio_repetition_penalty: float = 1.0,
audio_repetition_window_size: int = 64,
text_top_k: int = 5,
text_temperature: float = 0.0,
text_repetition_penalty: float = 1.0,
text_repetition_window_size: int = 16,
is_continuous_mask: torch.Tensor = None,
continous_feature: torch.Tensor = None,
output_type: str = "text",
):
# 1.初始化采样器 KimiASampler,用于生成文本和音频的下一个 token。
sampler = KimiASampler(
audio_top_k=audio_top_k,
audio_temperature=audio_temperature,
audio_repetition_penalty=audio_repetition_penalty,
audio_repetition_window_size=audio_repetition_window_size,
text_top_k=text_top_k,
text_temperature=text_temperature,
text_repetition_penalty=text_repetition_penalty,
text_repetition_window_size=text_repetition_window_size,
)
# 2.设置初始状态变量
text_stream_is_finished = False
previous_audio_tokens = torch.zeros(
(4096,),
dtype=torch.int,
device=torch.cuda.current_device(),
)
text_previous_tokens = torch.zeros(
(4096,),
dtype=torch.int,
device=torch.cuda.current_device(),
)
decoder_input_audio_ids = audio_input_ids.clone()
decoder_input_text_ids = text_input_ids.clone()
decoder_position_ids = (
torch.arange(
0, decoder_input_audio_ids.shape[1], device=torch.cuda.current_device()
)
.unsqueeze(0)
.long()
)
decoder_input_whisper_feature = continous_feature
decoder_is_continuous_mask = is_continuous_mask
past_key_values = None
last_position_id = decoder_input_audio_ids.shape[1] - 1
valid_text_length = 0
valid_audio_length = 0
# 3.使用循环生成指定数量的 token
for i in tqdm.tqdm(
range(max_new_tokens), desc="Generating tokens", disable=False
):
audio_logits, text_logits, past_key_values = self.alm.forward( # 调用模型 self.alm.forward 获取音频和文本的 logits。
input_ids=decoder_input_audio_ids,
text_input_ids=decoder_input_text_ids,
whisper_input_feature=decoder_input_whisper_feature,
is_continuous_mask=decoder_is_continuous_mask,
position_ids=decoder_position_ids,
past_key_values=past_key_values,
return_dict=False,
)
# 3.1 使用采样器生成下一个文本和音频 token。
# Sample text token using the sampler
next_token_text = sampler.sample_text_logits(
text_logits, recent_tokens=text_previous_tokens[:i] if i > 0 else None
)
# Sample audio token using the sampler
next_audio_token = sampler.sample_audio_logits(
audio_logits, recent_tokens=previous_audio_tokens[:i] if i > 0 else None
)
# 3.2 根据生成的 token 更新状态变量,判断是否结束生成。
if text_stream_is_finished:
next_token_text.fill_(self.extra_tokens.kimia_text_blank)
elif next_token_text.item() == self.extra_tokens.kimia_text_eos:
text_stream_is_finished = True
else:
valid_text_length += 1
text_previous_tokens[i : i + 1] = next_token_text # 将 next_token_text 替换到 text_previous_tokens 的第 i 个位置。
if i < self.kimia_text_audiodelaytokens: # 如果当前索引 i 小于 self.kimia_text_audiodelaytokens,将 next_audio_token 填充为 kimia_text_blank。
next_audio_token.fill_(self.extra_tokens.kimia_text_blank)
else:
if output_type == "text": # 如果是 "text",同样填充为 kimia_text_blank。
next_audio_token.fill_(self.extra_tokens.kimia_text_blank)
else: # 如果不是 "text",增加 valid_audio_length 的计数。
valid_audio_length += 1
previous_audio_tokens[i : i + 1] = next_audio_token # 将 next_audio_token 替换到 previous_audio_tokens 的第 i 个位置。
audio_stream_is_finished = next_audio_token.item() in self.eod_ids # 检查 next_audio_token 是否在 self.eod_ids 中,判断音频流是否结束。
if ( # 如果 output_type 为 "text" 且 text_stream_is_finished 为真,或 output_type 为 "both" 且 audio_stream_is_finished 为真,则提取并返回 text_tokens 和 audio_tokens。
output_type == "text"
and text_stream_is_finished
or output_type == "both"
and audio_stream_is_finished
):
return_text_tokens = (
text_previous_tokens[:valid_text_length]
.detach()
.cpu()
.numpy()
.tolist()
)
return_audio_tokens = (
previous_audio_tokens[
self.kimia_text_audiodelaytokens : valid_audio_length
+ self.kimia_text_audiodelaytokens
]
.detach()
.cpu()
.numpy()
.tolist()
)
return return_audio_tokens, return_text_tokens
else: # 否则,更新音频和文本的解码器输入 ID、位置 ID,并初始化相关特征变量。
decoder_input_audio_ids = next_audio_token.unsqueeze(1)
decoder_input_text_ids = next_token_text.unsqueeze(1)
decoder_position_ids = (
torch.zeros(1, 1, device=torch.cuda.current_device())
.fill_(last_position_id + 1)
.long()
.view(1, 1)
)
last_position_id += 1
decoder_input_whisper_feature = None
decoder_is_continuous_mask = None
# 4.从text_previous_tokens和previous_audio_tokens中提取有效的文本和音频标记
return_text_tokens = (
text_previous_tokens[:valid_text_length].detach().cpu().numpy().tolist()
)
return_audio_tokens = (
previous_audio_tokens[
self.kimia_text_audiodelaytokens : valid_audio_length
+ self.kimia_text_audiodelaytokens
]
.detach()
.cpu()
.numpy()
.tolist()
)
return return_audio_tokens, return_text_tokens其中detokenize_text(),其主要功能是将输入的文本 token 列表解码为可读的文本字符串。
def detokenize_text(self, text_tokens): # 将输入的 text_tokens 列表解码为文本字符串
valid_text_ids = [] # 初始化一个空列表 valid_text_ids,用于存储有效的 token ID。
for x in text_tokens: # 遍历 text_tokens,如果遇到 self.extra_tokens.kimia_text_eos(表示文本结束的特殊 token),则停止遍历。
if x == self.extra_tokens.kimia_text_eos:
break
valid_text_ids.append(x) # 将有效 token ID 添加到 valid_text_ids 中。
return self.prompt_manager.text_tokenizer.decode(valid_text_ids) # 解码并返回结果detokenize_audio() ,用于将输入的音频 token 序列解码为音频数据。它通过分块处理和流式解码的方式,逐步生成音频信号。
-
检查解码器是否初始化:如果
self.detokenizer未初始化,抛出异常。 -
清除解码器状态:调用
self.detokenizer.clear_states()清除解码器的内部状态。 -
设置分块大小:设置第一个音频块的大小为
first_chunk_size,后续块的大小为chunk_size。 -
初始化缓存列表:初始化一个列表
cache_speech_collection,用于存储解码后的音频块。 -
将音频 token 移动到 GPU:将输入的
audio_tokens移动到当前 GPU 设备,并转换为整数类型。 -
获取音频 token 的总数:获取
audio_tokens的总数量num_audio_tokens。 -
解码第一个音频块:提取第一个音频块(大小为
first_chunk_size)。调用self.detokenizer.detokenize_streaming解码第一个音频块,并将结果存入缓存列表。 -
解码剩余音频块:如果音频块数量超过
first_chunk_size,对剩余音频块按chunk_size分块处理。逐块调用self.detokenizer.detokenize_streaming解码,并将结果存入缓存列表。 -
拼接解码结果:将所有解码后的音频块拼接成最终的音频输出。
def detokenize_audio(self, audio_tokens):
if self.detokenizer is None: # 检查 self.detokenizer 是否已初始化,若未初始化则抛出异常。
raise ValueError("Detokenizer is not initialized")
self.detokenizer.clear_states() # 调用 detokenizer.clear_states() 清除解码器状态。
chunk_size = 30 # hard-coded right now
first_chunk_size = 30
cache_speech_collection = []
audio_tokens = audio_tokens.to(torch.cuda.current_device()) # 将输入的 audio_tokens 移动到当前GPU设备并转换为整数类型。
audio_tokens = audio_tokens.long()
num_audio_tokens = audio_tokens.size(1)
first_chunk_semantic_tokens = audio_tokens[:, :first_chunk_size] # 提取第一个音频块(大小为 first_chunk_size),调用 detokenizer.detokenize_streaming 进行解码,并将结果存入缓存列表。
gen_speech = self.detokenizer.detokenize_streaming(
first_chunk_semantic_tokens,
is_final=(num_audio_tokens <= first_chunk_size),
upsample_factor=4,
)
cache_speech_collection.append(gen_speech)
if num_audio_tokens > first_chunk_size: # 如果音频块数量超过 first_chunk_size,对剩余音频块按 chunk_size 分块处理,逐块解码并将结果存入缓存列表。
res_semantic_tokens = audio_tokens[:, first_chunk_size:]
for i in range(0, res_semantic_tokens.size(1), chunk_size):
chunk_semantic_tokens = res_semantic_tokens[:, i : i + chunk_size]
gen_speech = self.detokenizer.detokenize_streaming(
chunk_semantic_tokens,
upsample_factor=4,
is_final=(i + chunk_size >= res_semantic_tokens.size(1)),
)
cache_speech_collection.append(gen_speech)
gen_speech = torch.cat(cache_speech_collection, dim=-1) # 将所有解码结果拼接成最终的音频输出并返回。
return gen_speech-
-
4.总结
尽管Kimi-Audio在构建通用音频基础模型方面取得了显著进展,但在寻求更强大的智能音频处理系统的过程中,仍然存在一些挑战。作者描述了这些挑战,并指出了几个令人兴奋的未来发展方向,如下所述。
- 从音频转录到音频描述。当前音频基础模型的预训练范式通常利用音频-文本预训练来弥合文本和音频之间的差距,其中文本是通过ASR转录从音频(语音)中获得的。然而,文本转录侧重于口语内容(说了什么),忽略了音频中的重要信息,如副语言信息(例如,情感、风格、音色、语调)、声学场景和非语言声音。因此,引入描述性文本(即音频字幕)以在更丰富的上下文中描绘音频是很重要的。结合音频的转录文本和描述文本使模型能够更好地理解和生成不仅包括口语,还包括复杂声学环境的内容,为更细致、多模态的音频处理系统铺平道路,从而实现更通用和多功能的音频智能。
- 更好的音频表示。当前的音频利用语义标记或声学标记作为其表示。语义标记通常是通过基于ASR的辅助损失获得的,它侧重于转录导向的信息,未能捕捉对理解和生成至关重要的丰富声学细节。声学标记通常通过音频重建损失学习,它侧重于描述导向的声学细节,未能捕捉对连接文本智能至关重要的抽象语义信息。一个有价值的研究方向是开发整合转录导向的语义信息和描述导向的声学特征的表示,包括说话者身份、情感和环境声音等细微差别,同时保持对更复杂的音频理解和生成至关重要的高级抽象信息。
- 在音频建模中抛弃ASR和TTS。当前的音频基础模型在预训练和微调阶段都严重依赖ASR和TTS来生成训练数据。训练数据的质量受到ASR文本识别准确性和TTS合成语音的表现力/多样性/质量的限制。通过这种方式,音频模型表现得像现有ASR和TTS系统的复杂蒸馏。因此,它们很难实现远远超出ASR/TTS上限的性能,也无法实现真正的自主音频智能。一个重要的未来发展方向是训练不依赖于基于ASR/TTS的伪音频数据,而是依赖于原生音频数据的音频模型,这可以带来更高的性能上限。
🌟 如果我的内容对你有帮助,记得点赞👍,让更多人也能发现这些有用的信息!
📚 想随时获取更多干货?点击关注,不错过任何精彩更新!
💖 你的支持是我不断创作的动力,感谢每一个点赞、收藏和关注!一起成长,一起进步!

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









