







参考文献
主要参考的文章,写的很好
对于整个NLP的介绍都很到位
张俊林老师的介绍
主要内容
前置知识
bert实际上是采用transformer的结构,可以先了解下transformer的结构。下文也有少许的介绍,具体可以查看 本文
Seq2Seq 到 Attention
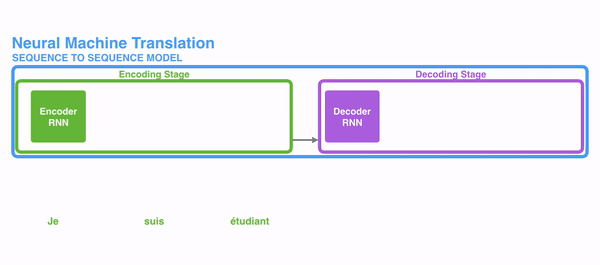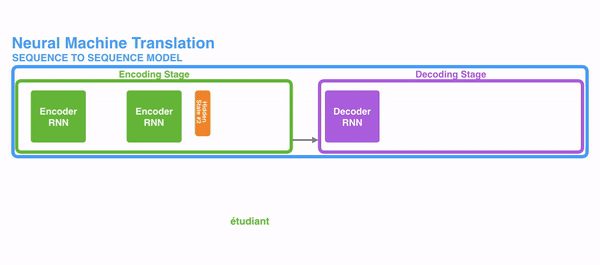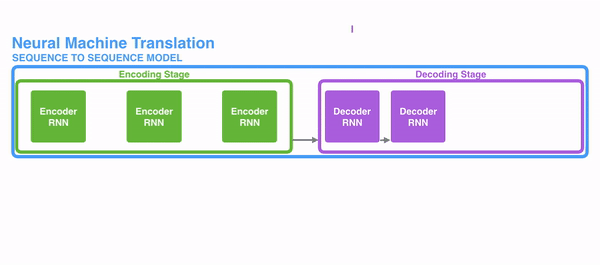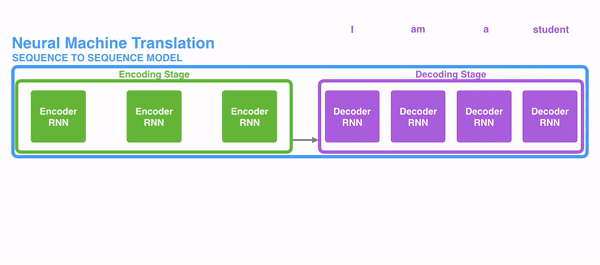
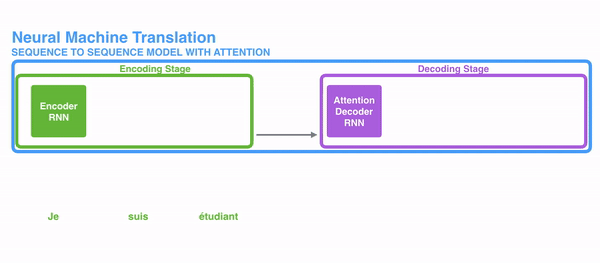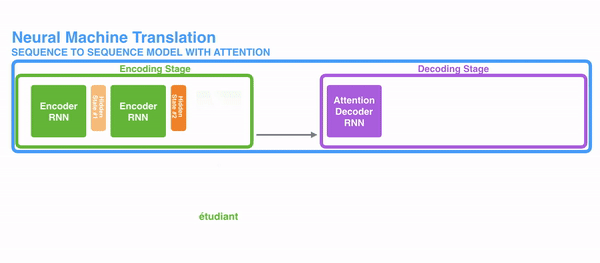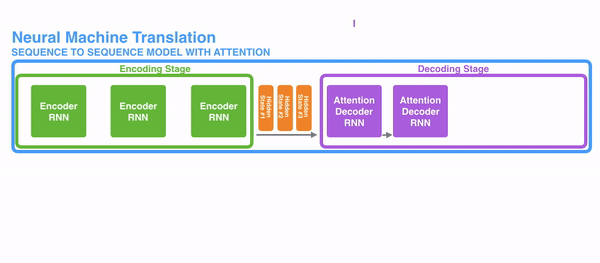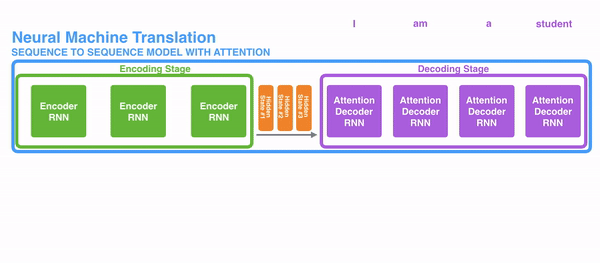
传统的机器翻译基本都是基于Seq2Seq模型来做的,该模型分为encoder层与decoder层,并均为RNN或RNN的变体构成,如下图所示:
注意力机制可以使得在进行文本句子训练的时候,可以很好的掌握上下文信息,并且根据一定的权重去调整对上下文每个词的注意力。
Attention,正如其名,注意力,该模型在decode阶段,会选择最适合当前节点的context作为输入。Attention与传统的Seq2Seq模型主要有以下两点不同。
1)encoder提供了更多的数据给到decoder,encoder会把所有的节点的hidden state提供给decoder,而不仅仅只是encoder最后一个节点的hidden state。如图:
 2)decoder并不是直接把所有encoder提供的hidden state作为输入,而是采取一种选择机制,把最符合当前位置的hidden state选出来,具体的步骤如下
2)decoder并不是直接把所有encoder提供的hidden state作为输入,而是采取一种选择机制,把最符合当前位置的hidden state选出来,具体的步骤如下
确定哪一个hidden state与当前节点关系最为密切
计算每一个hidden state的分数值(具体怎么计算我们下文讲解)
对每个分数值做一个softmax的计算,这能让相关性高的hidden state的分数值更大,相关性低的hidden state的分数值更低。
这里我们以一个具体的例子来看下其中的详细计算步骤:

把每一个encoder节点的hidden states的值与decoder当前节点的上一个节点的hidden state相乘,如上图,h1、h2、h3分别与当前节点的上一节点的hidden state进行相乘(如果是第一个decoder节点,需要随机初始化一个hidden state),最后会获得三个值,这三个值就是上文提到的hidden state的分数,注意,这个数值对于每一个encoder的节点来说是不一样的,把该分数值进行softmax计算,计算之后的值就是每一个encoder节点的hidden states对于当前节点的权重,把权重与原hidden states相乘并相加,得到的结果即是当前节点的hidden state。可以发现,其实Atttention的关键就是计算这个分值。
明白每一个节点是怎么获取hidden state之后,接下来就是decoder层的工作原理了,其具体过程如下:
第一个decoder的节点初始化一个向量,并计算当前节点的hidden state,把该hidd
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









