






BERT(Bidirectional Encoder Representations from Transformers)是一种预训练模型,由Google在2018年提出。它采用了Transformer网络结构,并通过无监督的方式对大规模文本进行训练,以学习出文本的语义表示,可以用于各种自然语言处理任务,例如文本分类、命名实体识别、问答等。在本文中,我们将详细介绍BERT模型的原理。
1. Transformer模型
BERT模型基于Transformer模型,因此我们需要首先了解Transformer模型的结构。
Transformer模型由Vaswani等人在2017年提出,它采用了注意力机制(attention mechanism),用于捕捉输入序列之间的依赖关系。Transformer模型由编码器(encoder)和解码器(decoder)两部分组成,本文仅讨论编码器部分,如下图所示:
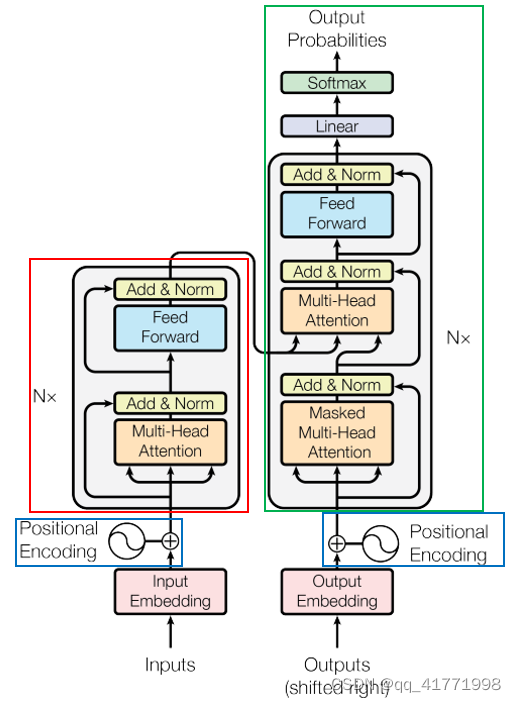
在编码器中,输入序列首先通过一个嵌入层(embedding layer)转换为向量表示。这个向量表示会作为输入序列的初始表示,在经过多层的自注意力机制(self-attention)和前馈神经网络(feed-forward neural network)之后,得到输出序列的表示。
具体来说,自注意力机制是指对于输入序列中的每个位置,计算它与其他所有位置的相似度,然后根据相似度得到每个位置对其他位置的权重分配,最终将所有位置的表示加权求和。这个过程可以看作是对输入序列进行一种特殊的聚合操作,从而得到更全面、更丰富的表示。
前馈神经网络是指由两个全连接层组成的网络,其中每个层之间都有一个激活函数(如ReLU)作为非线性变换。这个网络可以将输入序列的表示进行一次映射,从而得到更高维、更复杂的表示。
Transformer模型的特点是可以进行并行计算,因此在训练和推理时都具有较高的效率。在自然语言处理任务中,Transformer模型已经被证明可以取得非常好的性能。
2. BERT模型
BERT模型是基于Transformer模型的,但是与原始的Transformer模型不同,它采用了双向(bidirectional)训练方式,并且通过预训练和微调两个步骤来完成自然语言处理任务。
2.1 双向训练
双向训练是指在预训练阶段,BERT模型可以同时利用输入序列的左侧和右侧上下文信息。这个过程类似于语言模型(language modeling),但是不同于传统的语言模型,BERT模型不仅考虑了当前词语的上下文,还考虑了整个输入序列的上下文信息。
具体来说,BERT模型在预训练阶段有两个任务:掩码语言建模(masked language modeling)和下一句预测(next sentence prediction)。
掩码语言建模任务是指在输入序列中随机掩盖一些词语,并让BERT模型预测这些词语的原始形式。这个任务可以让模型学习到在不完整的上下文信息下进行预测的能力。
下一句预测任务是指给定两个句子,判断它们是否是连续的。这个任务可以让模型学习到理解上下文之间的关系和文本之间的关系。
通过这两个任务,BERT模型可以学习到更全面、更准确的语义表示,从而在各种自然语言处理任务中取得更好的性能。
2.2 预训练和微调
BERT模型的预训练和微调两个步骤。
在预训练阶段,BERT模型采用大规模无标注数据进行训练,学习出通用的语义表示。在微调阶段,BERT模型根据具体的任务和标注数据,通过微调预训练好的模型参数,得到针对特定任务的模型。
具体来说,微调阶段包括以下几个步骤:
-
在微调数据集上进行标注,例如文本分类任务中的标注分类标签。
-
使用预训练好的BERT模型作为初始模型,然后在微调数据集上进行有监督的训练。
-
在微调过程中,可以冻结预训练模型的前几层,只训练新添加的全连接层,也可以对整个模型进行微调。
通过预训练和微调两个步骤,BERT模型可以灵活地适应各种自然语言处理任务,并取得非常好的性能。
3. 总结
BERT模型是一种基于Transformer模型的预训练模型,通过双向训练、掩码语言建模和下一句预测等技术,学习出通用的语义表示。在微调阶段,可以根据具体的任务和标注数据,通过微调预训练好的模型参数,得到针对特定任务的模型。BERT模型已经在各种自然语言处理任务中取得了非常好的性能,是自然语言处理领域的一项重要
技术进展,也为人们提供了更好的语言处理工具。
虽然BERT模型已经取得了非常好的性能,但是它还存在一些局限性。例如,BERT模型对于长文本的处理效果并不理想,因为它采用了固定长度的输入序列。此外,BERT模型在处理一些特定的任务时可能会出现一些不足,需要根据具体情况进行调整和改进。
未来,随着人工智能技术的不断发展,BERT模型以及其他预训练模型的性能将得到进一步提升,并在更广泛的应用场景中得到应用。
















 8393
8393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











