






 这篇博客回顾了机器学习笔试中常见的选择题、问答题和编程题,涵盖了SVM模型优化、卷积神经网络的特征图计算、避免连续相同字符的字符串构造以及寻找数组中特定序列的最大值等题目。博主提供了详细的解析和示例代码,对于准备机器学习笔试和提升相关技能很有帮助。
这篇博客回顾了机器学习笔试中常见的选择题、问答题和编程题,涵盖了SVM模型优化、卷积神经网络的特征图计算、避免连续相同字符的字符串构造以及寻找数组中特定序列的最大值等题目。博主提供了详细的解析和示例代码,对于准备机器学习笔试和提升相关技能很有帮助。
8月13日练习往年笔试题
笔试链接中给出了题目类型
8月14日笔试后更新:测试给出的题型不正确,应该是5道单选,5道多选,3道问答题和1道算法编程题
这里给出一个大佬总结的往年题目以及相应的解析,很详细,非常值得一看:机器学习笔试题目_北冥有小鱼的博客-CSDN博客_机器学习题目
其余往年题目总结:
选择题1
如果SVM模型欠拟合, 以下方法哪些可以改进模型 :
A. 增大惩罚参数C的值
B. 减小惩罚参数C的值
C. 减小核系数(gamma参数)
答案: A
如果SVM模型欠拟合, 我们可以调高参数C的值, 使得模型复杂度上升.
SVM中,SVM的目标函数是: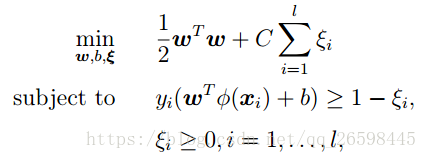
gamma参数是你选择径向基函数作为kernel后,该函数自带的一个参数.隐含地决定了数据映射到新的特征空间后的分布.gamma参数越高, 模型越复杂.虽说gamma参数与C参数无关.但C是gamma前的调节系数,也会影响模型复杂度。
选择题1涉及知识:过拟合是模型太复杂了,欠拟合是模型复杂度不够。
问答题1
一个200*200的图像,经过5*5的卷积滤波器,padding = 1 , stride = 2; 再经过3X3的最大池化层,其中stride = 1,no padding; 再经过一个卷积层,其中padding = 1, kernal = 3,stride = 1,问所得到的feature map的尺寸是多大。 计算方法:卷积神经网络(CNN)张量(图像)的尺寸和参数计算(深度学习) - 冂冋冏囧 - 博客园
1.特征图尺寸的答案是
2.感受野的计算
2.1 感受野的计算:RFn=RFn-1 + (kn-1)*stride_n,其中stride_n表示的是第n次卷积的移动步幅stride。注意求解过程是从RF1开始的,RF1一定为第一个卷积核的尺寸大小
2.2 需要注意的不能通过计算输出特征图的尺寸推算感受野,这其中设计步长调整感受野。如20x20的输入,第一层k=3,s=2,第二层k=3,s=2。第一层过后输出为9x9,感受野为3.第二程后输出为4x4,公式计算感受野为7,而不是20/4=5
编程题1:一个数组a[0...n-1],求a[j]-a[i]+a[q]-a[p]的最大值,其中i<j<p<q
#算法解析:借鉴a[j]-a[i]的最大值,先把数组分为两段,每一段按单独算法执行,也就是先把该段
前面一截的最小值找出,后面一截的最大值找出。然后算出最大值,同理算出第二段最大值,相加得赋值为max,如果更大则替换。
def getmax(array):
arrlen=len(array)-1
arraymax = [-100000] #这里赋初值时要尽可能的小,以防max-min是小于0的一些数而导致没记录。
for i in range(1,arrlen+1):
prearray=array[:i]
endarray=array[i:]
prelen=len(prearray)
endlen=len(endarray)
#每次重新循环时都会被初始化,必须在for循环外部加一个存储空间,防止最大值被初始化。
min = prearray[0]
max = endarray[0]
if max-min>arraymax[0]:
arraymax[0]=max-min
for i in range(prelen):
if array[i]<min:
min=array[i]
for i in range(endlen):
if array[i]>max:
max=array[i]
return arraymax[0]
if __name__ == '__main__':
array=[1,2,3,9,6,4,2,1]
slen=len(array)-2
max1 = 0
max2 = 0
totalmax = max1 + max2
for i in range(2,slen+1):
array1=array[0:i]
array2=array[i:]
max1=getmax(array1)
max2=getmax(array2)
totalmax = max1+max2
if max1+max2>totalmax:
totalmax=max1+max2
print(totalmax)编程题2:n个字母A,m个字母B组合成n+m字符串满足连续3个不为同一字符
# coding:utf-8
# n->A
# m->B
#输入n和m,构造一个n+m长度的字符串。正好有n个A,m个B。
# 不能有三个相同的字母连续出现。任意写出来一个组合输出
def construct(m, n, size):
if max(m, n) <= min(m, n) * 2 + 2:
dif = 0
res = ""
if m < n:
dif = n - m - 2 if n - m >= 2 else n - m
i = 1
while i <= m:
if i <= dif:
res += "AAB"
else:
res += "AB"
i += 1
res += "AA" if n - m >= 2 else ""
return res
else:
dif = m - n - 2 if m - n >= 2 else m - n
i = 1
while i <= n:
if i <= dif:
res += "BBA"
else:
res += "BA"
i += 1
res += "BB" if m - n >= 2 else ""
return res
else:
return res
if __name__ == "__main__":
m = 12
n = 5
ans = construct(m, n, 3)
print(ans)编程题3:LeetCode869重新排列得到2的幂
class Solution:
def reorderedPowerOf2(self, n: int) -> bool:
# lowbit判断是否为2的幂
def check(A):
x=0
for a in A:
x=x*10+int(a)
return x&(x-1)==0
arr=list(str(n))
# 排序
arr.sort()
n=len(arr)
visited=set()
# 计算全排列
def permutations(nums):
if len(nums)==n and check(nums):
return True
for i,num in enumerate(arr):
# 首项不为0
if not nums and arr[i]=='0':continue
# 去重
if i>0 and arr[i]==arr[i-1] and i-1 not in visited:continue
if i not in visited:
visited.add(i)
if permutations(nums+[arr[i]]):
return True
visited.remove(i)
return False
return permutations([])
class Solution:
def reorderedPowerOf2(self, n: int) -> bool:
cnt=Counter(str(n))
# 因为n<10^9,而2^31>10^9所以枚举到2^31即可
for i in range(32):
x=1<<i
if Counter(str(x))==cnt:
return True
return False
编程题4:存在一个数组,求一个k值,使得前k个数的方差 + 后面n-k个数的方差最小 ,时间复杂度可以到O(n)
def minVariance(arr, length=None):
sum=0
square_sum=0
length=len(arr)
left_var=[0]*length
right_var=[0]* length#从左到右求每一段的方差
for i in range(length):
sum+=arr[i]
square_sum+=arr[i]*arr[i]
left_var[i]=square_sum/(i+1)-(sum/(i+1))**2
sum = 0
square_sum = 0 #从右到左求每一段的方差
for j in range(length-1,-1,-1):
sum+=arr[j]
square_sum += arr[j] * arr[j]
right_var[j] = square_sum / (length-j) - (sum / (length-j)) ** 2
#二者合并,找出方差最小的两断
index=0
variance=left_var[0]+right_var[0]
for k in range(length-1):
if left_var[k]+right_var[k+1]<variance:
variance=left_var[k]+right_var[k]
index=k+1
return index
res = minVariance([1, 2, 3, 4, 5, 6])
print(res)8月14日笔试后回忆题目
这里给出一个大佬总结的往年题目以及响应的解析,很详细,非常值得一看,就算不为了笔试也值得用来学习:机器学习笔试题目_北冥有小鱼的博客-CSDN博客_机器学习题目
单选题
1.在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题
A 增加训练集量 B 减少神经网络隐藏层节点数
C 删除稀疏的特征 D SVM算法中使用高斯核/RBF核代替线性核
正确答案:D,过拟合就是模型过于复杂或者数据多样性差,D会使模型更加复杂
2.使用高通芯片情况下,找到了一个VGG网络,比MobileNet要快,为什么
A VGG整体只使用了一种算子 B VGG带宽大
D DW的利用率不高
3.机器人小D判卷子,老师不能具体到每一个题都给出正确答案,只能给每张卷子打一个分,这属于哪种学习模型
A 有监督学习 B无监督学习 C强化学习 D深度学习
4.大疆有80%的人喜欢摄影。今天来的人中10%的人是大疆员工,有50%的人喜欢摄影,问到一个会摄影的小哥哥,它是大疆员工的概率
A 10% B 8% C 80% D 50%
5.感受野的计算,涉及填充和池化操作是否会改变感受野
多选题
1.提高train acc的方法
2.一个模型在训练后得到train acc和test acc分别是91% 63%,下列哪种情况可能会发生
A 增大testdata数量test acc提升至90%
B 增大testdata数量test acc降低至54%
C 增大traindata数量train acc提升至93%
D 增大traindata数量train acc降低至53%
3.SVM的描述,错误的是
A 使用线性核的SVM是线性模型
4.一个特征图在使用激活函数后产生-5,10的结果,可能使用了哪种激活函数
Asigmoid B relu C tanh D leaky
5.下面属于减小过拟合的方法
改变BatchSize和Weight Delacy可改变过拟合吗
问答题
1.大疆产品丰富,用户使用场景五花八门。但由于用户隐私限制,数据不允许回传,此种情况下我们若是仍想提升模型的精度,可以采取哪些方法。
2.Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization和Synchronized Normalization五种方法各自的特点和区别
编程
三数之和


















 90
90

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











