






一般base Transformer的工作所使用的的都是Query-Key机制,区别在于在哪部分启动Query-Key或者何时启动Query-Key
这篇TrackFormer与昨天的TransTrack对比着看,会很有意思
架构图
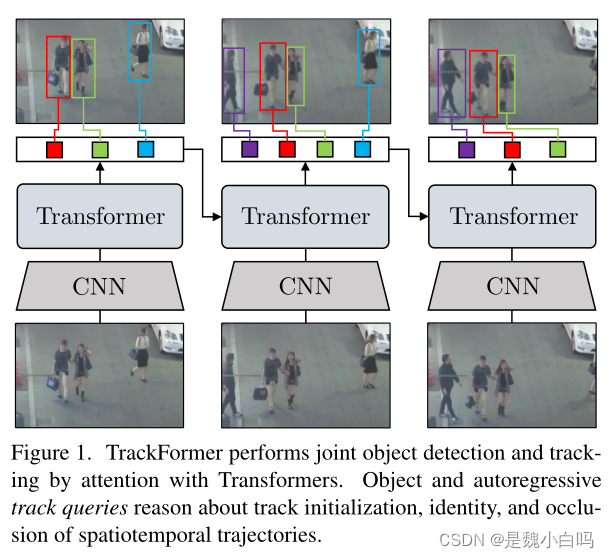
图1:TrackFormer通过与Transformer的注意力执行联合目标检测和跟踪。Object和自回归轨迹查询关于响应包括轨迹初始化、标识和时空轨迹遮挡。
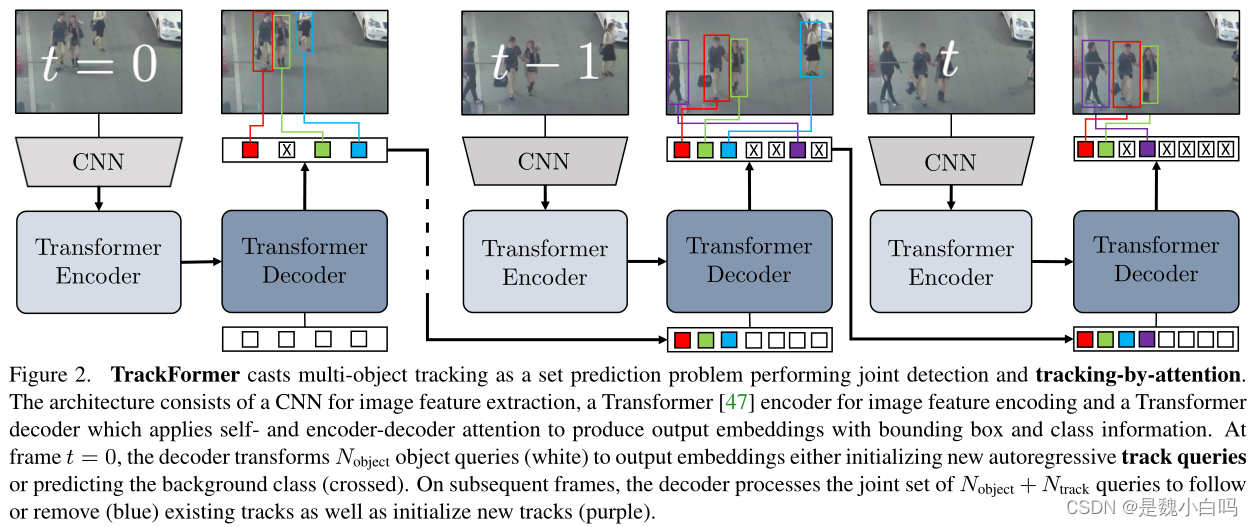
图2:TrackForm将多目标跟踪重新定义为set prediction问题,执行joint detection and tracking-by-attention。该体系结构由一个用于提取图像特征的CNN、一个用于图像特征编码的Transformer编码器和一个Transformer解码器组成,Transformer解码器利用self和encoder-decoder注意力来产生带有边界框和类别信息的输出嵌入。在frame t=0时,解码器将N object个对象查询(白色)转换为输出嵌入,用来初始化新的自回归轨迹查询(track query),或者预测背景类别(交叉, crossed)。在后续帧上,解码器处理N object+N track查询的联合集合以跟踪或移除(蓝色)现有轨道以及初始化新轨道(紫色)。
这里需要注意的是,不算head层,其实Transformer结构会将输入进行频繁的自注意力,但是输出获得内容信息的embedding维度是不变的,这里可以理解为一个黑盒,因此这里初始化的track query其实和后面每帧为了新目标检测使用的object query是同维的。
N object+N track的共同查询可以理解为:object query用于空间上查询,track query带有时序信息进行查询。当然这只是一种“企图优雅”的解释,事实上是一个黑盒模型。
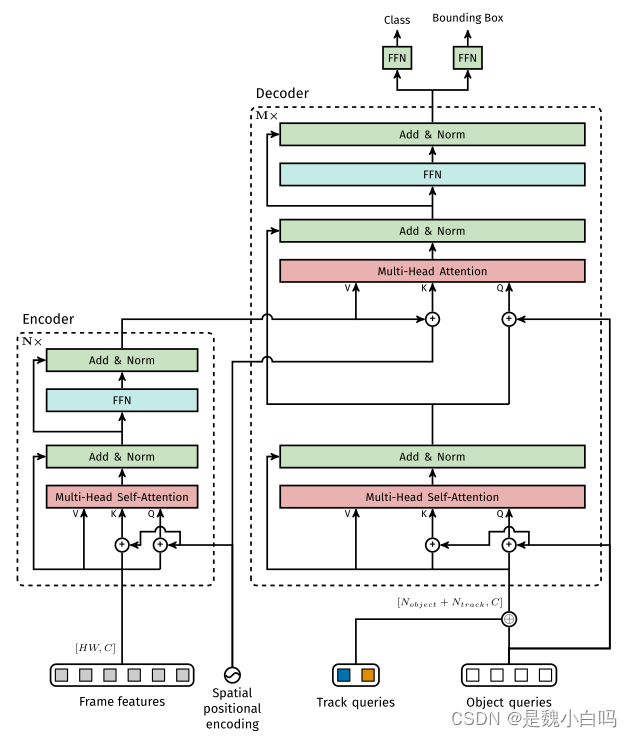
这是TrackFormer的结构图,可与TransTrack的结构图对比着来看。
主要区别在于TrackFormer在两帧这件检测联合的信息是Track queries,它由上一帧的Object queries生成。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











