






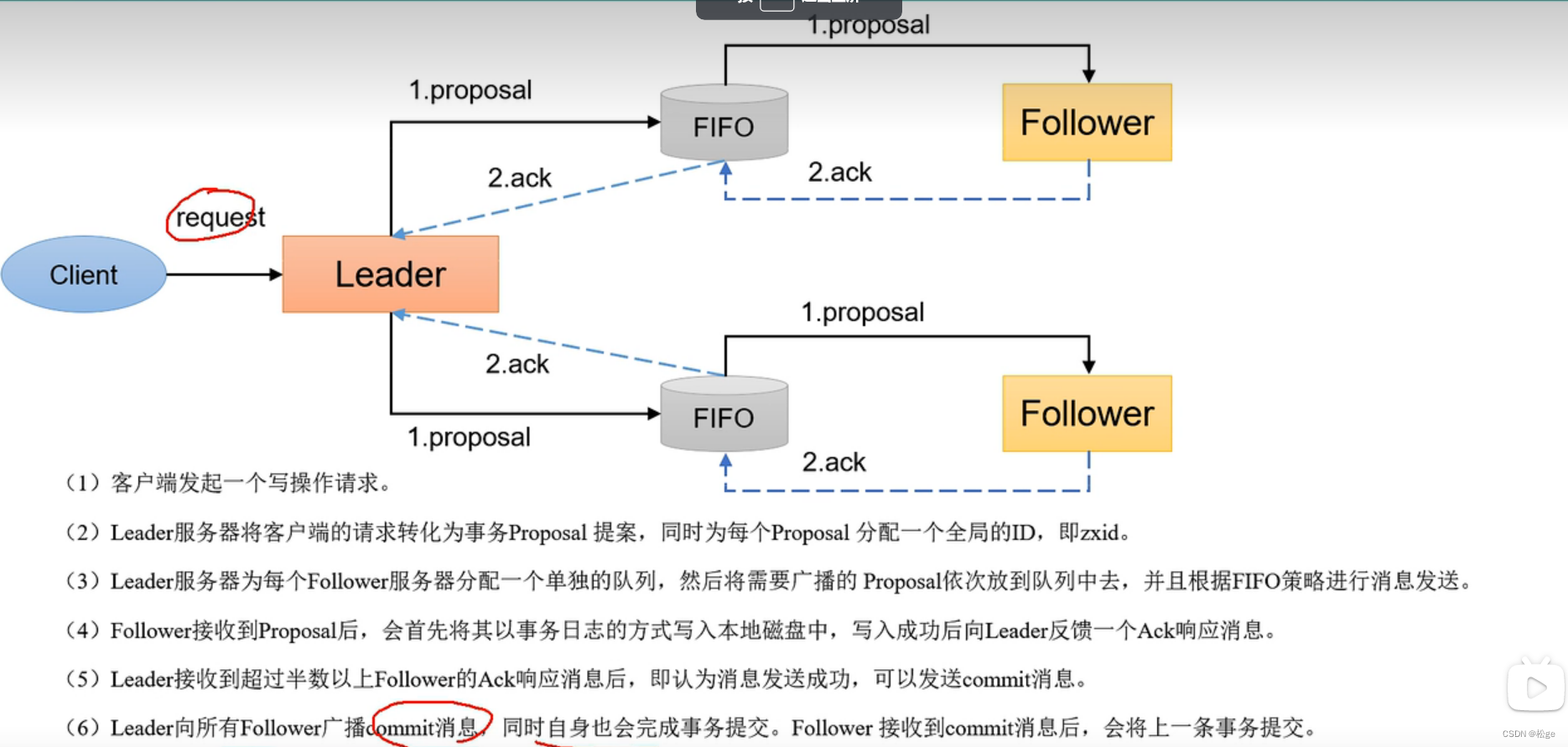
1.zk 集群之间的数据同步 数据一致性问题
还有新添加一台ZK服务器到集群中,也面临着数据一致性的问题,它需要去Leader中读取同步数据
zk是强一致性的:Zab协议(ZooKeeper Atomic Brocadcast)
保证在leader上提交的事务最终被所有的服务器提交
保证丢弃没有经过半数检验的事务
Zab协议的作用#
使用一个单独的进程,保持leader和Learner之间的socket通信,阅读源码这个Thread就是learnerHandler,任何写请求都将由Leader在集群中进行原子广播事务
保证了全部的变更序列在全局被顺序引用,写操作中都需要先check然后才能写,比如我们向create /a/b 它在创建b时,会先检查a存在否? 而且,事务性的request存在于队列中,先进先出,保证了他们之间的顺序
Zab协议原理#
选举: 在Follower中选举中一个Leader
发现: Leader中会维护一个Follower的列表并与之通信
同步: Leader会把自己的数据同步给Follower, 做到多副本存储,体现了CAP的A和P 高可用和分区容错
广播: Leader接受Follower的事务Proposal,然后将这个事务性的proposal广播给其他learner
Zab协议内容#
当整个集群启动过程中,或者当 Leader 服务器出现网络中弄断、崩溃退出或重启等异常时,Zab协议就会 进入崩溃恢复模式,选举产生新的Leader。
当选举产生了新的 Leader,同时集群中有过半的机器与该 Leader 服务器完成了状态同步(即数据同步)之后,Zab协议就会退出崩溃恢复模式,进入消息广播模式。
当Leader出现崩溃退出或者机器重启,亦或是集群中不存在超过半数的服务器与Leader保存正常通信,Zab就会再一次进入崩溃恢复,发起新一轮Leader选举并实现数据同步。同步完成后又会进入消息广播模式,接收事务请求
2.选举原理
Zab协议内容#
当整个集群启动过程中,或者当 Leader 服务器出现网络中弄断、崩溃退出或重启等异常时,Zab协议就会 进入崩溃恢复模式,选举产生新的Leader。
3.数据持久化
ZK 会持久化到磁盘的文件有两种:log 和 snapshot
log 负责记录每一个写请求
snapshot 负责对当前整个内存数据进行快照
恢复数据的时候,会先读取最新的 snapshot 文件
然后在根据 snapshot 最大的 zxid 去搜索符合条件的 log 文件,再通过逐条读取写请求来恢复剩余的数据
4.zookeeper的监听
Watcher(事件监听器)
是 ZooKeeper 中一个很重要的特性。ZooKeeper允许用户在指定节点上注册一些 Watcher,
并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去。该
机制是 ZooKeeper 实现分布式协调服务的重要特性。
https://www.bilibili.com/video/BV15F411u7vN?p=11&spm_id_from=pageDriver&vd_source=8d96659a8af5dade7b3cbe2a3ebb9ca8
5.zookeeper myid 作用
Zookeeper 中的 myid 文件是用于确定节点身份的配置文件。每个 Zookeeper 集群节点都有一个唯一的编号,这个编号就是 myid 文件中的数字。在启动 Zookeeper 节点时,该节点会读取 myid 文件,以确定该节点的编号。因此,如果您要在集群中添加新节点,则需要为该节点创建一个新的 myid 文件,并确保该文件中的数字在集群中是唯一的。
6.zookeeper是如何保证创建的节点是唯一的
zookeeper源码级保证原子性
zookeeper中创建节点是由DataTree的createNode方法来执行的
public String createNode(String path, byte data[], List<ACL> acl,long ephemeralOwner, int parentCVersion, long zxid, long time)
throws KeeperException.NoNodeException,
KeeperException.NodeExistsException {
int lastSlash = path.lastIndexOf('/');
String parentName = path.substring(0, lastSlash);
String childName = path.substring(lastSlash + 1);
StatPersisted stat = new StatPersisted();
stat.setCtime(time);
stat.setMtime(time);
stat.setCzxid(zxid);
stat.setMzxid(zxid);
stat.setPzxid(zxid);
stat.setVersion(0);
stat.setAversion(0);
stat.setEphemeralOwner(ephemeralOwner);
DataNode parent = nodes.get(parentName);
if (parent == null) {
throw new KeeperException.NoNodeException();
}
synchronized (parent) {
Set<String> children = parent.getChildren();
if (children != null) {
if (children.contains(childName)) {
throw new KeeperException.NodeExistsException();
}
}
if (parentCVersion == -1) {
parentCVersion = parent.stat.getCversion();
parentCVersion++;
}
parent.stat.setCversion(parentCVersion);
parent.stat.setPzxid(zxid);
Long longval = convertAcls(acl);
DataNode child = new DataNode(parent, data, longval, stat);
parent.addChild(childName);
nodes.put(path, child);
if (ephemeralOwner != 0) {
HashSet<String> list = ephemerals.get(ephemeralOwner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
}
// now check if its one of the zookeeper node child
if (parentName.startsWith(quotaZookeeper)) {
// now check if its the limit node
if (Quotas.limitNode.equals(childName)) {
// this is the limit node
// get the parent and add it to the trie
pTrie.addPath(parentName.substring(quotaZookeeper.length()));
}
if (Quotas.statNode.equals(childName)) {
updateQuotaForPath(parentName
.substring(quotaZookeeper.length()));
}
}
// also check to update the quotas for this node
String lastPrefix;
if((lastPrefix = getMaxPrefixWithQuota(path)) != null) {
// ok we have some match and need to update
updateCount(lastPrefix, 1);
updateBytes(lastPrefix, data == null ? 0 : data.length);
}
dataWatches.triggerWatch(path, Event.EventType.NodeCreated);
childWatches.triggerWatch(parentName.equals("") ? "/" : parentName,
Event.EventType.NodeChildrenChanged);
return path;
}
createNode方法会获取到所要创建的新节点的name和其父节点的parentName,并且会创建一个StatPersisted对象存储新节点的一些状态属性信息。随后从名为nodes的ConcurrentHashMap(用于存放所有的节点,key是path字符串,value是DataNode对象)中获取到父节点,然后用synchronized锁住父节点,避免其他请求出现并发问题。获取到父节点之后会将新节点的路径add到父节点的children的Set集合中,之后新节点就会被put到nodes的ConcurrentHashMap中。















 1566
1566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









