







问题一:对于左递归的语法,为什么我的推导不是左递归的?
这个问题本身反映了,进行递归下降分析的时候,如何保持清晰的思路,值得讲一讲。
在03 讲,我们刚开始接触到语法分析,也刚开始接触递归下降算法。这时,我介绍了左递归的概念,但你可能在实际推导的过程中,觉得不是左递归,比如用下面这个语法,来推导“2+3”这个简单的表达式:
//简化的左递归文法
add->Int
add->add + Int你可能会拿第一个产生式做推导:
add->2
成功返回
因为没有采用第二条产生式,所以不会触发递归调用。但这里的问题是,“2+3”是一个加法表达式,2 也是一个合法的加法表达式,但仅仅解析出 2 是不行的,我们必须完整地解析出“2+3”来。
在17 讲提到,任何自顶向下的算法,都是在一个大的图里找到一条搜索路径的过程。最后的结果,是经过多次推导,生成跟输入的 Token 串相同的结果,解析完毕以后,所有 Token 也耗光。
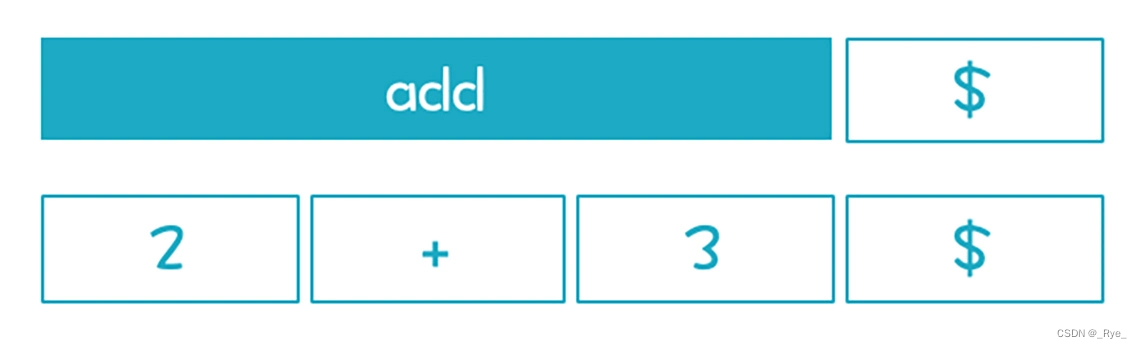
如果只匹配上 2,那就证明这条搜索路径是错误的,我们必须尝试另一种可能性,也就是第二个产生式。
要找到正确的搜索路径,在递归下降算法或者 LL 算法时,我们都是采用“贪婪”策略,这个策略在16 讲关于正则表达式时讲过。也就是要匹配尽量多的 Token 才可以。就算是换成右递归的文法,也不能采用第一个产生式。因为解析完 Int 以后,接下来的 Token 是 + 号,还可以尝试用第二个产生式,那我们就要启动贪婪策略,用第二个,而不是第一个。
//简化的右递归文法
add->Int
add->Int + add以上是第一种情况。
不过有的同学说:“我运用第二个产生式也能匹配成功,根据‘add->add + int’这个产生式,先拿第一个 add 去匹配 2,再去匹配 + 号和 3 不就行了吗?”
这是另一种引起困扰的情况,也是我在 17 讲必须说一下广度优先算法的一个原因。因为这位同学的推导过程,是典型的广度优先。add 非终结符,先广度优先地拆成两条路径:第一条路径匹配不成功;第二条路径进一步进行广度优先的探索,于是成功解析:

但我们在 17 讲也说过了,广度优先算法的性能很低,在这个简单的例子中还看不出来,但如果是稍微复杂一点儿的语法和表达式,计算量就指数级上升。
问题二:二元表达式的结合性的实现。
最终通过循环来消除递归带来的二元预算符的结合性问题?能否直接在递归中消除结合性问题?
04 讲的这个问题在递归下降算法中是个难点,反映了理论上的算法用于工程实践时,会遇到的具体问题和解决方案,所以也值得探讨。
因为递归下降算法是自顶向下、最左推导的。对于 AST 来说,父节点总是先于子节点来生成。因此,使用下面这个消除了左递归的加法文法来尝试解析“2+3+4+5”这个表达式:
add -> Int add'
add' -> + Int add' | ε得到的 AST 应该是这样的:
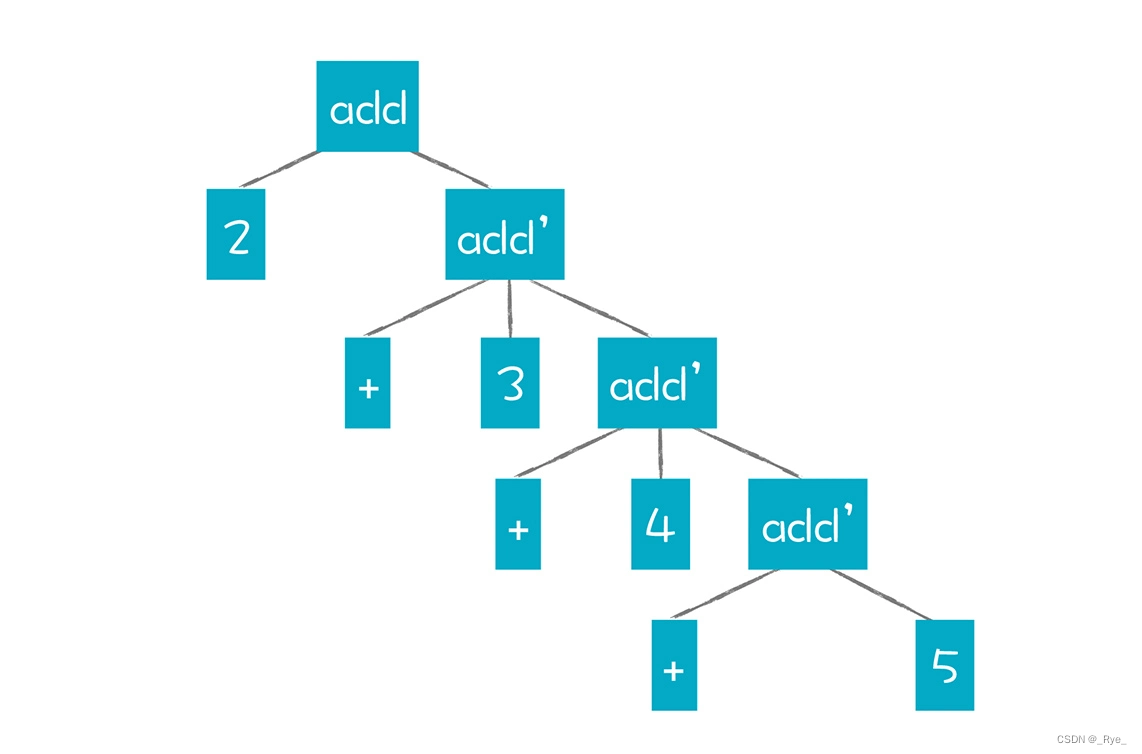
这个 AST 会觉得有点儿怪,毕竟它把加法操作分成了 add 和 add’这两种操作。针对 add’这样一个节点,我们可以定义为把 Int 子节点和 add’子节点做加法,但这样就一共要做四次计算,1 个 add 计算,3 个 add’计算。并且,因为是右递归,所以计算顺序是右结合的。
如果我们想改成左结合,可以尝试改变之前的约定,就是父节点先于子节点生成,把 AST 强行拧成这个样子:
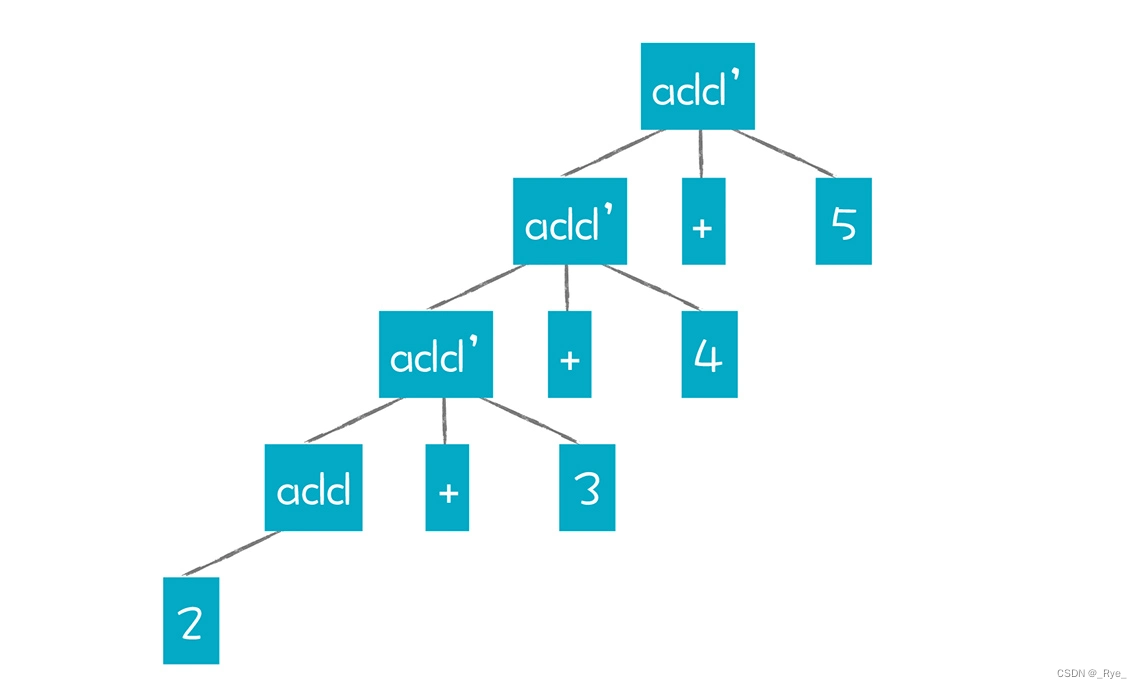
可以看出,这样强拧的过程,已经违背了 add 和 add’产生式的规则。
同时,用 add 和 add’这两个节点才能表达加法运算,还是跟我们日常的习惯相违背。与之相对的,Antlr 的写法,就很符合我们日常习惯。它是根据 这样的额外信息,决定解析时如何生成 AST 的结构:
add : Int
|<assoc=left> add + add
;我们文稿中的示例算法,跟这个思路类似,也是不改变加法运算的含义,但会根据结合性改变 AST 节点的父子结构。这种改变,等价于我们在解析加法表达式时,不是用的最左推导,而是最右推导。
所以,我们可以看出:
单纯的运用递归下降算法或 LL 算法,我们是无法支持左结合的,一定要做一些特殊的处理。而 LR 算法就不需要这些特殊处理,仅仅通过文法的设计,就能支持好结合性,这可能是很多人推崇 LR 算法的原因吧。
另一方面,工程上运用良好的语法解析方法,不需要是纯粹的某一种单一的算法,增加一些辅助手段会让它更有效。比如 Antlr 的内部实现可以自动选择预读 1 个或更多个 Token。必要的话还会启动回溯机制。这样做的好处,是对语法编写的要求降低,更加照顾程序员的工作效率。
问题三 :二义性文法为什么也能正常解析?
stmt -> if expr stmt
| if expr stmt else stmt
| other 我测试了一下,Antlr 使用上面这个规则可以正确地处理悬挂 else 的问题, Antlr 在处理这种二义性问题的时候,是依据什么来处理的?
针对07 讲中关于二义性文法的问题也有普遍意义,其实原因我在 07 讲里已经说了。我们实现一个算法的时候,是有确定的顺序来匹配的,所以,即使是二义性文法,在某种算法下也可以正常解析,也就是生成正确的 AST。
如果我们采取深度优先的自顶向下的算法,在使用这两个产生式时:
stmt -> if expr stmt
stmt -> if expr stmt else stmt 我们就像问题一中讲加法运算时提到的那样,采用“贪婪”的算法,总是试图匹配更多的 Token。所以,只要有 else,它就会去匹配 else,所以 else 总是会跟最近的 if 组成一对。但采用这个文法的时候,如果不是用贪婪策略来解析,就可能会导致 if 和 else 错配。
而严格的非二义性文法要求得比较高,它要求是算法无关的,也就是无论采用哪种推导顺序,形成的 AST 是一样的。 这里的关键点,在于把“文法”和“算法”这两件事区分开,文法是二义的,用某个具体算法却不一定是二义的。
问题四:“语法”和“文法”有什么区别和联系?
请问语法和文法有什么区别和联系?
这是一个术语的问题,确实要理清楚,你也可能会有这种疑问。
文法(Grammar),是形式语言(Formal Language)的一个术语。所以也有 Formal Grammar 这样的说法。这里的文法是定义清晰的规则,比如,我们的词法规则、语法规则和属性规则,都是用形式文法来定义的。
我们的课程里讲解了正则文法 (Regular Grammar)、上下文无关文法 (Context-free Grammar) 等不同的文法规则,用来描述词法和语法。
语法分析中的语法(Syntax),主要是描述词是怎么组成句子的,一个语言的语法规则,通常指的是这个 Syntax。
问题是,Grammar 这个词,在中文很多应用场景中也叫做语法。这是会引起混淆的地方。我们在使用的时候要小心一点儿就行了。
比如,我做了一个规则文件,里面都是一些词法规则(Lexer Grammar),我会说,这是一个词法规则文件,或者词法文法文件。这个时候,把它说成是一个语法规则文件,就有点儿含义模糊。因为这里面并没有语法规则(Syntax Grammar)。
案例总结
在前端部分,我们伴随着文稿提供了丰富的示例程序,我相信代码是程序员之间沟通的最好手段。
第一批示例程序,是 lab/craft 目录下的。
通过手工实现简单的词法分析和语法分析,获得第一手的感受,破除对于编译技术的神秘感。你会感觉到,如果要实现公式计算器甚至一个简单脚本,似乎也没那么难。
第二批示例程序,是基于 Antlr 工具的。
使用这个工具,实现了两个目的:
第一,让你借鉴成熟的规则文件,高效实现词法分析和语法分析功能。
第二,在不必关注词法分析和语法分析的情况下,我们把更多的精力放在了语言特性设计、语义分析和运行期机制上。针对作用域、函数、闭包、面向对象等特性都提供了示例程序,最终实现出一门看上去挺威风的脚本语言。
第三批示例程序,则是完成了应用篇的两个题目。
一个示范了如何通过解析 SQL 语句,实现分布式数据库的一个简单特性。另一个演示了如何来实现一个报表系统。通过两个实际案例将技术跟应用领域做了很好的连接,启发你按照类似的思路,去解决自己领域的问题。
第四批示例程序,是在算法篇,针对编译器前端的三组核心算法提供了示例。
这些示例程序能够根据文法规则直接做词法分析和语法分析,不需要为每一组规则单独构造词法分析器和语法分析器,实际上相当于简化版本的 Lex(词法分析)、Antlr(LL 语法分析)和 YACC(LR 语法分析)。
我给你的学习设计了多次迭代、循环提升认知的路径,从简单原理、现有工具和最佳实践、领域应用、算法逻辑等多个维度,给你全面的感受。
小结
编译原理的前端技术部分,正式告一个段落。在这个过程中,强调地是建立直觉,掌握关键知识点,以及跟实践结合,这三个方面是关键。在短短的十多节课中,我们已经覆盖了所有关键的知识点,吃透这部分课程,会对你的实际工作有所裨益。
当然,你肯定不可能完全把它完全吃透,不过,你已经在自己的知识体系中种下了一颗高质量种子,它会随着时间的流逝,伴随着你在实际应用中的体会,不断成长,并结出丰硕的果实!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









