






Rest
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
也是PUT,POST,DELETE,GET这些操作。
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | IP:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | IP:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | IP:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | IP:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | IP:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | IP:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
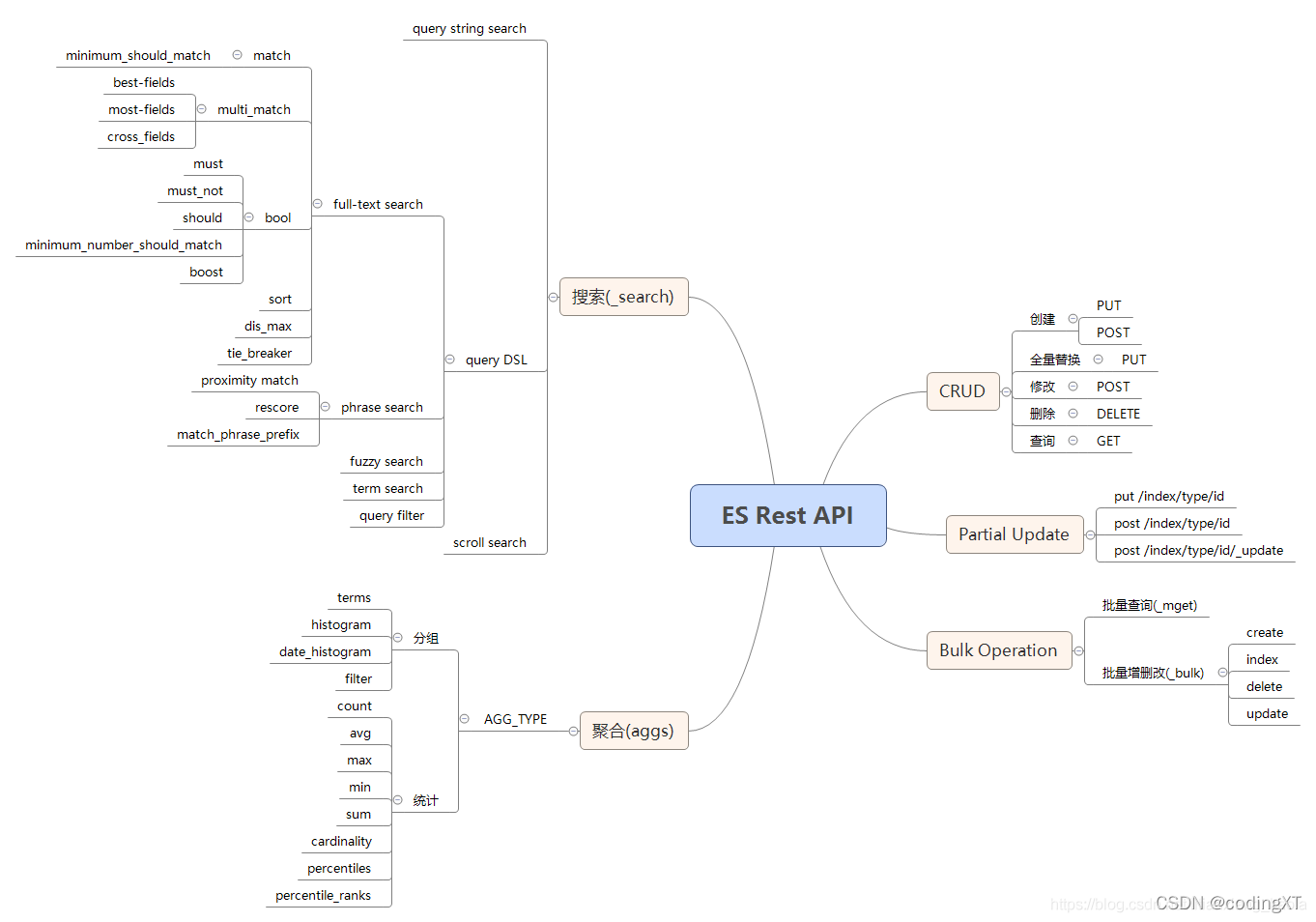
ES Rest API 思维导图
集群API
关于集群的一些Rest API
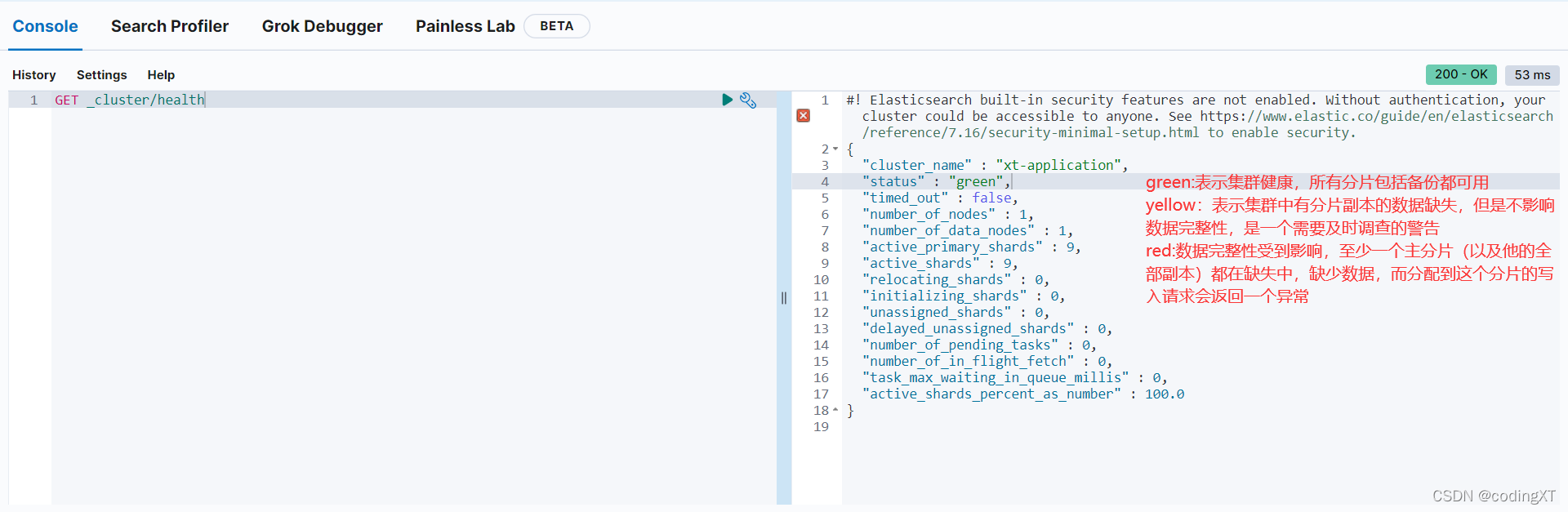
# 查询集群健康状态
GET _cluster/health
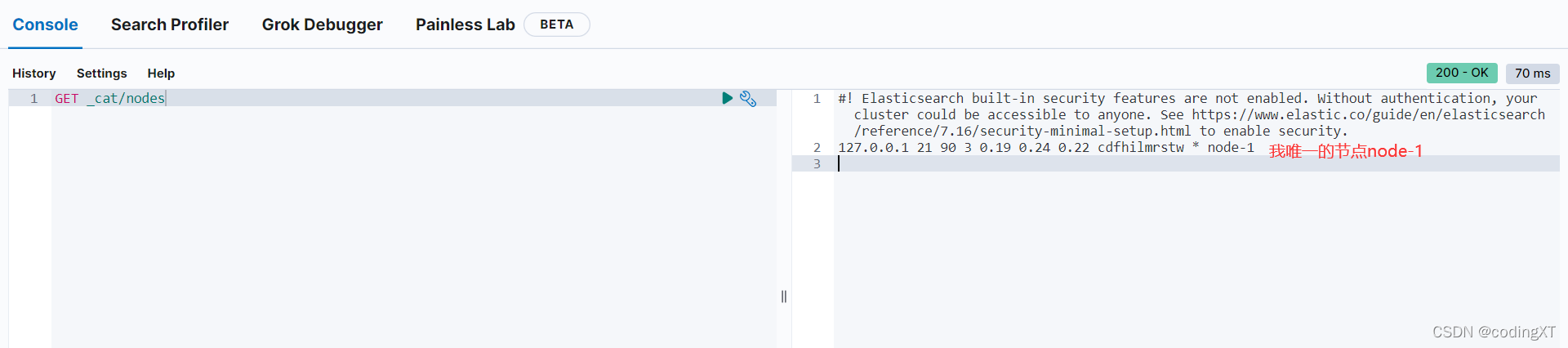
# 查询所有节点
GET _cat/nodes
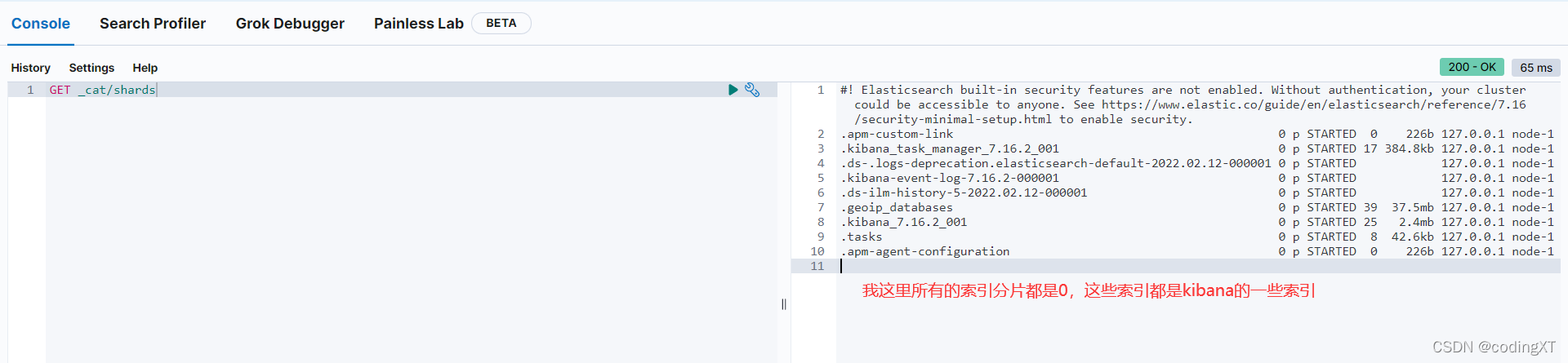
# 查询索引及分片的分布
GET _cat/shards
因为我没有创建索引,这些索引应该都是elasticsearch内部和kibana的一些索引
# 查询指定索引分片的分布 后面跟着索引名称就行
GET _cat/shards/.kibana_7.16.2_001
# 查询所有插件
GET _cat/plugins

索引相关信息查询
不一个一个试了
# 查询所有索引及容量
GET _cat/indices
# 查询索引映射结构
GET my_index/_mapping
# 查询所有索引映射结构
GET _all
# 查询所有的相同前缀索引
GET my-*/_search
# 查询所有索引模板
GET _template
# 查询具体索引模板
GET _template/my_template
创建索引以及文档
也可以使用POST ,POST 命令新增数据时, 如果不传id, 则系统自动生成一个UUID,类似于数据库的主键,是数据的唯一标识
//依次为索引,类型,文档
PUT /testxt/typext/1
{
"name" : "xt",
"age" : 24
}
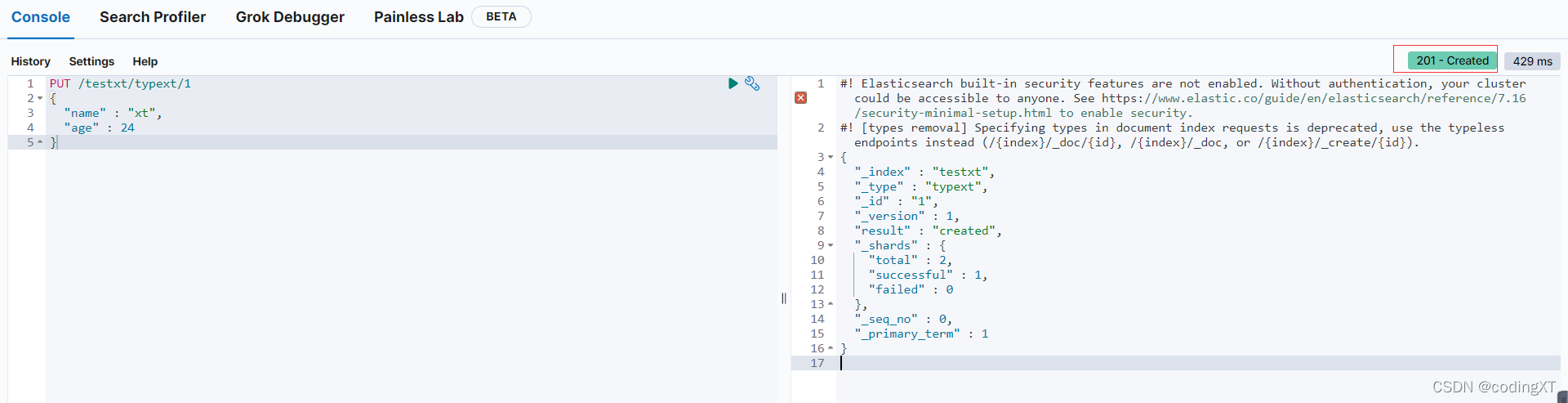
使用 ElasticSearch Head 插件也可以查看
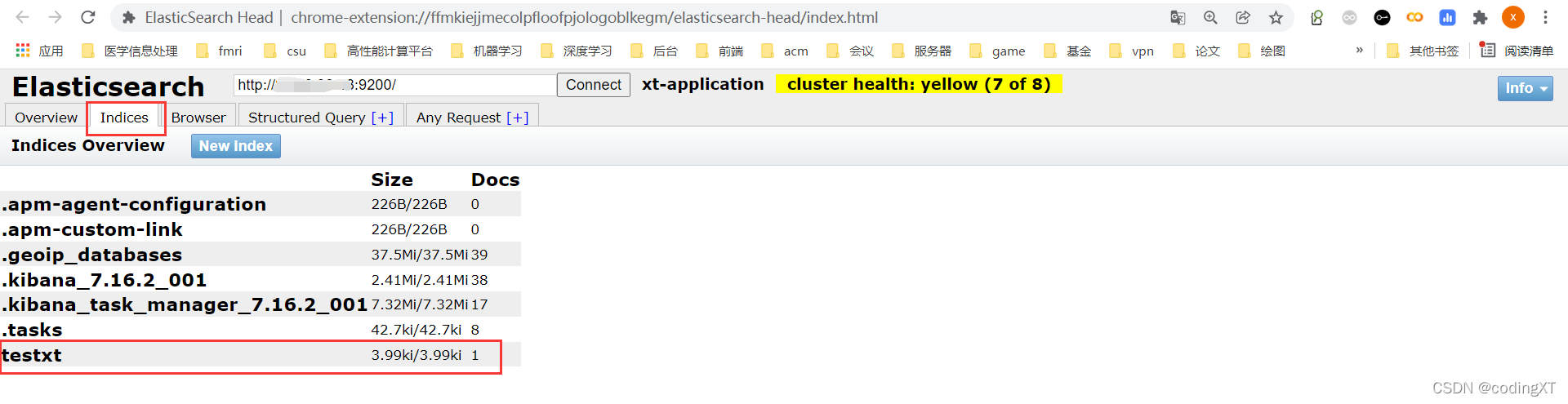
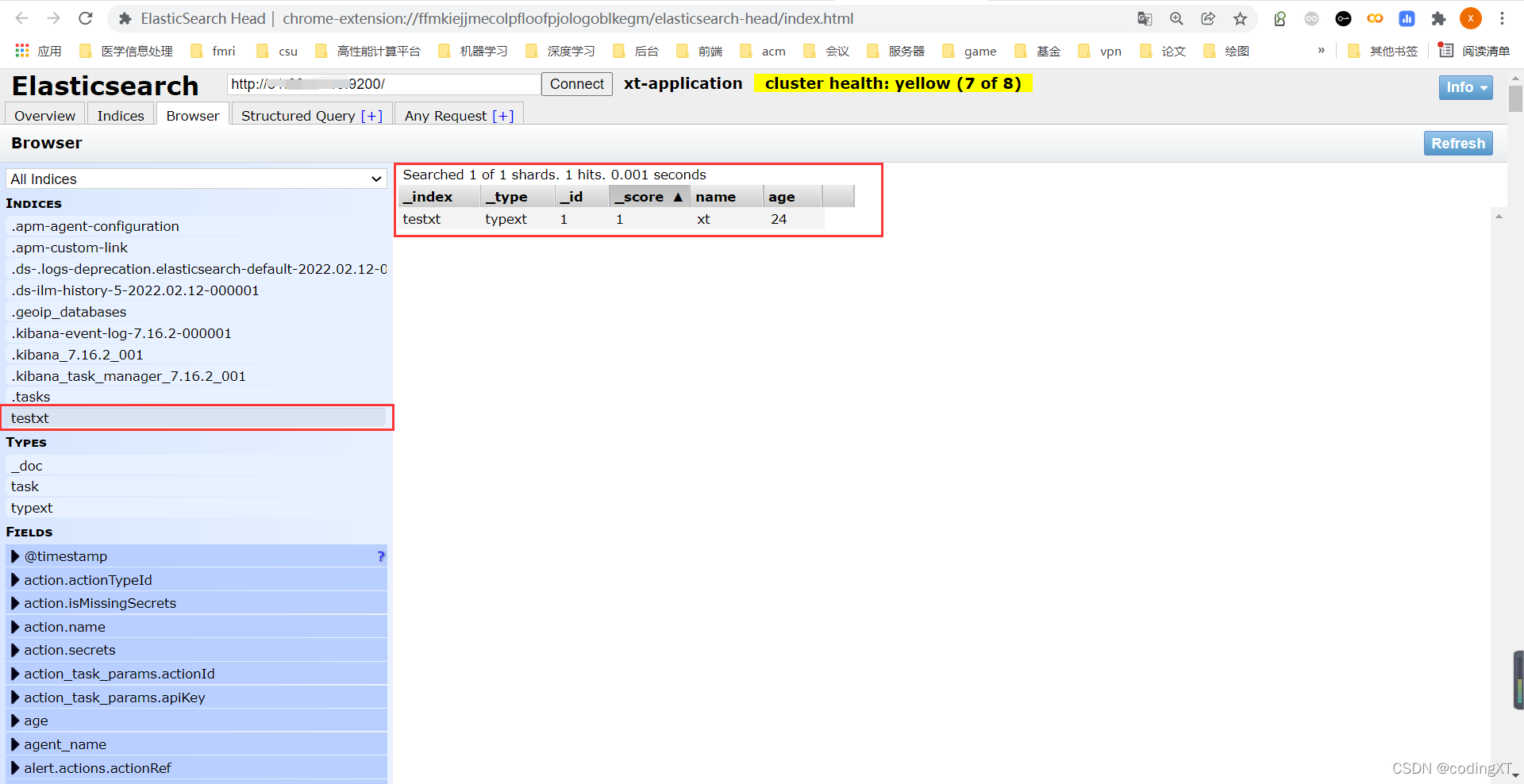
按指定字段类型创建索引
mappings 就是创建规则,指定那个属性是什么类型的字段,就和数据库一样
PUT /testxt2
{
"mappings": {
"properties": {
"name": {
"type": "text"
"index": true //可以被索引,false 为不能被索引,默认为true
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
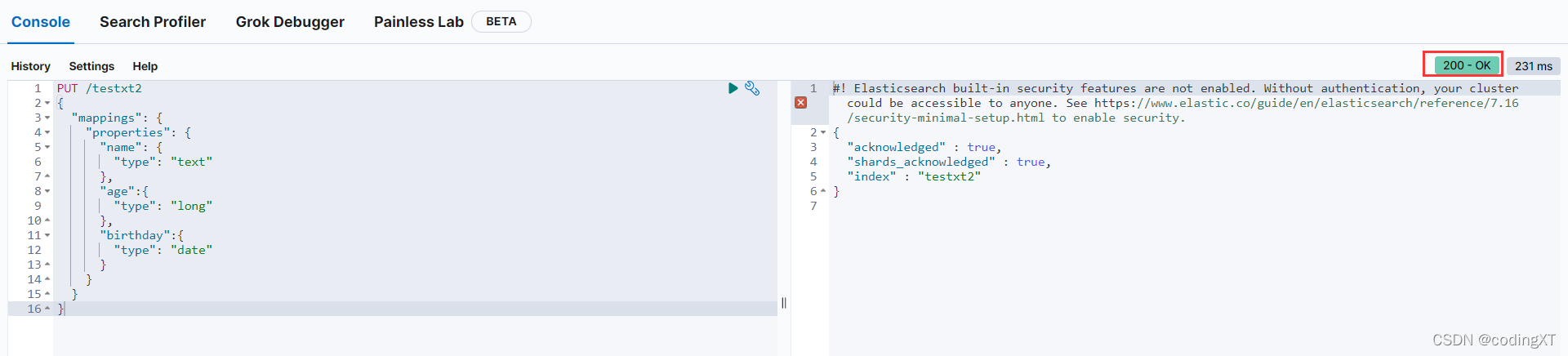
获取索引的详细信息
GET testxt2
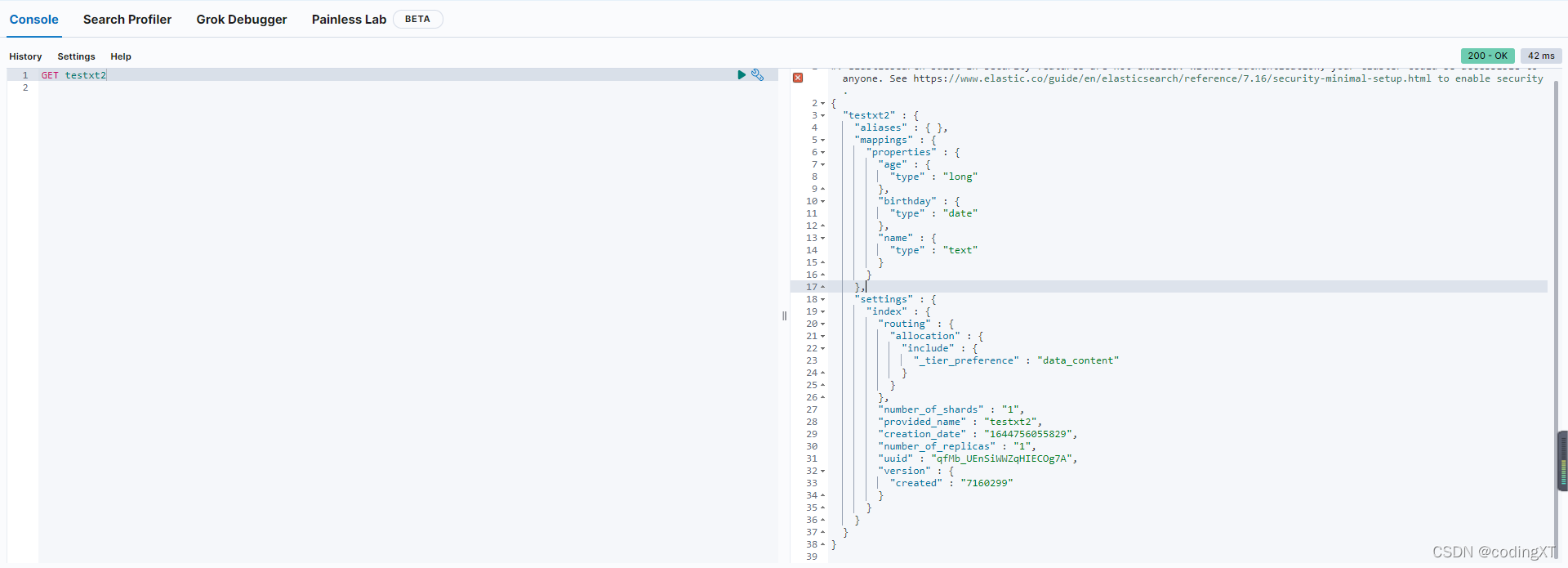
如果我们的索引没有像上面一样创建规则mappings,ElasticSearch 也会自动帮助我们匹配合适的类型。
_doc 默认类型(default type),type 在未来的版本中会逐渐弃用,因此产生一个默认类型进行代替。如下图所示
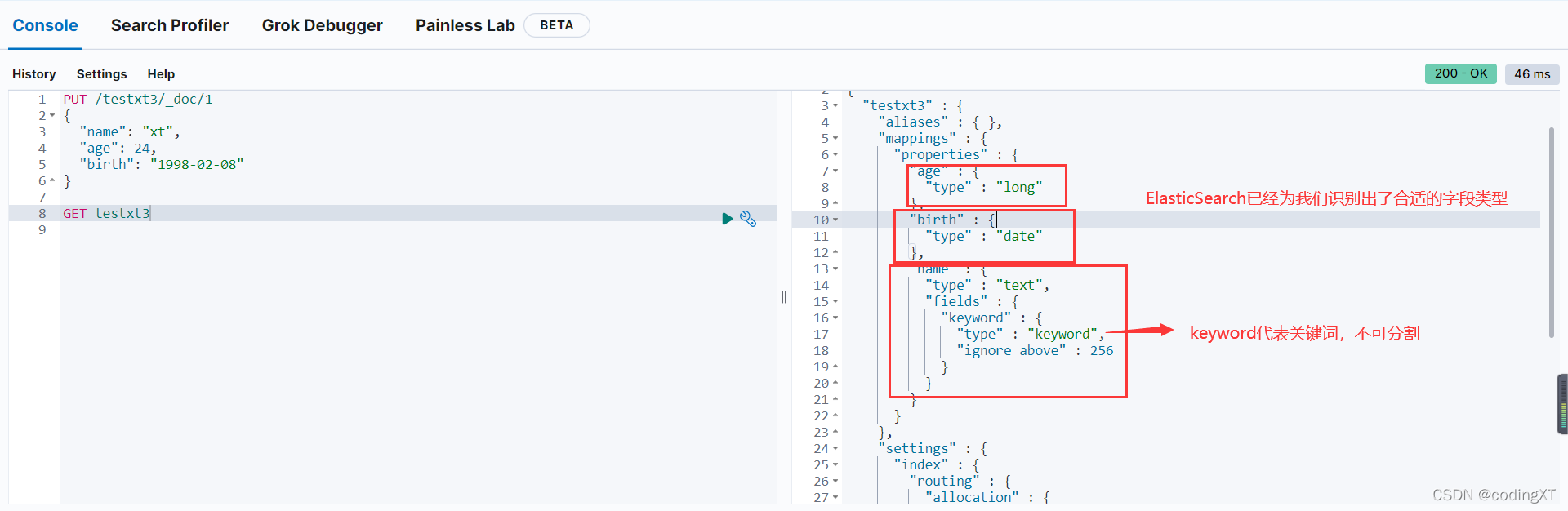
我们这里显示创建指定_doc
PUT /testxt3/_doc/1
{
"name": "xt",
"age": 24,
"birth": "1998-02-08"
}
GET testxt3
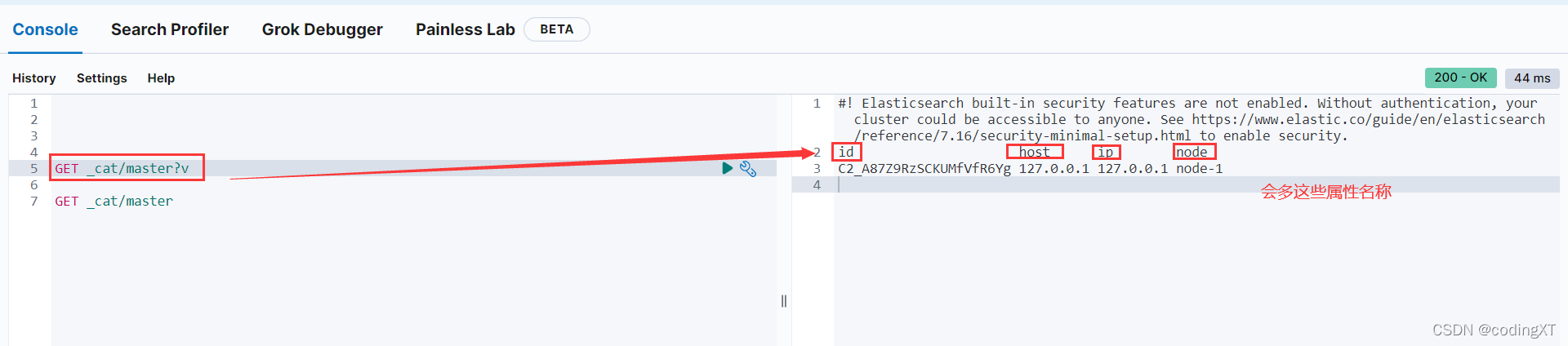
通过get _cat/ 可以获取ElasticSearch的当前的很多信息!
GET _cat/indices
GET _cat/aliases
GET _cat/allocation
GET _cat/count
GET _cat/fielddata
GET _cat/health
GET _cat/indices
GET _cat/master
GET _cat/nodeattrs
GET _cat/nodes
GET _cat/pending_tasks
GET _cat/plugins
GET _cat/recovery
GET _cat/repositories
GET _cat/segments
GET _cat/shards
GET _cat/snapshots
GET _cat/tasks
GET _cat/templates
GET _cat/thread_pool
后面加个?v可以显示每个属性的名称
修改文档数据
PUT修改(全局覆盖)
会覆盖原来的值
- 版本+1(_version)
- 但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失
//版本号会增加,无论数据有没有变动,版本号都会加一,因为是覆盖
PUT /testxt3/_doc/1
{
"name" : "I am xt",
"age" : 23,
"birth" : "2000-07-26"
}
GET /testxt3/_doc/1
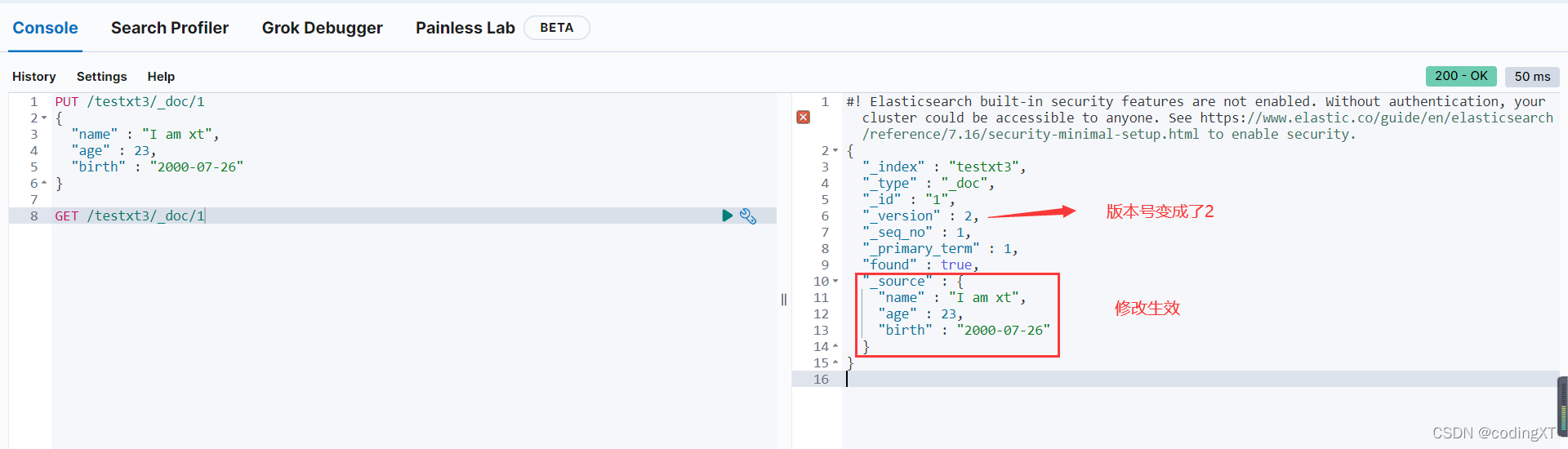
// 修改会有字段丢失
PUT /testxt3/_doc/1
{
"name" : "xt",
"age" : 24
}
GET /testxt3/_doc/1
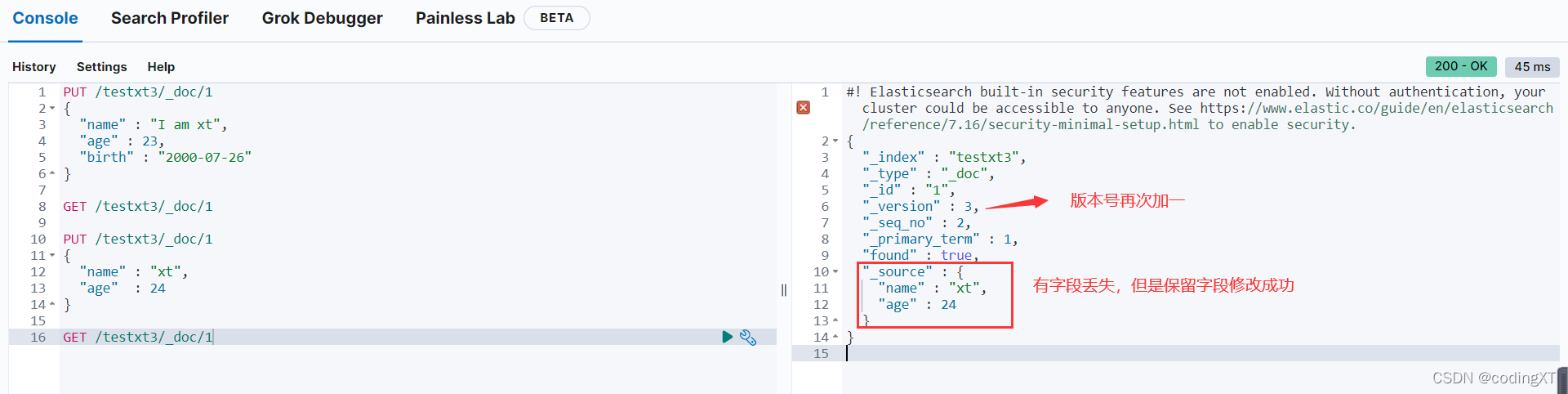
POST修改(局部更新)
- 不会丢失字段
- 如果数据一致,多次请求,版本号不会增加,与PUT覆盖不同
POST /testxt3/_doc/1/_update
{
"doc":{
"name" : "post修改,version不会加一",
"age" : 100
}
}
GET /testxt3/_doc/1
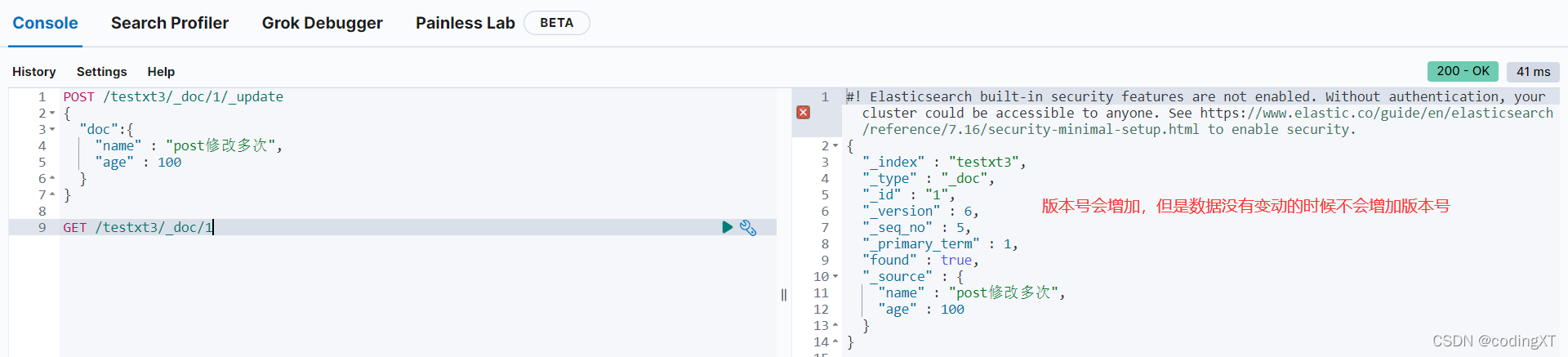
删除索引
只是逻辑删除, 将其标记为delete, 当数据越来越多时, ES会自动物理删除.
GET /testxt
DELETE /testxt
GET /testxt
查询数据
GET /testxt3/_doc/_search?q=name:xt
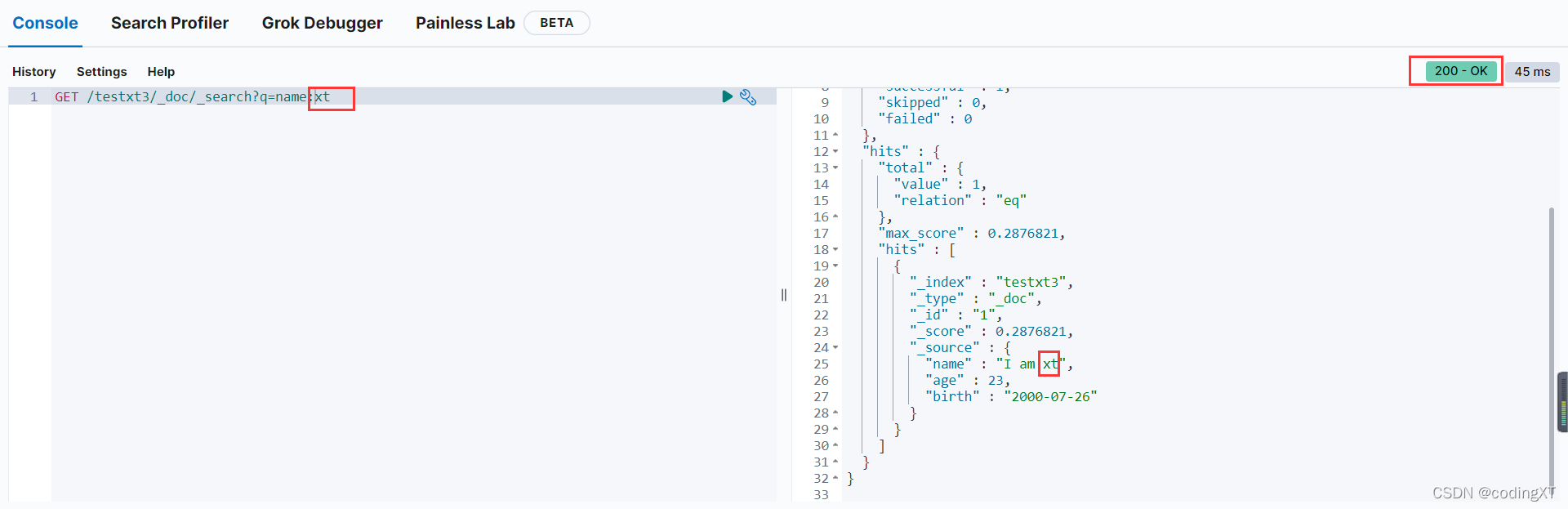
查询工具使用
也可以使用多种工具
- match:匹配(会使用分词器解析(先分析文档,然后进行模糊查询))
- _source:过滤字段(只保留这部分字段)
- sort:排序(来控制查询结果的展示)
- from、size 来控制分页
// 查询匹配
GET /index/type/_search
{
"query":{
"match":{ //match_phrase 不会拆分的模糊查询,会将xt当成一整个词
"name":"xt" // 查找name 为xt的数据 可以写多个,用空格分割开,表示多个条件,类似于or表达式
}
}
,
"_source": ["name","desc"] //保留这些字段
,
"sort": [
{
"age": {
"order": "asc" //将查询到的结果按照升序排列
}
}
]
,
"from": 0 //从第一条查询到的数据开始分页
,
"size": 2 //每一页设置有多少条数据
}
多条件查询
(bool里面加入多种限制条件)
- must 相当于 and
- should 相当于 or
- must_not 相当于 not (… and …)
- filter 数据过滤
利用filter过滤来对指定字段进行一个range范围控制的时候要用到的
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
GET /index/type/_search
{
"query":{
"bool": {
"must": [
{
"match":{
"age":24
}
}, // 匹配年级为24同时姓名为xt的
{
"match": {
"name": "xt"
}
}
],
"filter": {
"range": {
"age": { //对age 字段做一个范围控制
"gte": 1,
"lte": 100
}
}
}
}
}
}
插入多条数据做测试使用
PUT /testxt3/_doc/2
{
"name" : "elasticsearch",
"age" : 67,
"desc" : "I am elasticsearch"
}
PUT /testxt3/_doc/3
{
"name" : "kafka",
"age" : -3,
"desc" : "I am kafka"
}
GET /testxt3/_doc/_search
{
"query":{
"bool": {
"must": [
{
"match":{
"age":67
}
},
{
"match": {
"name": "elasticsearch"
}
}
],
"filter": {
"range": {
"age": {
"gte": 1,
"lte": 100
}
}
}
}
}
}
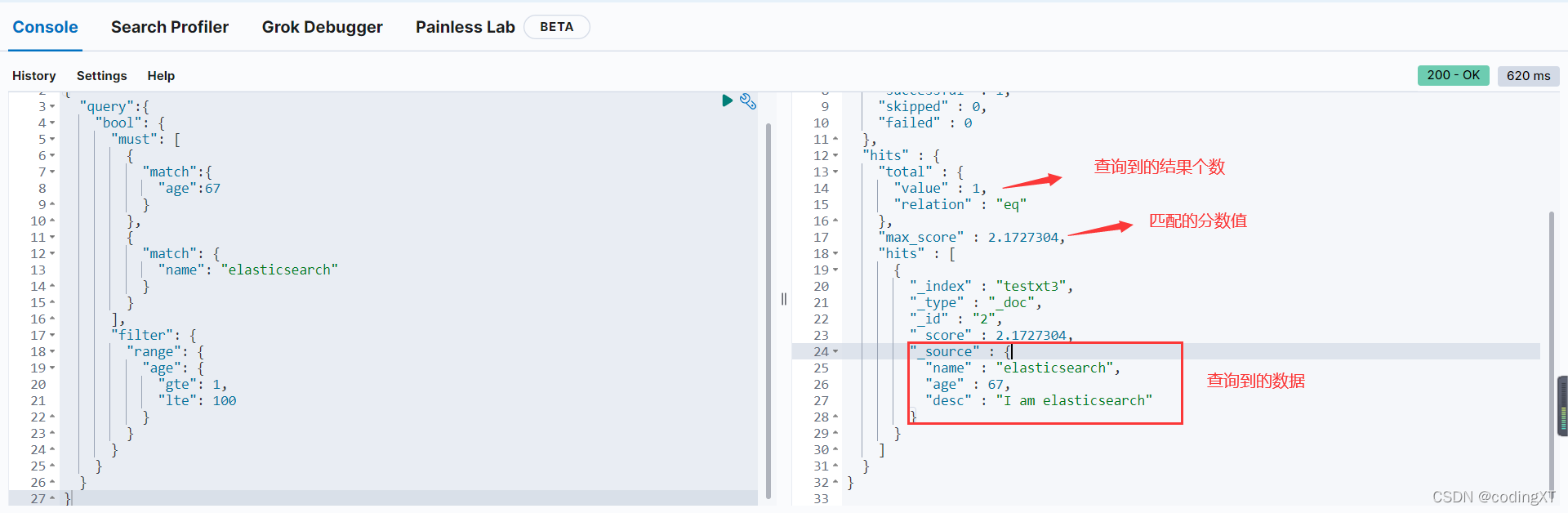
其他情况大家自行尝试
精确查询
term 直接通过 倒排索引 指定词条查询,精确查询,而上面的match会预先使用分词器解析,然后再查询,所以前一种速度要更快
适合查询 number、date、keyword ,不适合text
// 精确查询(必须全部都有,而且不可分,即按一个完整的词查询)
// term 直接通过 倒排索引 指定的词条 进行精确查找的
GET /testxt3/_doc/_search
{
"query":{
"term":{
"name":" xt" //会连着前面的空格一起查询,当成一个词,所以查不到
}
}
}
text和keyword
text:
支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作; text类型的最大支持的字符长度无限制,适合大字段存储;
keyword:
不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
// 测试keyword和text是否支持分词
// 设置索引类型
PUT /test
{
"mappings": {
"properties": {
"text":{
"type":"text"
},
"keyword":{
"type":"keyword"
}
}
}
}
// 设置字段数据
PUT /test/_doc/1
{
"text":"测试keyword和text是否支持分词",
"keyword":"测试keyword和text是否支持分词"
}
// text 支持分词
// keyword 不支持分词
GET /test/_doc/_search
{
"query":{
"match":{
"text":"测试"
}
}
}// 查的到
GET /test/_doc/_search
{
"query":{
"match":{
"keyword":"测试"
}
}
}// 查不到,必须是 "测试keyword和text是否支持分词" 才能查到
GET _analyze
{
"analyzer": "keyword",
"text": ["测试liu"]
}// 不会分词,即 测试liu
GET _analyze
{
"analyzer": "standard",
"text": ["测试liu"]
}// 分为 测 试 liu
GET _analyze
{
"analyzer":"ik_max_word",
"text": ["测试liu"]
}// 分为 测试 liu
高亮查询
百度搜索会对关键词进行高亮显示
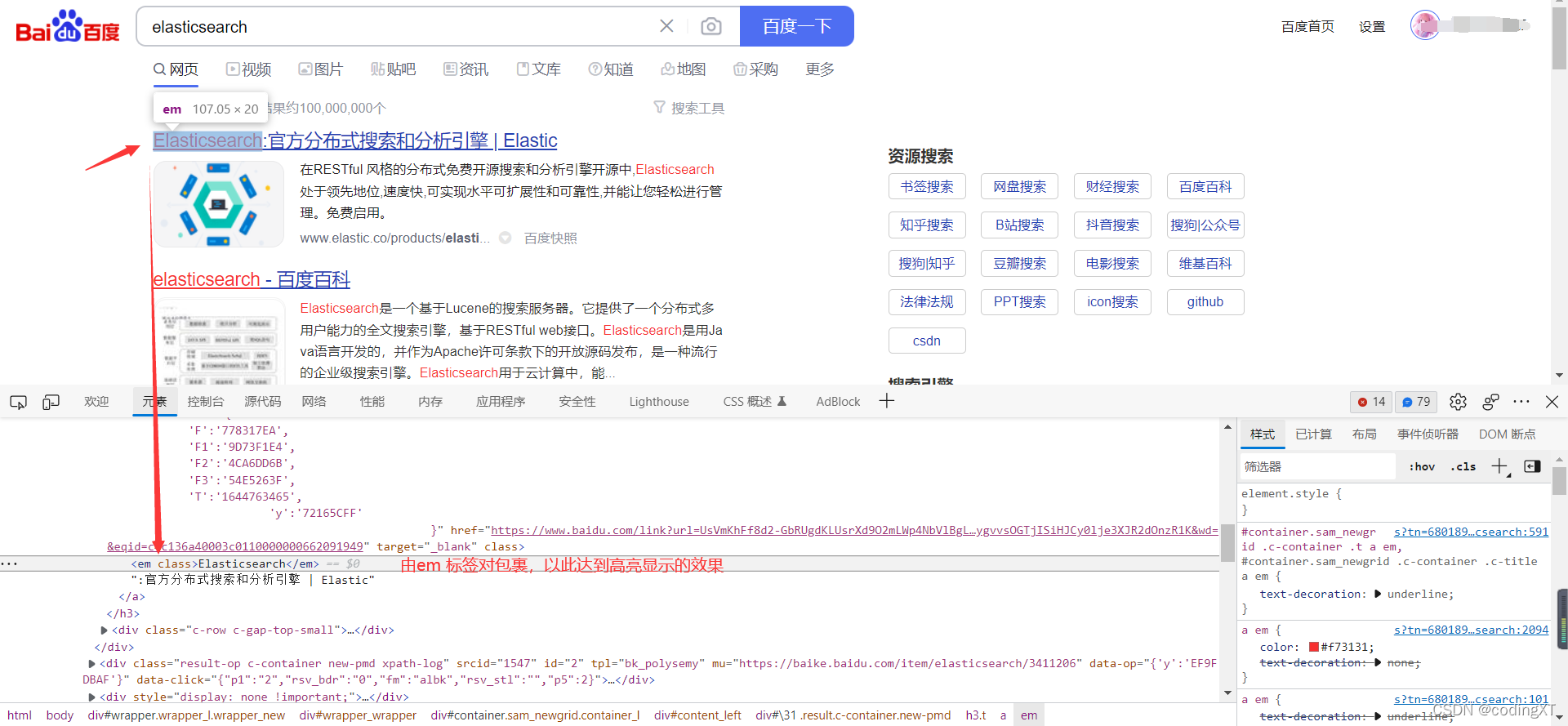
查看页面代码可以看见,关键词被em 标签对包裹
/// 高亮查询
GET testxt3/_doc/_search
{
"query": {
"match": {
"name":"xt"
}
}
,
"highlight": {
"fields": {
"name": {}
}
}
}
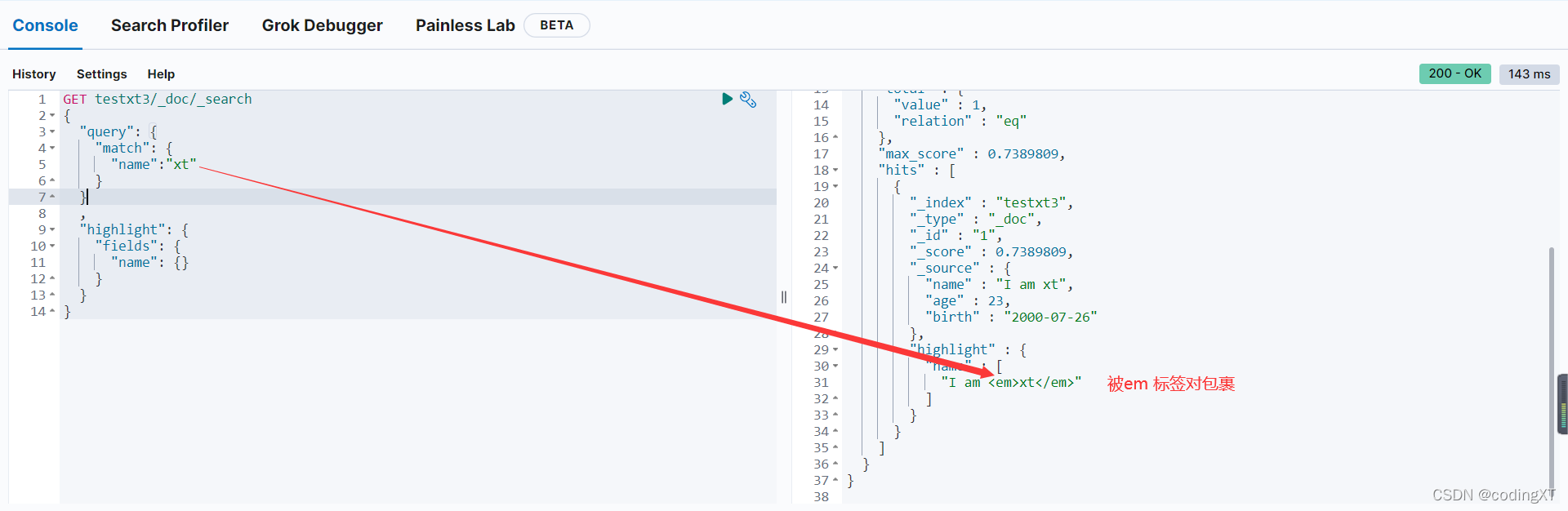
通过修改前缀和后缀也可以自定义高亮样式
// 自定义前缀和后缀
GET testxt3/_doc/_search
{
"query": {
"match": {
"name":"xt"
}
}
,
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
聚合查询
对查询的结果进行统计分析
聚合允许使用者对 ES 文档进行统计分析,类似于关系型数据库中的 group by,最大值max、平均值avg等等。
{
"aggs":{//聚合操作
"price_group":{//名称,随意起名
"terms":{//分组 avg 平均值 max 最大值
"field":"age"//分组字段
}
}
},
"size":0 //查询到的结果不携带原始数据,只返回聚合统计分析的结果
}
References:
- https://blog.csdn.net/litianxiang_kaola/article/details/102936324
- https://www.kuangstudy.com/bbs/1354069127022583809
(写博客主要是对自己学习的归纳整理,资料大部分来源于书籍、网络资料、官方文档和自己的实践,整理的不足和错误之处,请大家评论区批评指正。同时感谢广大博主和广大作者辛苦整理出来的资源和分享的知识。)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









