







李宏毅2021春机器学习笔记
4.Gradient Descent

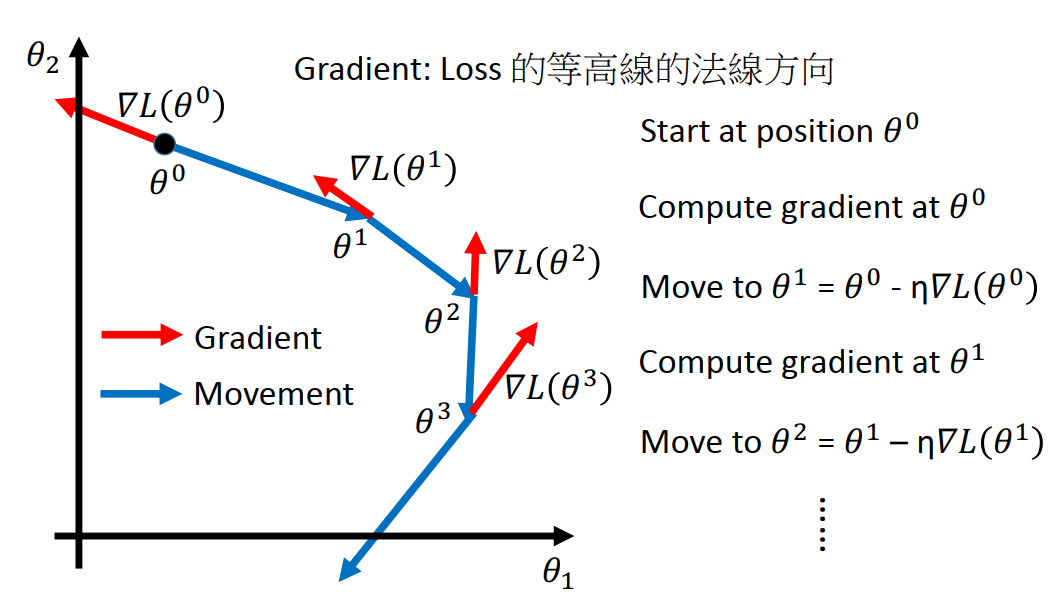
Tip 1:Tuning your learning rates
大原则:通常Learning rate是随着参数的update 会越来越小的。
给不同的参数不同的learning rate。
这件事情,是有很多小技巧的,其中最容易实做的叫 Adagrad。
Adagrad



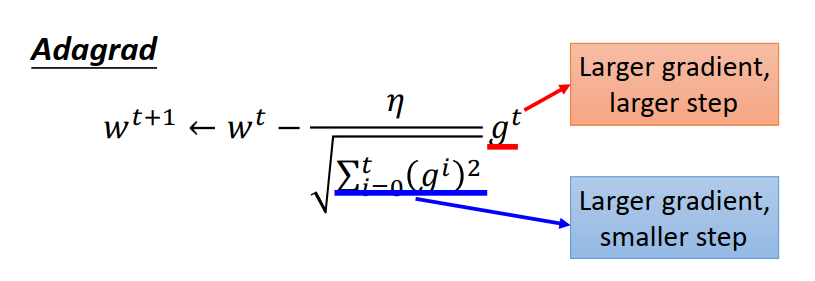
一个大 一个小,是不发生冲突的,因为Adagrad 主要想体现的是“反差”

gradient 的值越大就跟最低点的距离越远,这件事情在有好多个参数的时候,是不一定成立的(没有考虑跨参数的时候,gradient 的值和最低点的距离 是成正比的)。
跨参数:比如 a 和 c
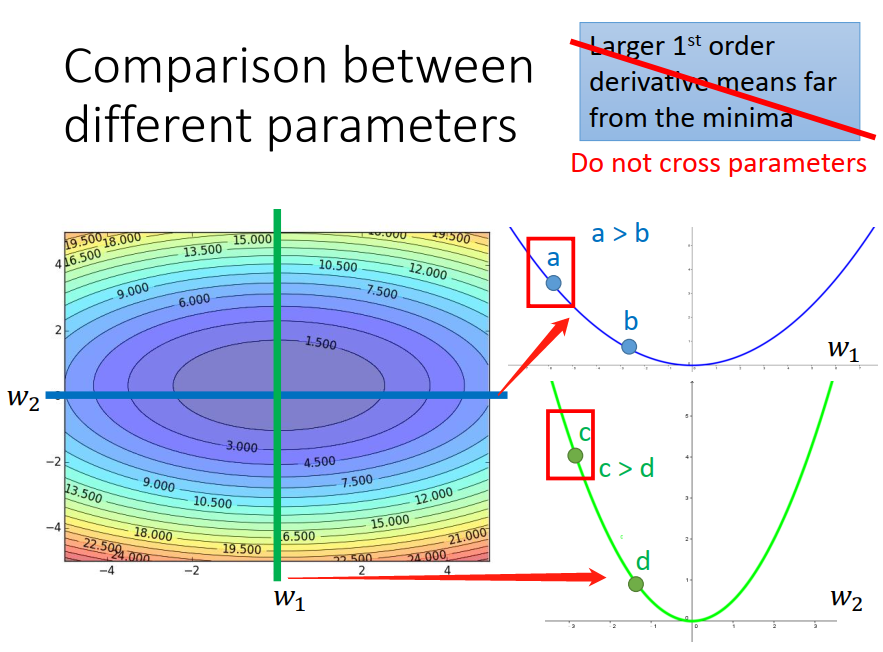
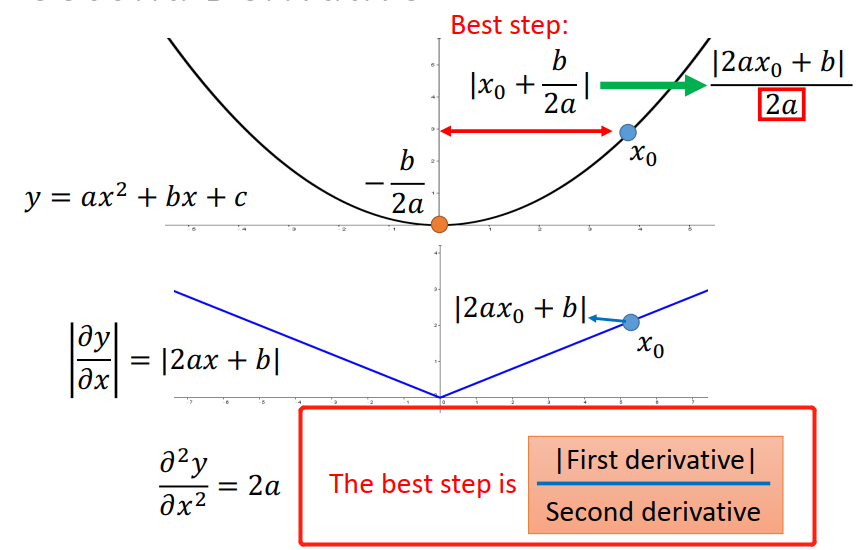
如果同时考虑好几个参数的话,最好的方法是同时除以各自的2次微分
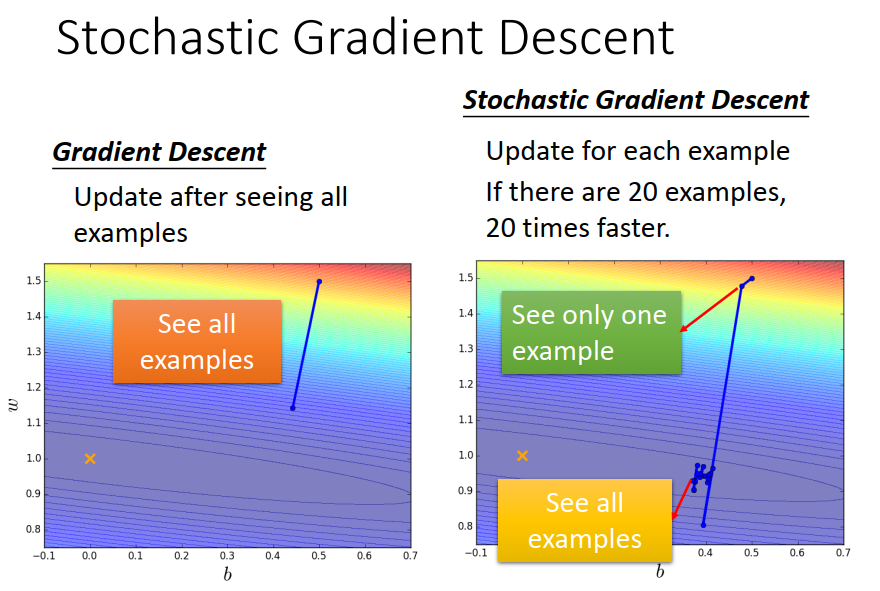
Tip 2:Stochastic Gradient Descent
随机梯度下降的目的:make the training faster
在原来的gradient descent 里面,你计算所有data的loss ,然后才update 参数。
但在 Stochastic Gradient Descent 里面 就是看见一个example 就update 一个参数。
好处:
Tip 3:Feature Scaling
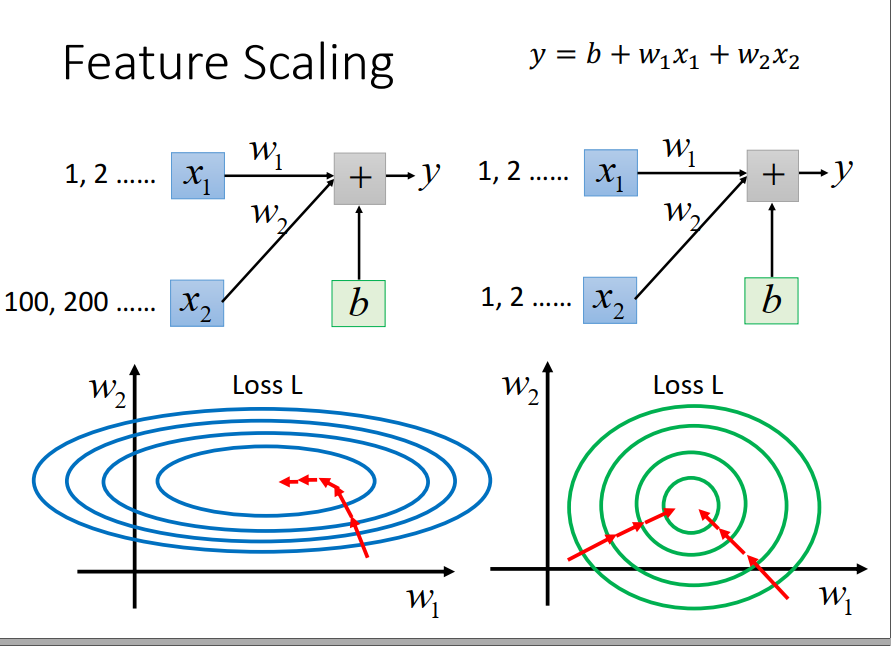
椭圆形的error surface 如果你不做些Adagrad什么的,你是很难搞定它的。
因为不同的方向上需要不同的learning rate,你要adaptive learning 才能搞定它。
如果你有scale 的话,他就变成一个正圆形,这时候 update 参数就会比较容易。
而且 ,gradient descent它并不是向着最低点走,是顺着等高线的方向,如果有 scale 的话(绿色),不管你在这个区域的哪个点,它都会向着圆心走。
所以,如果你有做feature scaling的时候,你再做参数的update的时候,是比较有效率的。
Feature scaling 常见做法:
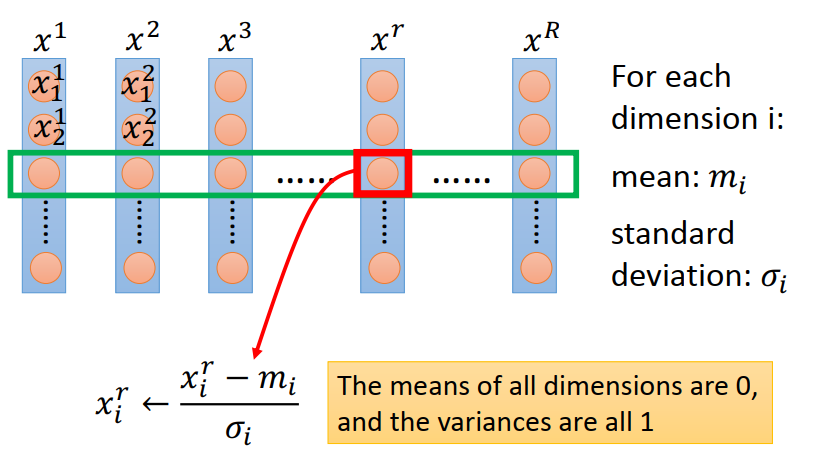
对每一个dimension i 都去算它的mean 记作m i ;都去算它的 deviation 记作 σ i,然后标准化
Gradient Descent Theory
本节主要介绍 Gradient Descent 背后的理论基础。
注意,update 参数后 ,loss 不一定会变小(可能learning rate 太大 跳出峡谷)
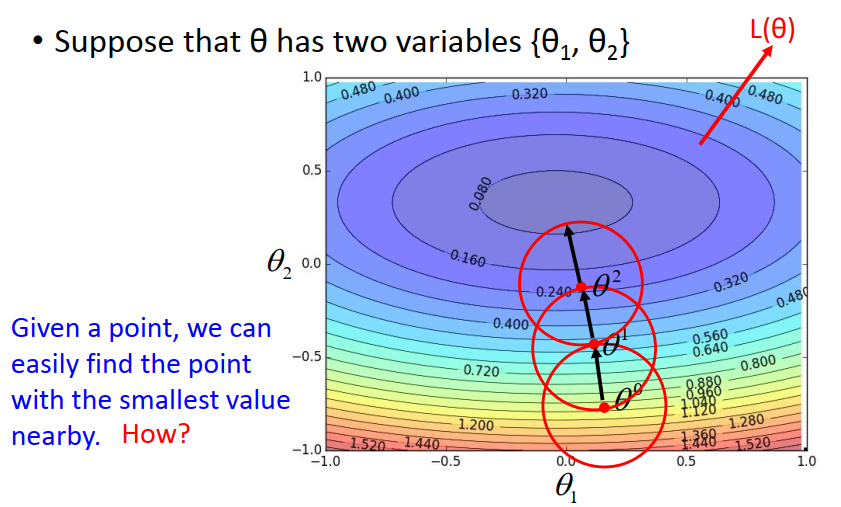
如果你给我一整个 error function ,我没用办法 马上一秒钟就告诉你说它的最低点在哪里。
但是如果你给我一个error function 加上一个初始的点,我可以告诉你说,在这个初始点附近,画一个范围之内,找到最小的值,然后更新我们的中心位置。不断的重复…
高能预警!!!
现在的问题是:怎么在红色的圈圈里面,找一个可以让loss最小的参数呢?
这个地方要从 Taylor Series说起


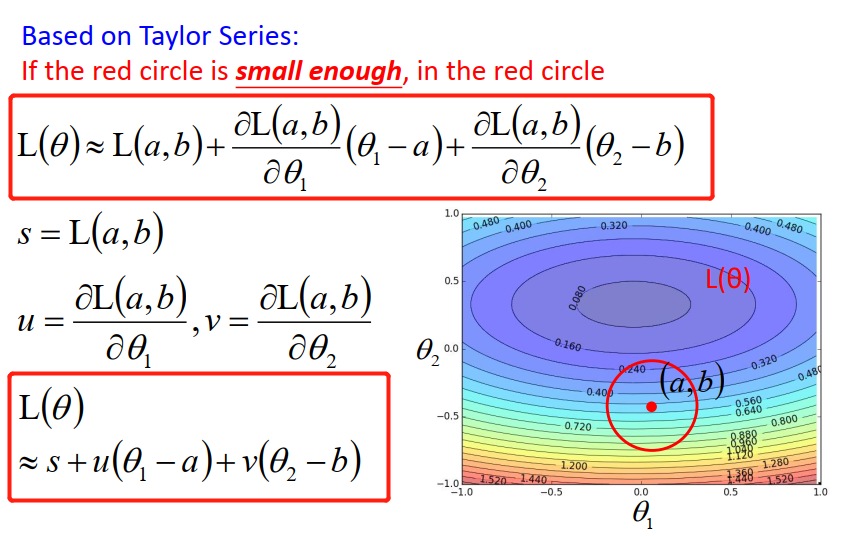
这样我们就可以秒算 θ1 θ2 ,取反方向的时候 loss最小。


当你今天画出的红色圈圈够小的时候,Taylor Series 给我们的approximation 才会够精确。
只有learning rate 无穷小的时候,loss 的这个式子才会成立。
所有在Gradient Descent,如果你每次update 参数的时候,理论上你的learning rate要无穷小,你才能够保证这件事情(虽然实作上,只要够小就行了)。如果你的learning rate 没有设好,是有可能说这个loss 式子是不成立的,所以导致你做Gradient Descent 的时候,你没有办法让loss越来越小。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











