







损失函数定义
损失函数:衡量模型输出与真实标签的差异。

L1_loss
平均绝对误差(L1 Loss):平均绝对误差(Mean Absolute Error,MAE)是指模型预测值f(x)和真实值y之间距离的平均值,公式如下:
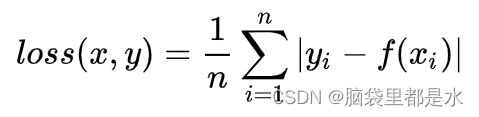
- 优点:无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解
- 缺点:在中心点是折点,不能求导,梯度下降时要是恰好学习到w=0就没法接着进行了
L2_loss
均方误差MSE(L2 LOSS):均方误差(Mean Square Error,MSE)是模型预测值f(x)和样本真实值y之间差值平方的平均值,公式如下:
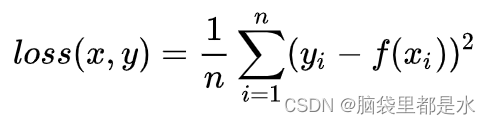
- 优点:各点都连续光滑,方便求导,具有较为稳定的解
- 缺点:不是特别的稳健,因为当函数的输入值距离真实值较远的时候,对应loss值很大在两侧,则使用梯度下降法求解的时候梯度很大,可能导致梯度爆炸
L1_loss 和L2_loss的区别

L1_loss在零点不平滑,用的较少。一般来说,L1正则会制造稀疏的特征,大部分无用的特征的权重会被置为0。(适合回归任务,简单的模型,由于神经网络通常解决复杂问题,很少使用。)
L2 loss:对离群点比较敏感,如果feature是unbounded的话,需要好好调整学习率,防止出现梯度爆炸的情况。l2正则会让特征的权重不过大,使得特征的权重比较平均。
(适合回归任务,数值特征不大,问题维度不高)
L1 Loss和L2 Loss都有缺点,那么如何解决这一问题呢?所以大神们就提出了 Smooth L1 Loss。
Smooth L1 Loss
平滑版本的L1 LOSS
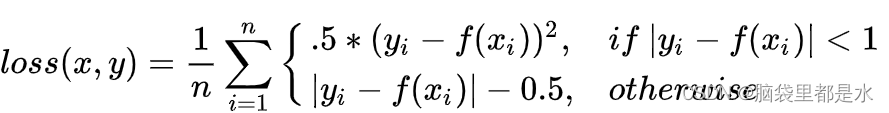
从公式中我们可以看出,当预测值f(xi)和真实值yi差别较小的时候(绝对值差小于1),其实使用的是L2 loss;差别大的时候,使用的是L1 loss的平移。因此,Smooth L1 loss其实是L1 loss 和L2 loss的结合,同时拥有两者的部分优点:
- 真实值和预测值差别较小时(绝对值差小于1),梯度也会比较小(损失函数比普通L1 loss在此处更圆滑),可以收敛得更快。
- 真实值和预测值差别较大时,梯度值足够小(普通L2 loss在这种位置梯度值就很大,容易梯度爆炸)
三者区别
(1)L1 loss在零点不平滑,此处不可导,所以在w=0时没法接着梯度下降了,用的少
(2)L2 loss对离群点比较敏感,离群点处的梯度很大,容易梯度爆炸
(3)smooth L1 loss结合了L1和L2的优点,修改了零点不平滑问题,且比L2 loss对异常值的鲁棒性更强

















 2308
2308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









