







 本文探讨了均绝对误差(MAE)、均方误差(MSE)和光滑L1损失(SmoothL1loss)在衡量模型预测与真实值差距上的特点,比较了它们在连续性、可导性、异常值处理及梯度稳定性方面的区别,对模型训练的影响和适用场景进行解析。
本文探讨了均绝对误差(MAE)、均方误差(MSE)和光滑L1损失(SmoothL1loss)在衡量模型预测与真实值差距上的特点,比较了它们在连续性、可导性、异常值处理及梯度稳定性方面的区别,对模型训练的影响和适用场景进行解析。
L1 loss 均绝对误差函数(MEAN Absolute Error)
描述模型预测值 和真实值
和真实值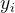 之间距离的均值
之间距离的均值

MAE连续,但是在y-ƒ(x)=0处不可导。并且可以看到MAE的梯度为±1,对于函数的极小值其附近梯度不变,这非常不利于模型训练。但正因如此,对于异常值,并没有太大影响(因为MAE计算的是误差绝对值,其惩罚是固定的)所以健壮性更好。
L2 loss均方误差函数(MEAN Square Error)
描述模型预测值和真实值之间差值平方的均值

MSE也是连续的,并且光滑,处处可导,随着误差的减小,梯度也在减小,有利于函数的收敛。由公示可以看出,当  也就是误差大于1时,会给予较大的惩罚,当误差小于1时会给予较小的惩罚。所以如果存在异常值,那么整体会收到比较大的影响。
也就是误差大于1时,会给予较大的惩罚,当误差小于1时会给予较小的惩罚。所以如果存在异常值,那么整体会收到比较大的影响。
Smooth L1 loss均方误差函数(MEAN Square Error)

Smooth L1 loss就是L1 loss与L2 loss的结合。
当误差小于1时,损失函数比L1 loss平滑,不至于梯度过大。
当误差大于1时,损失函数没有L2 loss那么爆炸,梯度比较稳定。
















 2093
2093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









