







 本文深入探讨了LSTM和GRU在深度学习中的作用,特别是它们如何处理长序列依赖,以及在自然语言处理和时间序列预测中的应用。
本文深入探讨了LSTM和GRU在深度学习中的作用,特别是它们如何处理长序列依赖,以及在自然语言处理和时间序列预测中的应用。
一.LSTM(长短时记忆网络)
1.1基本介绍
长短时记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型,属于循环神经网络(Recurrent Neural Network,RNN)的一种变体。LSTM的设计旨在解决传统RNN中遇到的长序列依赖问题,以更好地捕捉和处理序列数据中的长期依赖关系。
下面是LSTM的内部结构图

LSTM为了改善梯度消失,引入了一种特殊的存储单元,该存储单元被设计用于存储和提取长期记忆。与传统的RNN不同,LSTM包含三个关键的门(gate)来控制信息的流动,这些门分别是遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。
LSTM的结构允许它有效地处理和学习序列中的长期依赖关系,这在许多任务中很有用,如自然语言处理、语音识别和时间序列预测。由于其能捕获长期记忆,LSTM成为深度学习中重要的组件之一。
1.2 主要组成部分和工作原理
首先我们先弄明白LSTM单元中的每个符号的含义。每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制。

以下是LSTM的主要组成部分和工作原理:
-
细胞状态(Cell State):
细胞状态是LSTM网络的主要存储单元,用于存储和传递长期记忆。细胞状态在序列的每一步都会被更新。在LSTM中,细胞状态负责保留网络需要记住的信息,以便更好地处理长期依赖关系。在每个时间步,LSTM通过一系列的操作来更新细胞状态。这些操作包括遗忘门、输入门和输出门的计算。细胞状态在这些门的帮助下动态地保留和遗忘信息。
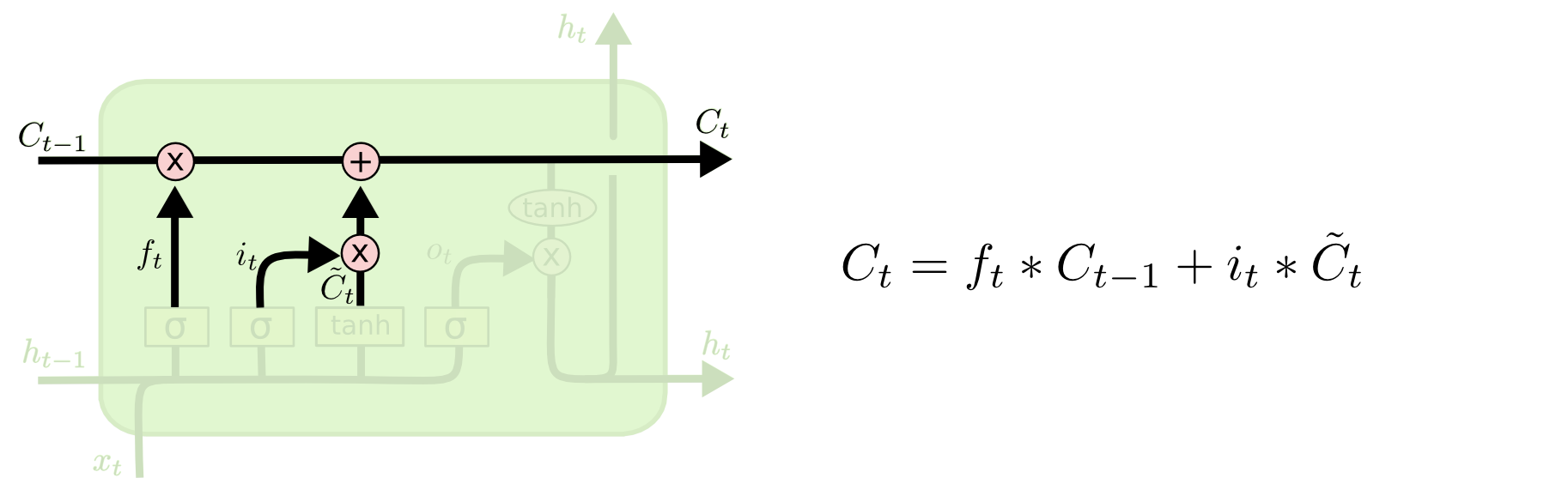
-
遗忘门(Forget Gate):
遗忘门决定哪些信息应该被遗忘,从而允许网络丢弃不重要的信息。它通过一个sigmoid激活函数生成一个介于0和1之间的值,用于控制细胞状态中信息的丢失程度。
遗忘门的计算过程如下:
2.1 输入:
上一时刻的隐藏状态(或者是输入数据的向量)
当前时刻的输入数据
2.2 计算遗忘门的值:
将上一时刻的隐藏状态和当前时刻的输入数据拼接在一起。
通过一个带有sigmoid激活函数的全连接层(通常称为遗忘门层)得到介于0和1之间的值。
这个值表示细胞状态中哪些信息应该被保留(接近1),哪些信息应该被遗忘(接近0)。
2.3 遗忘操作:
将上一时刻的细胞状态与遗忘门的输出相乘,以决定保留哪些信息。
2.4数学表达式如下:
遗忘门的输出:
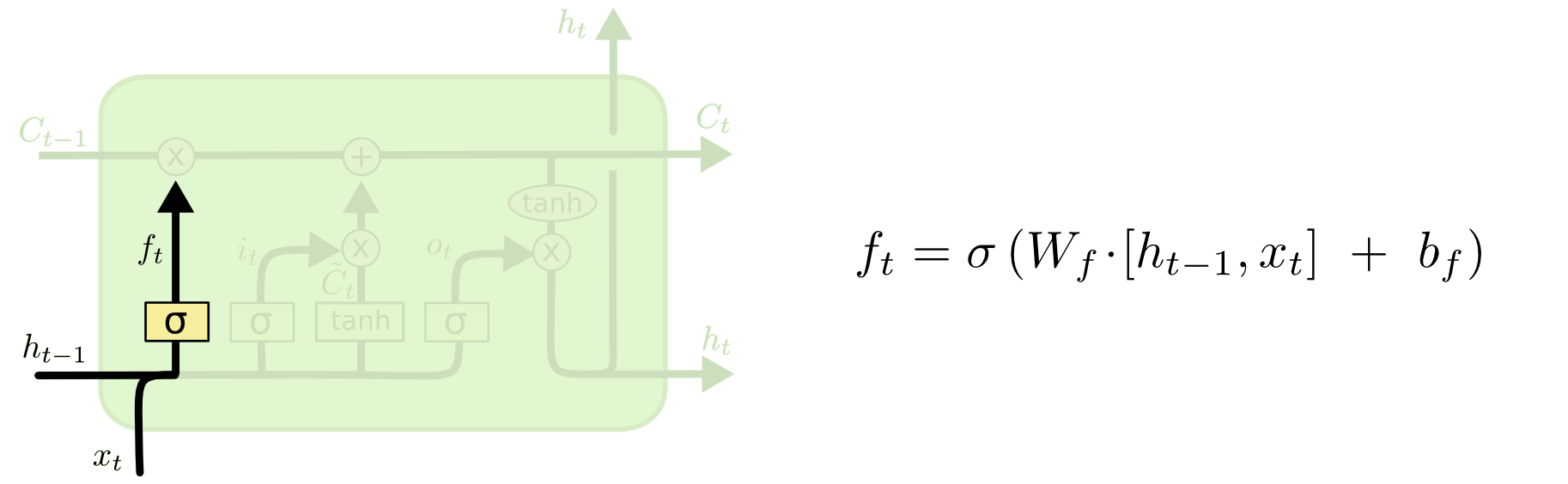
其中:
W
f
和
b
f
是遗忘门的权重矩阵和偏置向量。
W_f 和 b_f是遗忘门的权重矩阵和偏置向量。
Wf和bf是遗忘门的权重矩阵和偏置向量。
h
t
−
1
是上一时刻的隐藏状态。
h_{t−1} 是上一时刻的隐藏状态。
ht−1是上一时刻的隐藏状态。
x
t
是当前时刻的输入数据。
x_t是当前时刻的输入数据。
xt是当前时刻的输入数据。
σ
是
s
i
g
m
o
i
d
激活函数。
σ 是sigmoid激活函数。
σ是sigmoid激活函数。
遗忘门的输出 ft 决定了细胞状态中上一时刻信息的保留程度。这个机制允许LSTM网络在处理时间序列数据时更有效地记住长期依赖关系。
- 输入门(Input Gate):
输入门负责确定在当前时间步骤中要添加到细胞状态的新信息。类似于遗忘门,输入门使用sigmoid激活函数产生一个介于0和1之间的值,表示要保留多少新信息,并使用tanh激活函数生成一个新的候选值。
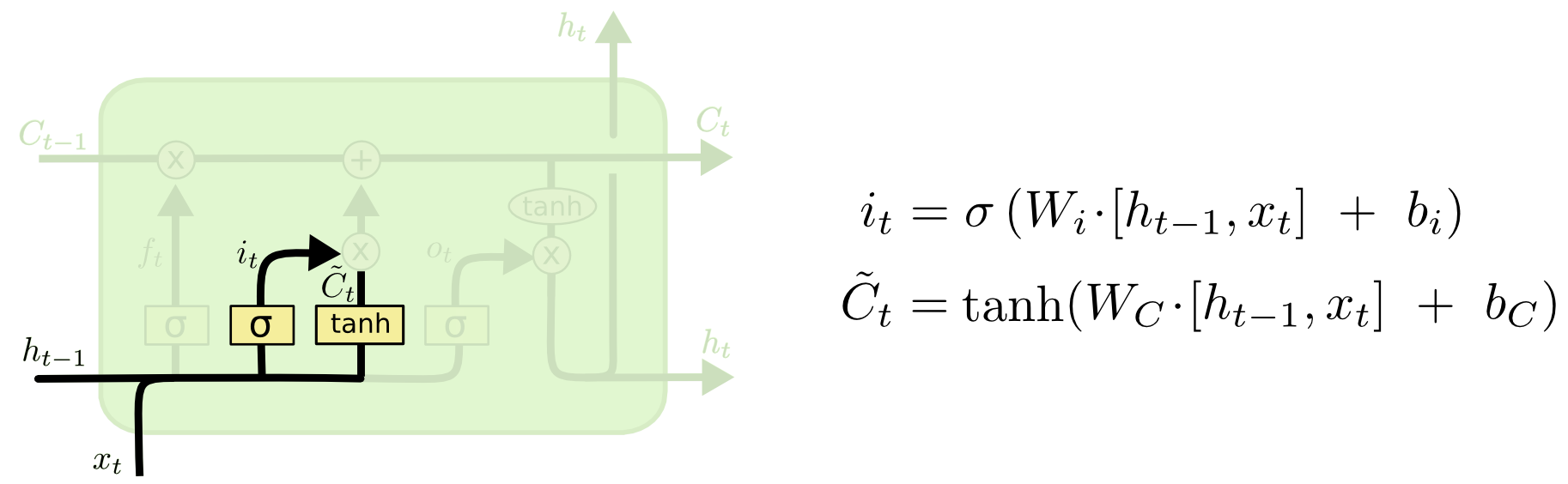 输入门的计算过程如下:
输入门的计算过程如下:
(1)输入门的输出计算:
将上一时刻的隐藏状态(或者是输入数据)和当前时刻的输入数据拼接在一起。
通过一个带有sigmoid激活函数的全连接层得到介于0和1之间的值。这个值表示要保留的新信息的程度。
(2)生成新的候选值:
将上一时刻的隐藏状态(或者是输入数据)和当前时刻的输入数据拼接在一起。
通过一个带有tanh激活函数的全连接层得到一个新的候选值(介于-1和1之间)。
(3)更新细胞状态的操作:
将输入门的输出与新的候选值相乘,得到要添加到细胞状态的新信息。
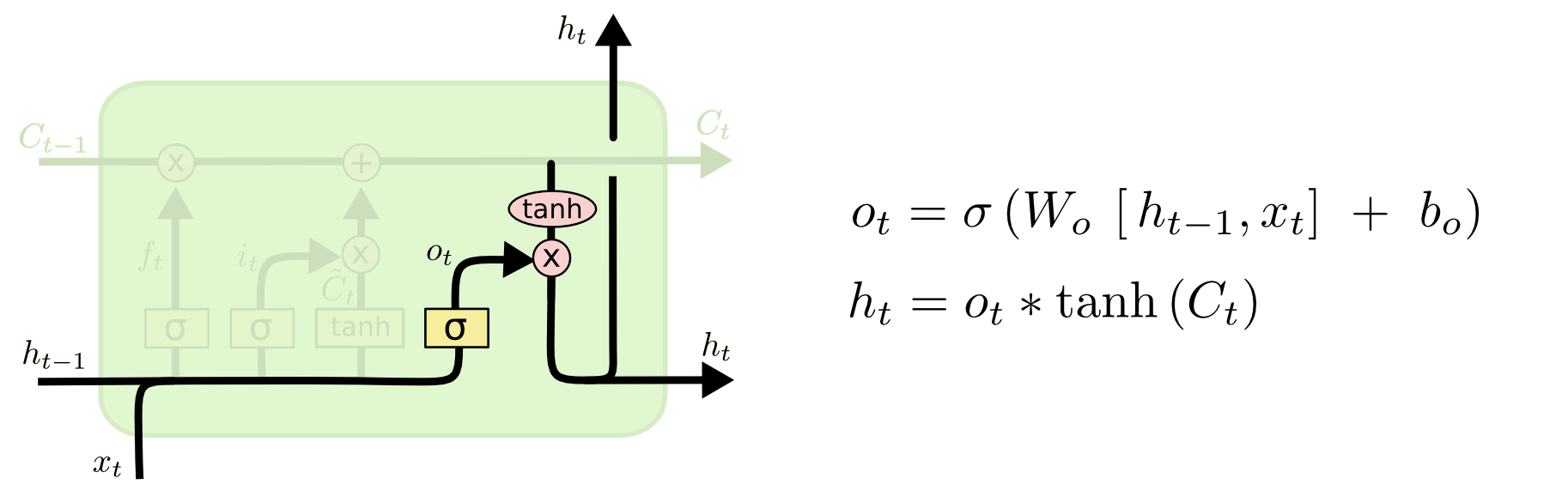
- 输出门(Output Gate):
输出门(Output Gate)在LSTM中控制细胞在特定时间步上的输出。输出门使用sigmoid激活函数产生介于0和1之间的值,这个值决定了在当前时间步细胞状态中有多少信息被输出。同时,输出门的输出与细胞状态经过tanh激活函数后的值相乘,产生最终的LSTM输出。
输出门的计算过程如下:
输出门的输出计算:
将上一时刻的隐藏状态(或者是输入数据)和当前时刻的输入数据拼接在一起。
通过一个带有sigmoid激活函数的全连接层得到介于0和1之间的值。
这个值表示在当前时间步细胞状态中有多少信息要输出。
生成最终的LSTM输出:
将当前时刻的细胞状态经过tanh激活函数,得到介于-1和1之间的值。
将输出门的输出与tanh激活函数的细胞状态相乘,产生最终的LSTM输出。
1.3 LSTM的基础代码实现
以下是一个基础的实现,其中包括多层双向LSTM的前向传播。请注意,这个实现仍然是一个简化版本,实际应用中可能需要更多的调整和优化。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return np.tanh(x)
def lstm_cell(xt, a_prev, c_prev, parameters):
# 从参数中提取权重和偏置
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wc = parameters["Wc"]
bc = parameters["bc"]
# 合并输入和上一个时间步的隐藏状态
concat = np.concatenate((a_prev, xt), axis=0)
# 遗忘门
ft = sigmoid(np.dot(Wf, concat) + bf)
# 输入门
it = sigmoid(np.dot(Wi, concat) + bi)
# 更新细胞状态
cct = tanh(np.dot(Wc, concat) + bc)
c_next = ft * c_prev + it * cct
# 输出门
ot = sigmoid(np.dot(Wo, concat) + bo)
# 更新隐藏状态
a_next = ot * tanh(c_next)
# 保存计算中间结果,以便反向传播
cache = (xt, a_prev, c_prev, a_next, c_next, ft, it, ot, cct)
return a_next, c_next, cache
def lstm_forward(x, a0, parameters):
n_x, m, T_x = x.shape
n_a = a0.shape[0]
a = np.zeros((n_a, m, T_x))
c = np.zeros_like(a)
caches = []
a_prev = a0
c_prev = np.zeros_like(a_prev)
for t in range(T_x):
xt = x[:, :, t]
a_next, c_next, cache = lstm_cell(xt, a_prev, c_prev, parameters)
a[:,:,t] = a_next
c[:,:,t] = c_next
caches.append(cache)
a_prev = a_next
c_prev = c_next
return a, c, caches
def lstm_model_forward(x, parameters):
caches = []
a = x
c_list = []
for layer in parameters:
a, c, layer_cache = lstm_forward(a, np.zeros_like(a[:, :, 0]), layer)
caches.append(layer_cache)
c_list.append(c)
return a, c_list, caches
def dense_layer_forward(a, parameters):
W = parameters["W"]
b = parameters["b"]
z = np.dot(W, a) + b
a_next = sigmoid(z)
return a_next, z
def model_forward(x, parameters_lstm, parameters_dense):
a_lstm, c_list, caches_lstm = lstm_model_forward(x, parameters_lstm)
a_dense = a_lstm[:, :, -1]
z_dense_list = []
for layer_dense in parameters_dense:
a_dense, z_dense = dense_layer_forward(a_dense, layer_dense)
z_dense_list.append(z_dense)
return a_dense, c_list, caches_lstm, z_dense_list
# 示例数据和参数
np.random.seed(1)
x = np.random.randn(10, 5, 3) # 10个样本,每个样本5个时间步,每个时间步3个特征
# LSTM参数
parameters_lstm = [
{"Wf": np.random.randn(5, 8), "bf": np.random.randn(5, 1),
"Wi": np.random.randn(5, 8), "bi": np.random.randn(5, 1),
"Wo": np.random.randn(5, 8), "bo": np.random.randn(5, 1),
"Wc": np.random.randn(5, 8), "bc": np.random.randn(5, 1)},
{"Wf": np.random.randn(3, 8), "bf": np.random.randn(3, 1),
"Wi": np.random.randn(3, 8), "bi": np.random.randn(3, 1),
"Wo": np.random.randn(3, 8), "bo": np.random.randn(3, 1),
"Wc": np.random.randn(3, 8), "bc": np.random.randn(3, 1)}
]
# Dense层参数
parameters_dense = [
{"W": np.random.randn(1, 5), "b": np.random.randn(1, 1)},
{"W": np.random.randn(1, 5), "b": np.random.randn(1, 1)}
]
# 进行正向传播
a_dense, c_list, caches_lstm, z_dense_list = model_forward(x, parameters_lstm, parameters_dense)
# 打印输出形状
print("a_dense.shape:", a_dense.shape)
二.GRU(门控循环单元)

2.1 GRU的基本介绍
门控循环单元(GRU,Gated Recurrent Unit)是一种用于处理序列数据的循环神经网络(RNN)变体,旨在解决传统RNN中的梯度消失问题,并提供更好的长期依赖建模。GRU引入了门控机制,类似于LSTM,但相对于LSTM,GRU结构更加简单。
GRU包含两个门:更新门(Update Gate)和重置门(Reset Gate)。这两个门允许GRU网络决定在当前时间步更新细胞状态的程度以及如何利用先前的隐藏状态。
重置门(Reset Gate)的计算:
通过一个sigmoid激活函数计算重置门的输出。重置门决定了在当前时间步,应该忽略多少先前的隐藏状态信息。
更新门(Update Gate)的计算:
通过一个sigmoid激活函数计算更新门的输出。更新门决定了在当前时间步,应该保留多少先前的隐藏状态信息。
候选隐藏状态的计算:
通过tanh激活函数计算一个候选的隐藏状态。
新的隐藏状态的计算:
通过更新门和候选隐藏状态计算新的隐藏状态。
2.2 GRU的代码实现
以下是使用PyTorch库实现基本的门控循环单元(GRU)的代码。PyTorch提供了GRU的高级API,可以轻松实现和使用。下面是一个简单的例子:
import torch
import torch.nn as nn
# 定义GRU模型
class SimpleGRU(nn.Module):
def __init__(self, input_size, hidden_size):
super(SimpleGRU, self).__init__()
self.gru = nn.GRU(input_size, hidden_size)
def forward(self, x, hidden=None):
output, hidden = self.gru(x, hidden)
return output, hidden
# 示例数据和模型参数
input_size = 3
hidden_size = 5
seq_len = 1 # 序列长度
batch_size = 1
# 创建GRU模型
gru_model = SimpleGRU(input_size, hidden_size)
# 将输入数据转换为PyTorch的Tensor
x = torch.randn(seq_len, batch_size, input_size)
# 前向传播
output, hidden = gru_model(x)
# 打印输出形状
print("Output shape:", output.shape)
print("Hidden shape:", hidden.shape)
以下是使用NumPy库实现基本的门控循环单元(GRU)的代码。这个实现是一个简化版本,其中包含更新门和重置门的计算,以及候选隐藏状态和新的隐藏状态的计算。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return np.tanh(x)
def gru_cell(a_prev, x, parameters):
# 从参数中提取权重和偏置
W_r = parameters["W_r"]
b_r = parameters["b_r"]
W_z = parameters["W_z"]
b_z = parameters["b_z"]
W_a = parameters["W_a"]
b_a = parameters["b_a"]
# 计算重置门
r_t = sigmoid(np.dot(W_r, np.concatenate([a_prev, x])) + b_r)
# 计算更新门
z_t = sigmoid(np.dot(W_z, np.concatenate([a_prev, x])) + b_z)
# 计算候选隐藏状态
tilde_a_t = tanh(np.dot(W_a, np.concatenate([r_t * a_prev, x])) + b_a)
# 计算新的隐藏状态
a_t = (1 - z_t) * a_prev + z_t * tilde_a_t
# 保存计算中间结果,以便反向传播
cache = (a_prev, x, r_t, z_t, tilde_a_t, a_t)
return a_t, cache
# 示例数据和参数
np.random.seed(1)
a_prev = np.random.randn(5, 1) # 上一时刻的隐藏状态
x = np.random.randn(3, 1) # 当前时刻的输入数据
# GRU参数
parameters = {
"W_r": np.random.randn(5, 8),
"b_r": np.random.randn(5, 1),
"W_z": np.random.randn(5, 8),
"b_z": np.random.randn(5, 1),
"W_a": np.random.randn(5, 8),
"b_a": np.random.randn(5, 1)
}
# 单个GRU单元的前向传播
a_t, cache = gru_cell(a_prev, x, parameters)
# 打印输出形状
print("a_t.shape:", a_t.shape)
本文参考了以下链接:http://colah.github.io/posts/2015-08-Understanding-LSTMs/


















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











