







集成学习-泰坦尼克号船员获救预测
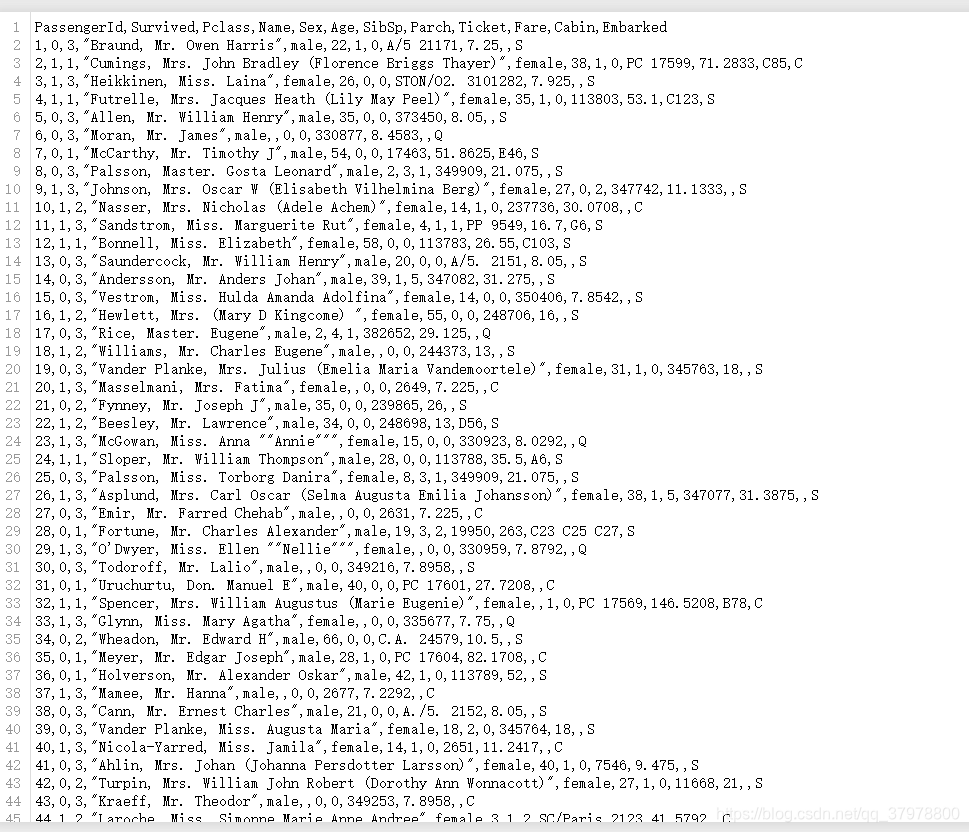
import pandas
titanic = pandas.read_csv("titanic_train.csv")
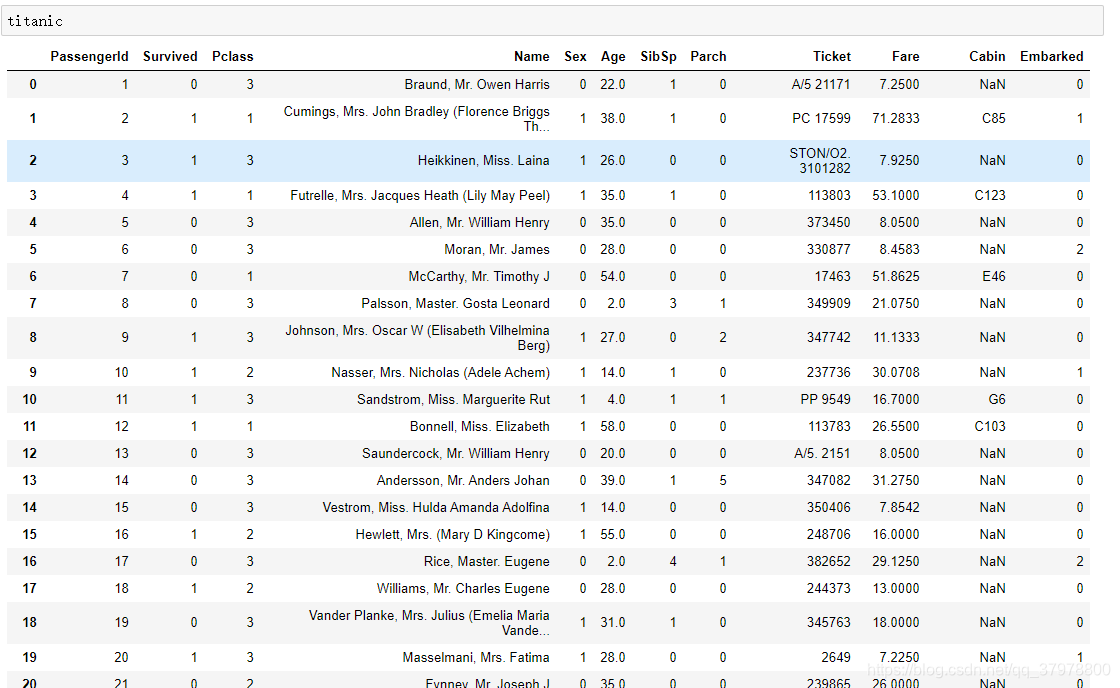
titanic
# 空余的age填充整体age的中值
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
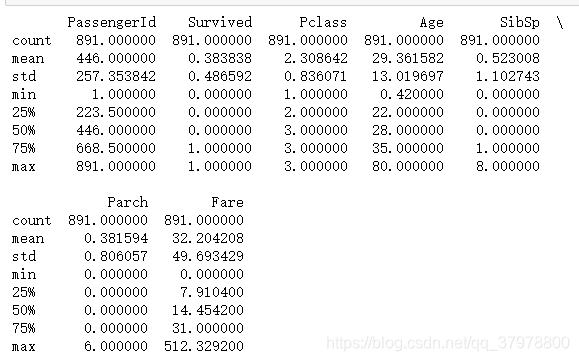
print(titanic.describe())

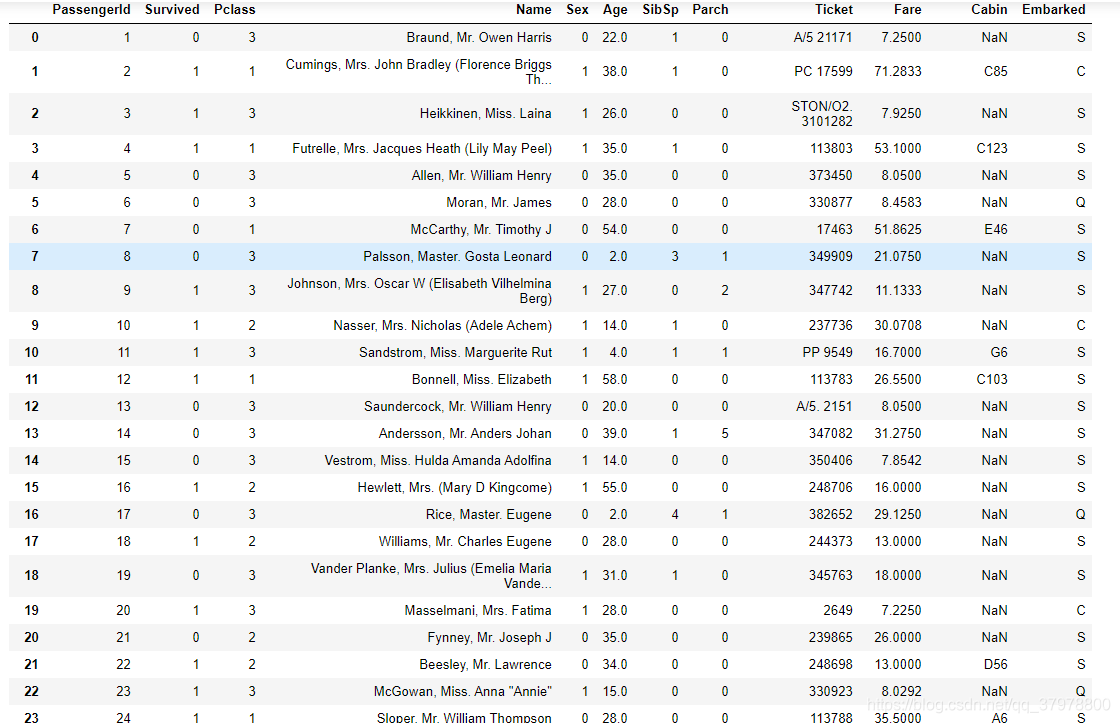
print(titanic["Sex"].unique())
# 把male变成0,把female变成1
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1

print(titanic["Embarked"].unique())
# 数据填充
titanic["Embarked"] = titanic["Embarked"].fillna('S')
# 把类别变成数字
titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0
titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1
titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2

from sklearn.preprocessing import StandardScaler
# 选定特征
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
x_data = titanic[predictors]
y_data = titanic["Survived"]
# 数据标准化
scaler = StandardScaler()
x_data = scaler.fit_transform(x_data)
逻辑回归
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
# 逻辑回归模型
LR = LogisticRegression()
# 计算交叉验证的误差
scores = model_selection.cross_val_score(LR, x_data, y_data, cv=3)
# 求平均
print(scores.mean())

神经网络
from sklearn.neural_network import MLPClassifier
# 建模
mlp = MLPClassifier(hidden_layer_sizes=(20,10),max_iter=1000)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(mlp, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
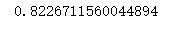
KNN
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier(21)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(knn, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
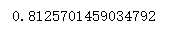
决策树
from sklearn import tree
# 决策树模型
dtree = tree.DecisionTreeClassifier(max_depth=5, min_samples_split=4)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(dtree, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
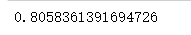
随机森林
# 随机森林
from sklearn.ensemble import RandomForestClassifier
RF1 = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(RF1, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
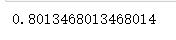
RF2 = RandomForestClassifier(n_estimators=100, min_samples_split=4)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(RF2, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
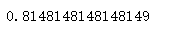
Bagging
from sklearn.ensemble import BaggingClassifier
bagging_clf = BaggingClassifier(RF2, n_estimators=20)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(bagging_clf, x_data, y_data, cv=3)
# 求平均
print(scores.mean())

Adaboost
from sklearn.ensemble import AdaBoostClassifier
# AdaBoost模型
adaboost = AdaBoostClassifier(bagging_clf,n_estimators=10)
# 计算交叉验证的误差
scores = model_selection.cross_val_score(adaboost, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
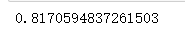
Stacking
from sklearn.ensemble import VotingClassifier
from mlxtend.classifier import StackingClassifier
sclf = StackingClassifier(classifiers=[bagging_clf, mlp, LR],
meta_classifier=LogisticRegression())
sclf2 = VotingClassifier([('adaboost',adaboost), ('mlp',mlp), ('LR',LR),('knn',knn),('dtree',dtree)])
# 计算交叉验证的误差
scores = model_selection.cross_val_score(sclf2, x_data, y_data, cv=3)
# 求平均
print(scores.mean())
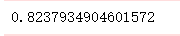
集成学习-乳腺癌预测

import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("data.csv")
df.head()
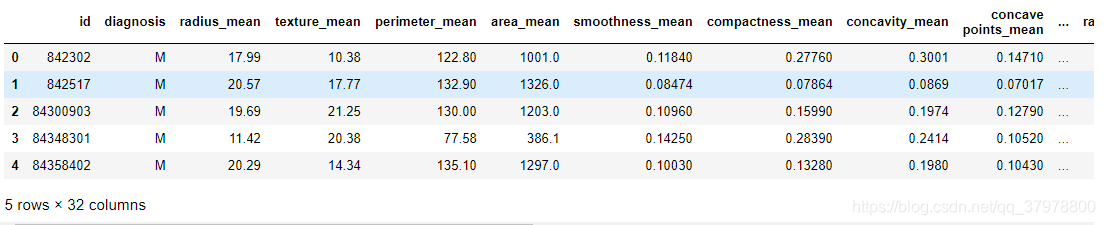
df = df.drop('id', axis=1)
df.diagnosis.unique()
df['diagnosis'] = df['diagnosis'].map({'M':1,'B':0})
df.head()
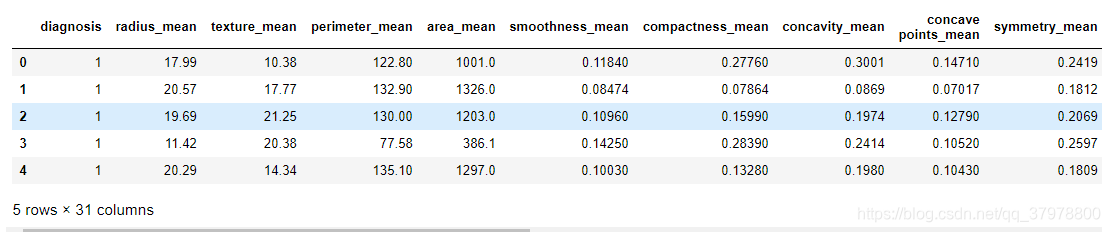
df.describe()
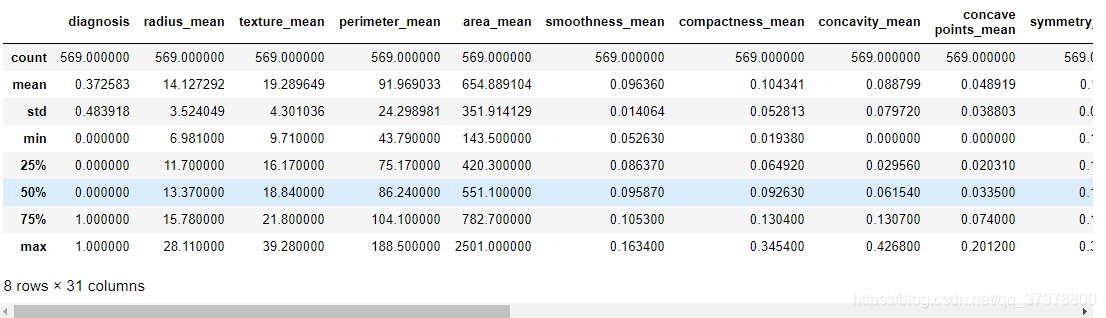
# 画热力图,数值为两个变量之间的相关系数
plt.figure(figsize=(20,20))
p=sns.heatmap(df.corr(), annot=True ,square=True)
plt.show()
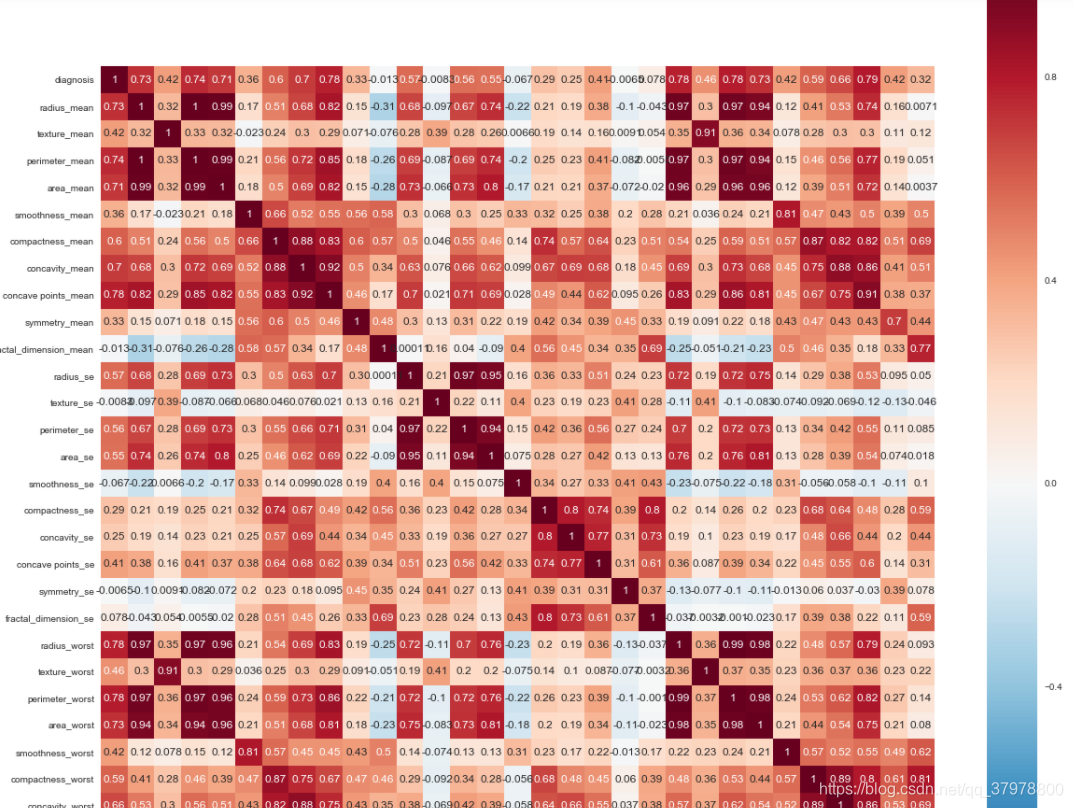
# 查看标签分布
print(df.diagnosis.value_counts())
# 使用柱状图的方式画出标签个数统计
p=df.diagnosis.value_counts().plot(kind="bar")
plt.show()
# 获取训练数据和标签
x_data = df.drop(['diagnosis'], axis=1)
y_data = df['diagnosis']
from sklearn.model_selection import train_test_split
# 切分数据集,stratify=y表示切分后训练集和测试集中的数据类型的比例跟切分前y中的比例一致
# 比如切分前y中0和1的比例为1:2,切分后y_train和y_test中0和1的比例也都是1:2
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data, test_size=0.3, stratify=y_data)
from sklearn.metrics import accuracy_score
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, BaggingClassifier
classifiers = [
KNeighborsClassifier(3),
LogisticRegression(),
MLPClassifier(hidden_layer_sizes=(20,50),max_iter=10000),
DecisionTreeClassifier(),
RandomForestClassifier(max_depth=9,min_samples_split=3),
AdaBoostClassifier(),
BaggingClassifier(),
]
log = []
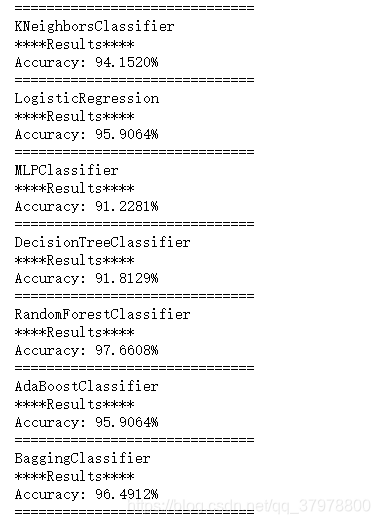
for clf in classifiers:
clf.fit(x_train, y_train)
name = clf.__class__.__name__
print("="*30)
print(name)
print('****Results****')
test_predictions = clf.predict(x_test)
acc = accuracy_score(y_test, test_predictions)
print("Accuracy: {:.4%}".format(acc))
log.append([name, acc*100])
print("="*30)
log = pd.DataFrame(log)
log
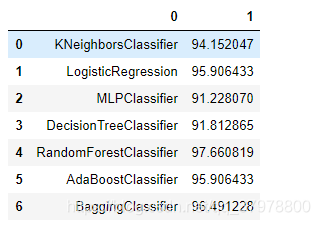
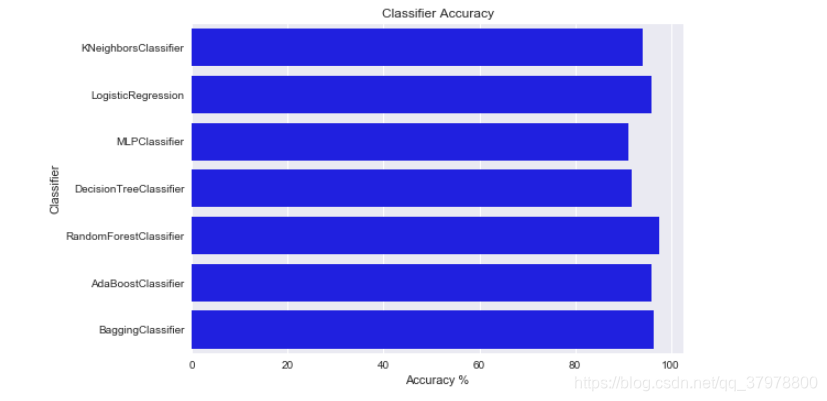
log.rename(columns={0: 'Classifier', 1:'Accuracy'}, inplace=True)
sns.barplot(x='Accuracy', y='Classifier', data=log, color="b")
plt.xlabel('Accuracy %')
plt.title('Classifier Accuracy')
plt.show()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









