







朴素贝叶斯概念
例子:邮件分类问题:


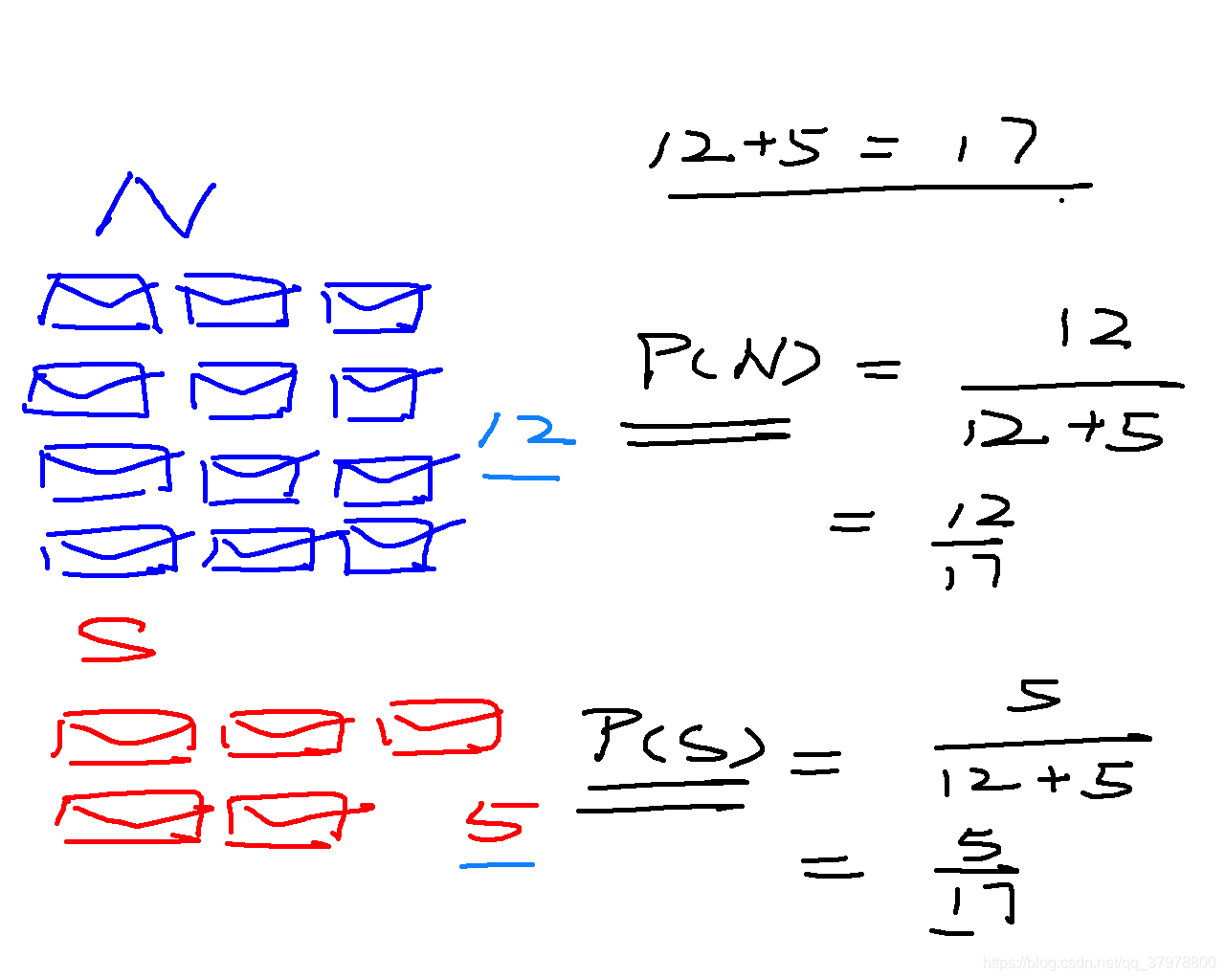

N = (12/17)*(5/11)*(3/11)
S = (5/17)*(2/7)*(1/7)
print(N)
print(S)
# N>S 我们可以判断这是一封正常邮件
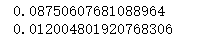
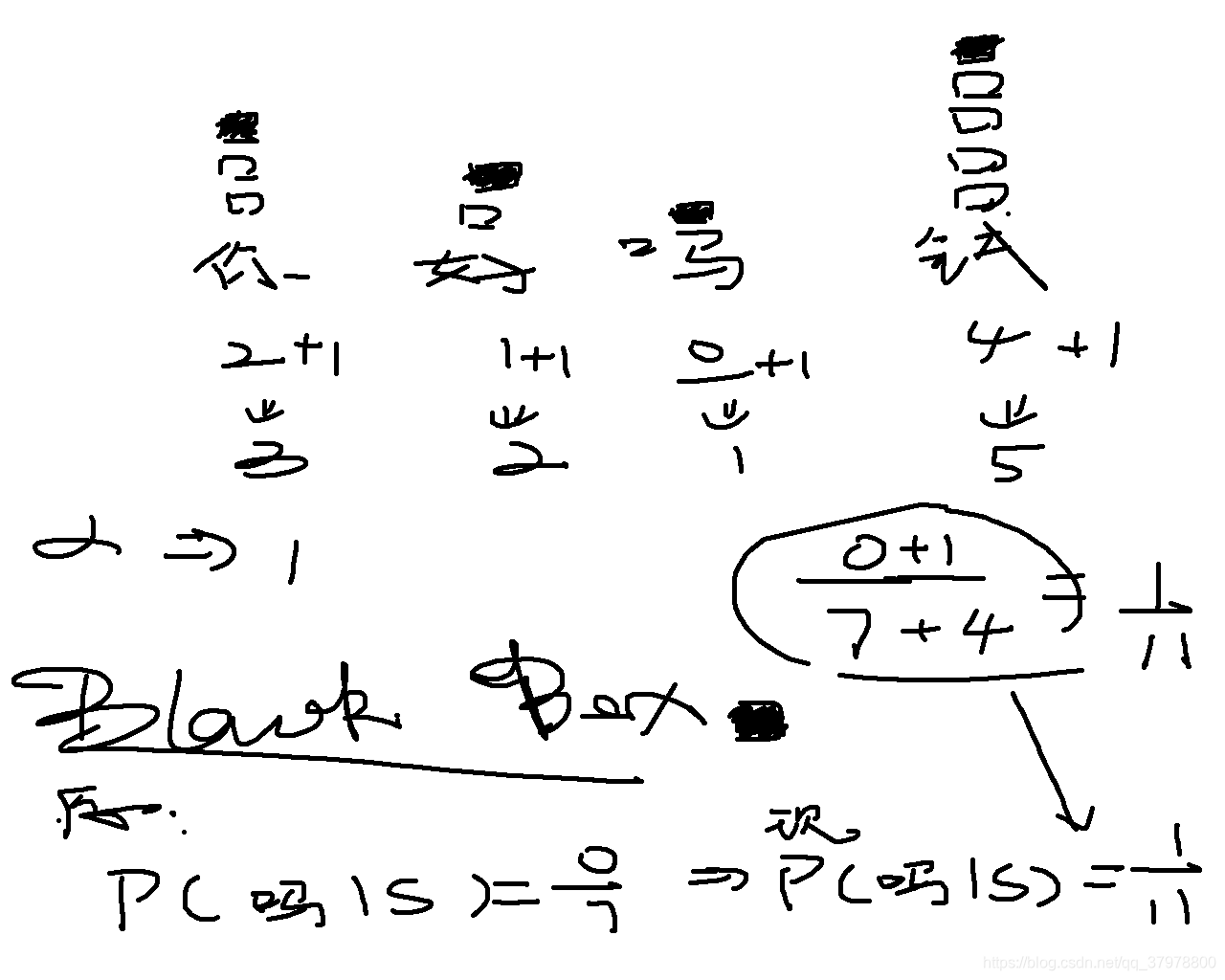
常见问题1
因为图2中 吗出现的次数是0 那么这封邮件就会被误判为正常邮件

解决如果遇到样本里面有0的情况,可以通过添加alpha进行解决。
alpha=1 统一增加1 确保不会出现无0的情况
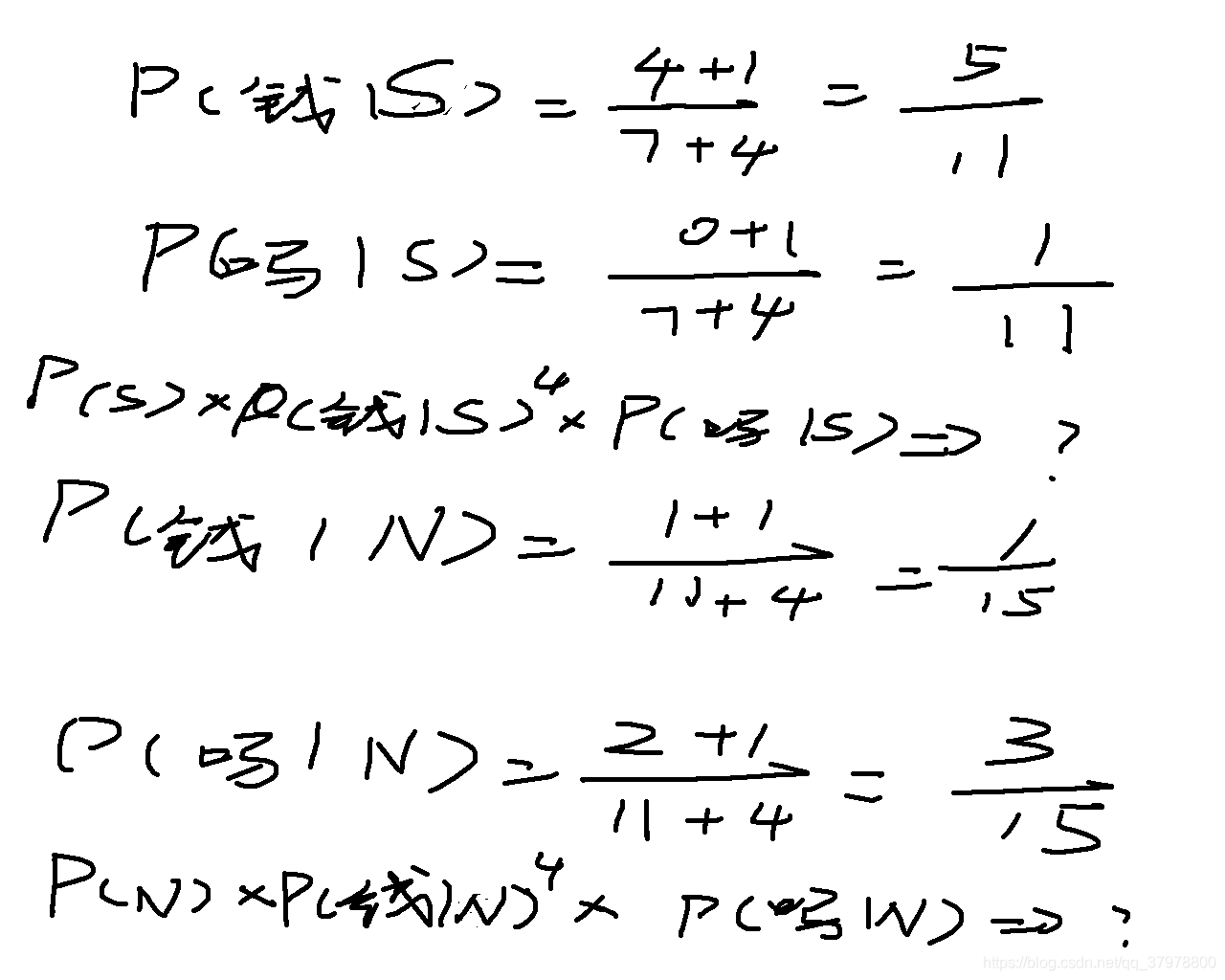
N = (12/17)*((1/15)**4)*(3/15)
S = (5/17)*((5/11)**4)*(1/11)
print(N)
print(S)
print(S > N)

贝叶斯代码
数据切分
def split_our_data_by_class(dataset):# 按类别拆分数据 传入参数数据
splited_data = dict() # 按字典储存
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in splited_data):
splited_data[class_value] =list()
splited_data[class_value].append(vector)
return splited_data
# create our dummy data
dataset = [ [0.8,2.3,0],
[2.1,1.6,0],
[2.0,3.6,0],
[3.1,2.5,0],
[3.8,4.7,0],
[6.1,4.4,1],
[8.6,0.3,1],
[7.9,5.3,1],
[9.1,2.5,1],
[6.8,2.7,1]]
splited = split_our_data_by_class(dataset)
print(splited)
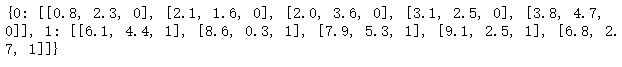
# 逐行打印
for label in splited:
print(label)
for row in splited[label]:
print(row)

calculate mean and standard deviation(n-1):计算平均值和标准差(n-1)
from math import sqrt
def calculate_the_mean(a_list_of_num): # 平均值函数
mean = sum(a_list_of_num)/float(len(a_list_of_num)) # 求总和除以数据个数
return mean
def calculate_the_standard_deviation(a_list_of_num): # 计算标准差
the_mean = calculate_the_mean(a_list_of_num) # 调用平均值函数计算平均值
the_variance = sum([(x-the_mean)**2 for x in a_list_of_num])/ float(len(a_list_of_num)-1)# {每个值减去平均值的平方除以数据的(个数-1)}结果相加的总和
std = sqrt(the_variance) # 开方
return std
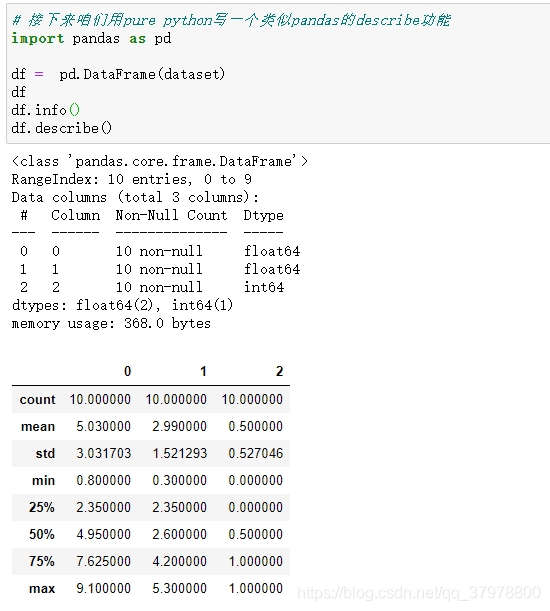
def describe_our_data(dataset):# 调用函数
description = [(calculate_the_mean(column),
calculate_the_standard_deviation(column),
len(column)) for column in zip(*dataset)]
del(description[-1]) # 删除最后一列的分类标签
return description
describe_our_data(dataset)
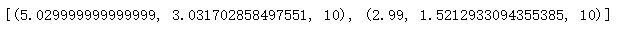
def describe_our_data_by_class(dataset):# 综合
splited_data = split_our_data_by_class(dataset)
data_description = dict()# 创建一个空字典来存储
for class_value,rows in splited_data.items():# 通过迭代填入空字典
data_description[class_value] = describe_our_data(rows)
return data_description
description = describe_our_data_by_class(dataset)
for label in description:
print(label)
for row in description[label]:
print(row)

description = describe_our_data_by_class(dataset)
type(description)
print(description)
print("---------")
print(description[0])
print("---------")
print(description[0][0])
print("--------")
print(description[0][0][2])

def calculate_class_probability(description,row): # 根据类别计算概率
total_rows = sum([description[label][0][2] for label in description])
probabilities = dict()
for class_value,class_description in description.items():
probabilities[class_value] = description[class_value][0][2]/float(total_rows)
for i in range(len(class_description)):
mean,stdev,count = class_description[i]
probabilities[class_value] *= calculate_the_probability(row[i],mean,stdev)
return probabilities
代码整合测试
from math import sqrt
from math import pi
from math import exp
def split_our_data_by_class(dataset):
splited_data = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in splited_data):
splited_data[class_value] = list()
splited_data[class_value].append(vector)
return splited_data
def calculate_the_mean(a_list_of_num):
mean = sum(a_list_of_num) / float(len(a_list_of_num))
return mean
def calculate_the_standard_deviation(a_list_of_num):
the_mean = calculate_the_mean(a_list_of_num)
the_variance = sum([(x - the_mean) ** 2 for x in a_list_of_num]) / float(len(a_list_of_num) - 1)
std = sqrt(the_variance)
return std
def describe_our_data(dataset):
description = [(calculate_the_mean(column),
calculate_the_standard_deviation(column),
len(column)) for column in zip(*dataset)]
del (description[-1])
return description
def describe_our_data_by_class(dataset):
splited_data = split_our_data_by_class(dataset)
data_description = dict()
for class_value, rows in splited_data.items():
data_description[class_value] = describe_our_data(rows)
return data_description
def calculate_the_probability(x, mean, stdev):
exponent = exp(-((x - mean) ** 2 / (2 * stdev ** 2)))
result = (1 / (sqrt(2 * pi) * stdev)) * exponent
return result
def calculate_class_probability(description, row):
total_rows = sum([description[label][0][2] for label in description])
probabilities = dict()
for class_value, class_description in description.items():
probabilities[class_value] = description[class_value][0][2] / float(total_rows)
for i in range(len(class_description)):
mean, stdev, count = class_description[i]
probabilities[class_value] *= calculate_the_probability(row[i], mean, stdev)
return probabilities
dataset = [[0.8, 2.3, 0],
[2.1, 1.6, 0],
[2.0, 3.6, 0],
[3.1, 2.5, 0],
[3.8, 4.7, 0],
[6.1, 4.4, 1],
[8.6, 0.3, 1],
[7.9, 5.3, 1],
[9.1, 2.5, 1],
[6.8, 2.7, 1]]
description = describe_our_data_by_class(dataset)
probability = calculate_class_probability(description, dataset[0])
print(probability)
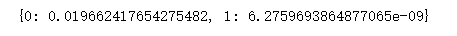















 2764
2764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









