







本篇文章为wwwHe同学的面经分享的下篇,这里给出面试会问到的问题以及部分问题的答案解析,希望能帮助现在还在找工作找实习的朋友们顺利拿下大厂offer。
腾讯调剂后一面
1、项目三连(挖的不是很深,因为面试官有上一次面试的记录);
2、LGBM特征重要性的衡量指标;
答:主要是total_cover、total_gain和weight,total_cover是在所有树中,某特征在其所有节点上分割样本的个数总和,total_gain是在所有树中,某特征在其所有节点上分裂所带来的增益总和(信息熵或者基尼不纯度),weight是某个特征在所有树中的分裂次数总和。
3、标签不均匀问题如何解决;
答:主要有采样法,即欠采样、过采样以及SMOTE(基于插值构造样本),像CV、NLP领域也可以数据增强来平衡标签,另外对于二分类问题还可以通过控制阀值来划分样本,除此之外还有模型融合、F1和focalloss等方法解决标签不平衡问题。
4、level-wise和leaf-wise的原理、区别以及会产生什么后果;
答:level-wise 策略生长树,记一次分裂同一层的叶子,不加区分的对待同一层的叶子,而实际上很多叶子的分裂增益较低没必要进行分裂,带来了没必要的开销,而leaf-wise每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。但是,当样本量较小的时候,leaf-wise 可能会造成过拟合。
5、过拟合的解决方案;
答:常见的有正则化、早停、剪枝、dropout、BN、bagging、加噪声等
6、算法一:最大子序列和(leetcode.53)
7、算法二:快速排序
总结,面试官很温柔,谢轻虐!
腾讯调剂后二面
1、项目三连(同样挖的不是很深);
2、评价项目中其他人的价值;
3、如何解释极大似然估计?能否用更通俗的话解释?让没学过概率论的人听懂。
答:似然指已知数据推断参数,而极大似然估计即在已知数据求最大可能的参数(不知道够不够通俗易懂)
4、梯度下降改进的优化方法,步长调整包括哪些、梯度方向修正包括哪些、综合方法Adam;
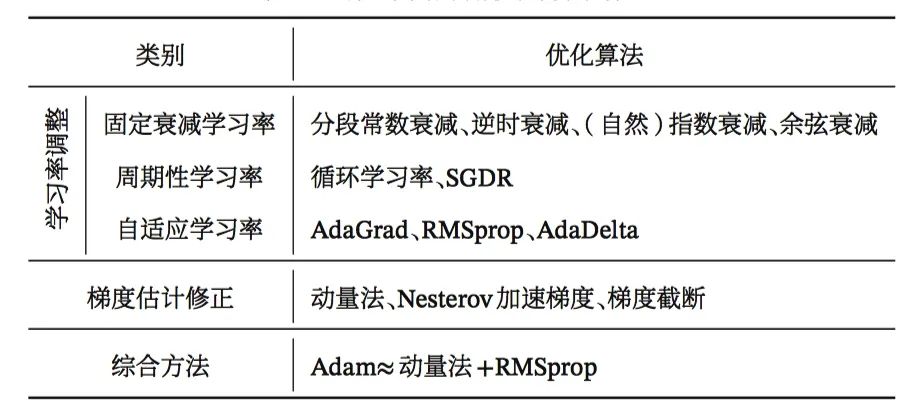
5、集成学习bagging、Boosting、Stacking;
-
bagging该方法通常考虑的是同质弱学习器,相互独立地并行学习这些弱学习器,并按照某种确定性的平均过程将它们组合起来。
-
boosting,该方法通常考虑的也是同质弱学习器。它以一种高度自适应的方法顺序地学习这些弱学习器(每个基础模型都依赖于前面的模型),并按照某种确定性的策略将它们组合起来。
-
stacking,该方法通常考虑的是异质弱学习器,并行地学习它们,并通过训练一个「元模型」将它们组合起来,根据不同弱模型的预测结果输出一个最终的预测结果。
算法:有交易次数限制的最佳股票买卖时机 Leetcode.188;
添加助手微信回复研究方向或专业即可加入我们的微信交流群或QQ交流群


扫码关注我们

携手2021年,为梦想启程!















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









