







1.LeNet5:
5*5卷积核,最大池化
2.AlexNet:
relu激活函数,dropout和数据增强,LRN,GROUP CONV,重叠池化
3.VGG:
网络约深越好,3*3卷积核比5的好,LRN没用
4.GoogleNet:
a.Inception V1
让网络自己选择合适的网络卷积核,减少参数量
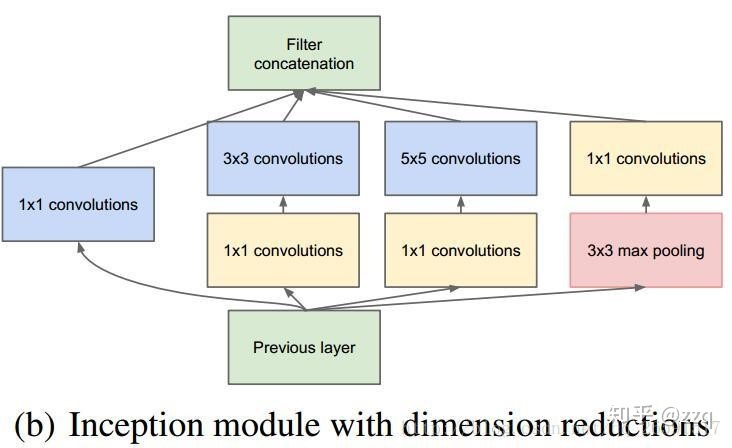
b.Inceptionv2:
使用3*3代替5*5,引入bn结构和relu激活函数
c.Inceptionv3:
将卷积核分解成更小的卷积,7*7分成1*7和7*1(非对称卷积)
d.Inceptionv4:
引入更多Inception module,
以往的inception网络,没有在结构上做很大的改动。以前结构的保守、固定直接导致了网络和结构的灵活性欠佳。反而导致网络看起来更复杂。
摆脱以往的包袱,我们做了一个统一,为每一个Inception块做出统一的选择。
e.XInception:
引入残差结构,与可分离卷积相反,先使用1*1卷积再进行空间卷积,再用3*3进行channelwise的分离卷积,最后每个块之间concact。并在每个操作后加上relu。该方法并没降低模型的参数,而是提高了模型的性能
5.mobilenet:
a.mobilenetv1:
深度可分离卷积
b.mobilenetv2:
认为深度可分离卷积压缩会造成特征丢失,再可分离卷积之前使用1*1卷积增加通道数,采取先扩张再压缩,同时使用linear代替relu激活函数避免信息丢失。
c.mobilenetv3:
使用NAS搜索,设计该进网络结构
综合了v1的深度可分离卷积,纺锤型moudule结构,se结构的轻量级注意力模型
6.effnet:
将深度可分离卷积使用1*3 和3*1代替,再卷积后增加池化层,减少计算量
7.efficientNet:
设计depth,width,resolition(分辨率)
8.Resnet:
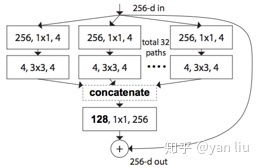
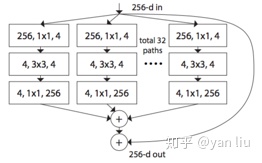
这里只说Resnext:
split-transform-merge
结合Inception结构,同时使用一个block中具有的相同分支的数目可以更好的提升模型表达能力。
(先执行1*1卷积再执行单位加)
9.Densenet:
特征重用来大幅减少网络的参数量,又在一定程度上缓解了梯度消失问题
10.squeezenet:
Squeeze层就是1×1卷积,expand层用1×1和3×3分别卷积,然后concatenation
11.ShuffleNet:
a.ShuffleNetv1:
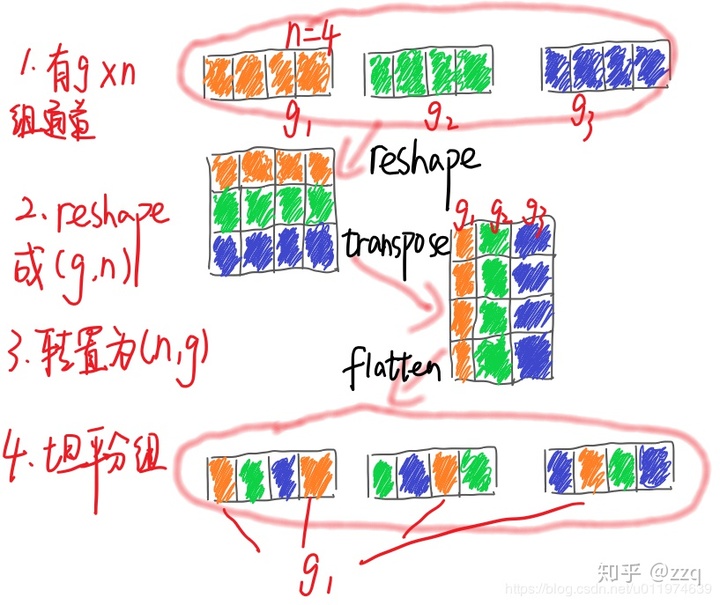
使用1*1卷积消耗资源,使用通道shuffle之后,就可以替换掉1*1卷积,减少计算。是在低功耗设备上,与密集的操作相比,计算、存储访问的效率更差,故shufflenet上旨在bottleneck上使用深度卷积,尽可能减少开销
b.shufflenetv2:
使神经网络更加高效的CNN网络结构设计准则:
输入通道数与输出通道数保持相等可以最小化内存访问成本
分组卷积中使用过多的分组会增加内存访问成本
网络结构太复杂(分支和基本单元过多)会降低网络的并行程度
element-wise的操作消耗也不可忽略
1.two-stage:R-CNN、SPPNet、Fast R-CNN、Faster R-CNN:
R-CNN:
使用selective search 无监督的搜索候选区域,产生2000个候选区,并从原图像中截图,将其裁剪缩放至合适尺寸,送入cnn网络提取高维特征(最后一层是全连接层),特征送入svm分类器进行物体分类,使用线性回归器进行边界框位置和大小的修正,最后对检测结果进行NMS,输出最终检测结果
SPPNET:
SPP指的是金字塔池化将各个候选框分别分成4*4,2*2,1*1,改进点1:对图像先经过cnn卷积在提取roi区域,改进点2:空间金字塔池化放置在全连接层之前
Fast R-CNN:
改进1:使用ROI区域池化代替全局金字塔池化。ROI池化对roi区域只进行了一次池化的操作
改进2:使用全连接层代替之前的svm分类器和线性回归器进行物体分类和边框回归修正,使cnn构成一个整体,增加检测任务的一体性。
Faster R-CNN:
改进点:使用RPN(region proposal network)代替ss,并且rpn与检测的fast r-cnn共享特征提取部分的权值.一副图像先由RPN提取候选区,再取出各个候选区的特征图,送入Faster r-cnn(独立于RPN的后半部分)进行物体分类和位置回归
roipool:将proposal输出为固定大小,将M*N尺度下proposal尺度改为M/16*N/16,再将proposal区域特征图固定为7*7输出。
roiALign:使用二次线性插值,精确化输出
损失函数:
选用smooth L1 loss的好处:使边框回归时,初期网络训练时,梯度
网络细节:
2.yolo、yolov2、yolo9000、yolov3:
yolo:
将图片划分为s*s的方格,对每个位于该方格内的物体预测b个边界框(包括位置,宽高和置信度),网络参考googlenet,由24个卷积层和2个全连接层
yolov2:
针对yolo两个缺点,即低召回率和低定位准确率进行改进。
改进点1:卷积层后增加BN,加快收敛速度,防止过拟合
改进点2:使用finetune10个batch,使模型提取适应高分辨率图像
改进点3:使用k-means算法进行聚类获取先验锚框,距离定义为1-IOU()
改进点4:使用anchor-base ,预测偏移量和置信度
改进点5:输入图像尺寸由448改为416,经过卷积后变成13的特征图,长宽是奇数,有效识别中心
改进点6:将26的特征图变为13特征图与池化后的13特征结合,提高对小物体检测的精度
改进点7:每隔10个批次改变输入图片大小,增加模型鲁棒性
改进点8:使用Darknet19代替Vgg16(效果好,单参数多,运行缓慢)
YOLO9000:
使用分类数据集和检测数据集联合训练,构建字典树
Yolov3:
改进点1:由于部分目标的语义重叠,使用二元交叉熵损失函数替换softmax函数
改进点2:使用Darknet53提取特征,由于网络深,增加了shorcut结构,同时使用三个尺度的特征图进行训练
损失函数:xy 置信度使用交叉熵损失函数,类别使用多元交叉熵损失,wh使用的是smoothl1
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
yolov4:
使用Mish损失函数,相比relu训练稳定性和最终精度有提高,但训练时间有增加
CBL换为CBM,增加SPP,使用CSPnet网络结构
使用Dropblock丢弃局部特征图
损失函数变为CIOU_LOSS,预测框筛选变为DIOU_loss
FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,v4包含两个Pan结构
yolov5:
改进点1:focus结构,使用切片结构,将像素点slice,contact然后再卷积
改进点2:在neck结构中,增加csp结构残差结构,增强网络特征融合的能力
改进点3:boundingbox 损失函数使用CIOU 和v4一致
改进点4:Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式(更好),而Yolov5中采用加权nms的方式
PPyolo:
改进点1:加了DCN卷积,将mAP提高到39.1%
改进点2:优化训练策略 选用的是更大的batch和EMA,并且加入DropBlock防止过拟合,mAP提升到了41.4%
改进点3:IOU Loss,IOU Aware,Grid Sensitive
改进点4:检测框的处理部分也是能提升性能的,通过增加Matrix NMS
改进点5:将SPP和CoordConv(添加了两个通道,一个表征i坐标,一个表征j坐标。这两个通道带有坐标信息,从而允许网络学习完全平移不变性和变化 平移相关度)放到这里再来考虑。这两个结构所带来的额外参数较少,而实验也证明了将mAP提高到44.3%
改进点6:在ImageNet上进行预训练得到了一个更好的预训练模型
3.SSD,cascade_rcnn,center_rcnn,retinaface:
SSD:该算法通过在不同的特征图上对不同尺寸的候选框进行回归,由于预测框特别的,所以计算最慢,同时最后输出进行NMS,损失函数使用 smoothl1 和多元交叉熵
cascade_rcnn:多个stage(fasterrcnn是twostage),每个satge训练使用上层stage的输出
focal loss:解决样本不平衡,提高难分样本的关注度
center_rcnn: heatmap使用focalloss,中心点偏移和长宽预测值使用L1损失
NMs 和 iou代码:yolov3对同一类别进行nms
4.多目标跟踪:centertrack,deepsort,Fairmot,jde
jde:使用FPN结构每一层都有一个预测头,预测头除了分类和定位,还包括一个embedding分支,之后还是要经过卡尔曼滤波和匈牙利算法进行匹配,所以还是two-stage
Fairmot关联算法:多个trac并行执行卡尔曼滤波;一个track只使用一个特征向量(滑动平均),特征提取采用anchor-free
centertrack:输入增加了前一帧图和heatmap,对增加两部分分别进行卷积之后,按位相加,同时输出置信度和displacement,heatmap和wh
deepsort可改进点:1.embding可以和检测网络融合(jde)2.级联匹配不仅跟时间相关,也得考虑轨迹的评分 3.用预测来弥补漏检 4.马氏距离的运动系数为0,相机运动没有考虑
















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









