







cityscapes分割benchmark
https://www.cityscapes-dataset.com/benchmarks/
目前cityscapes排名靠前并且开源的算法有两个:HRNetV2 + OCR + SegFix和Hierarchical Multi-Scale Attention for Semantic Segmentation。
HRNetV2 + OCR
hrnet官方:https://github.com/HRNet/HRNet-Semantic-Segmentation
ocr官方:https://github.com/openseg-group/openseg.pytorch
mmseg官方:https://github.com/open-mmlab/mmsegmentation
详解参考:https://blog.csdn.net/weixin_42990464/article/details/108280647
HRNet:Deep High-Resolution Representation Learning for Visual Recognition
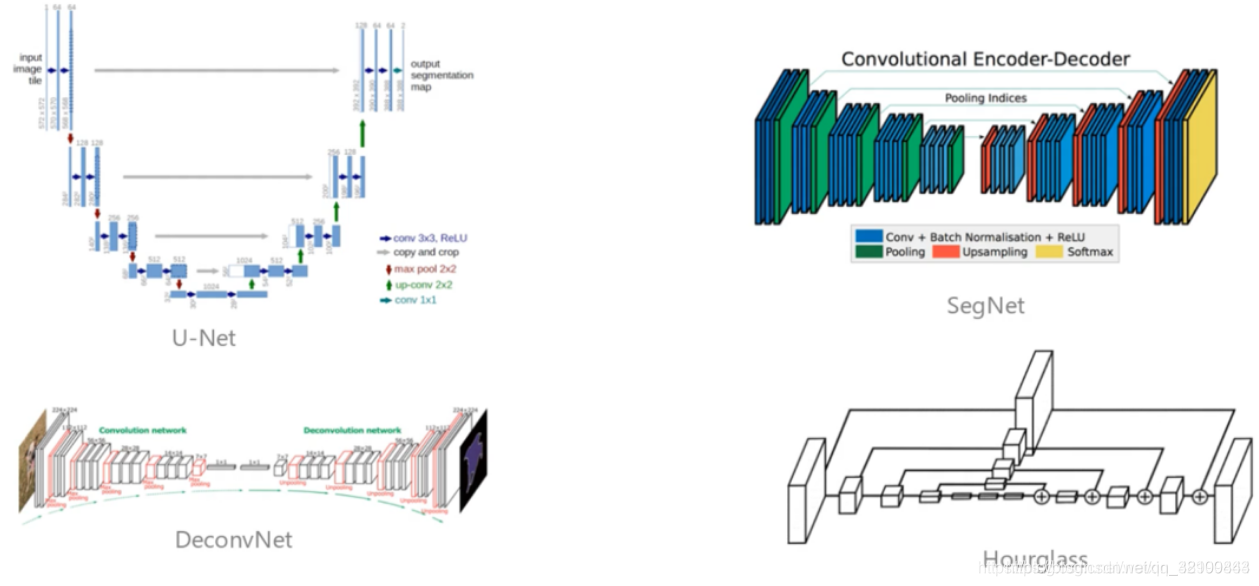
下图中的经典方法,看起来不同,但本质核心思路是差不多的。这些方法存在一个缺点,分辨率由高到低会损失信息。
为了解决这个问题,团队提出了一个方法,核心思路是 “不恢复 到高分辨率,而是保持分辨率” 。具体图示如下,把不同分辨率的 feature map 并联,各个分辨率分别一路,“保持”信息。但是,这样仍有一个问题,就是 feature map 彼此之间没有交互。
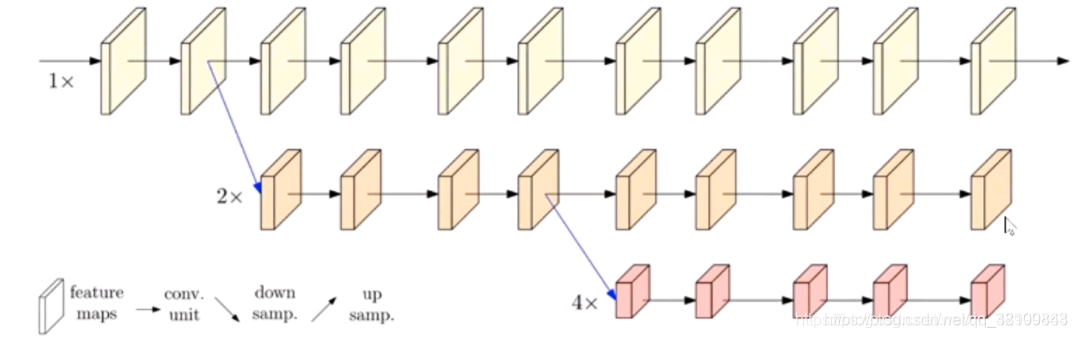
为此,团队又给网络添加了一些内容,如下图红线所示,各路之间不断进行 repeated fusions。
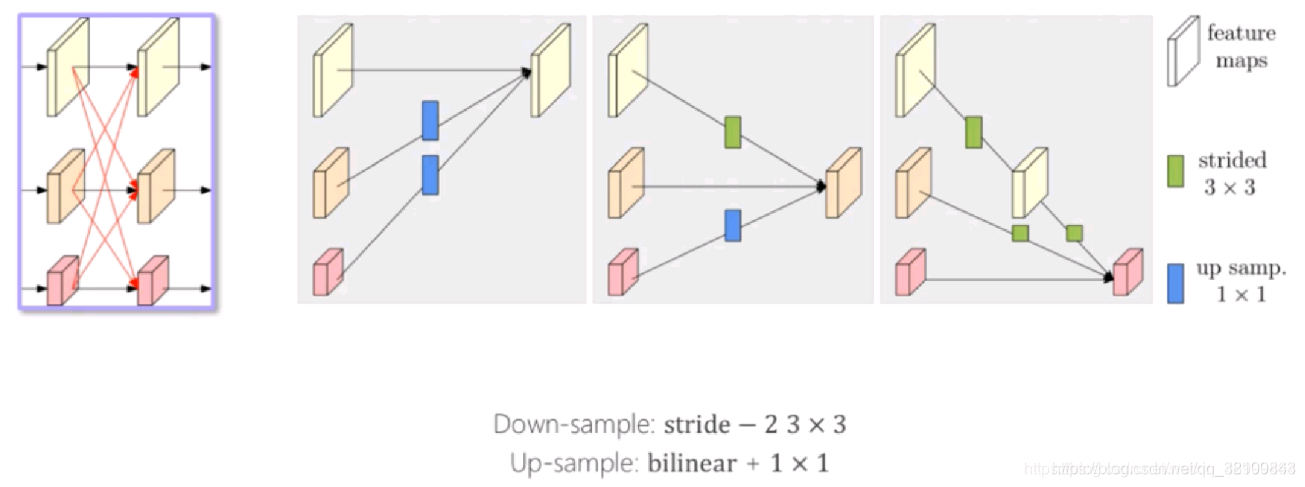
交互的方式如下:上采样时,先双线性插值,然后用1x1的卷积处理;下采样时,采用步长为2,尺寸为3x3的卷积处理。
OCR:Object-Contextual Representations for Semantic Segmentation
论文:https://arxiv.org/pdf/1909.11065.pdf
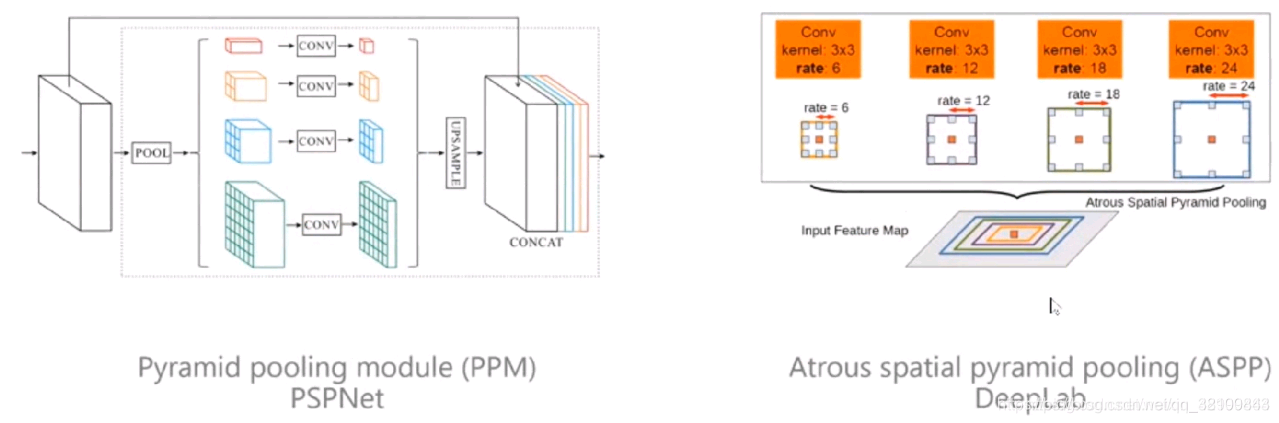
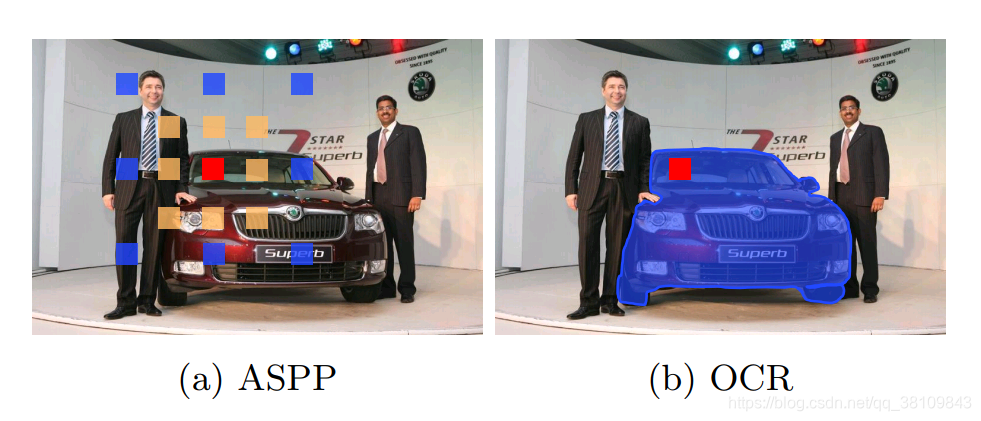
当前的FCN没有解决好物体上下文信息。因为单独看一个象素,很难知道这个象素是属于某一个物体的,因为象素给我们的信息是RGB的信息,如果不给予足够多的上下文信息是很难判断的。下图列举了商汤的PSPNet和谷歌的ASPP。PSPNet通过给每个象素周围建立多尺度的表征获取上下文信息,当时这个方法取得了非常大的突破。同时谷歌的ASPP也用了类似于空洞卷积的方式来实现上下文信息获取。
当前方法分析上下文信息如下图所示,比如说红色点是我们关注的点,周围绿色几个点是采样出来的,可以看到,绿色点分为两部分,一部分是属于车的,还有一部分是属于背景的。

我们找这个物体,要通过周围物体的象素表征来帮助。因此,我们需要把红色像素周围属于 object 的pixel取出来做为上下文,如下图所示:

具体如何做呢?首先用一个 baseline network 得到一个粗略的分割结果(黄色框中左半部分),同时,还会输出全图的 feature map。分割结果包括K类,我们把每个类别的特征提出来(黄色框中上半部分的特征),如下图所示:
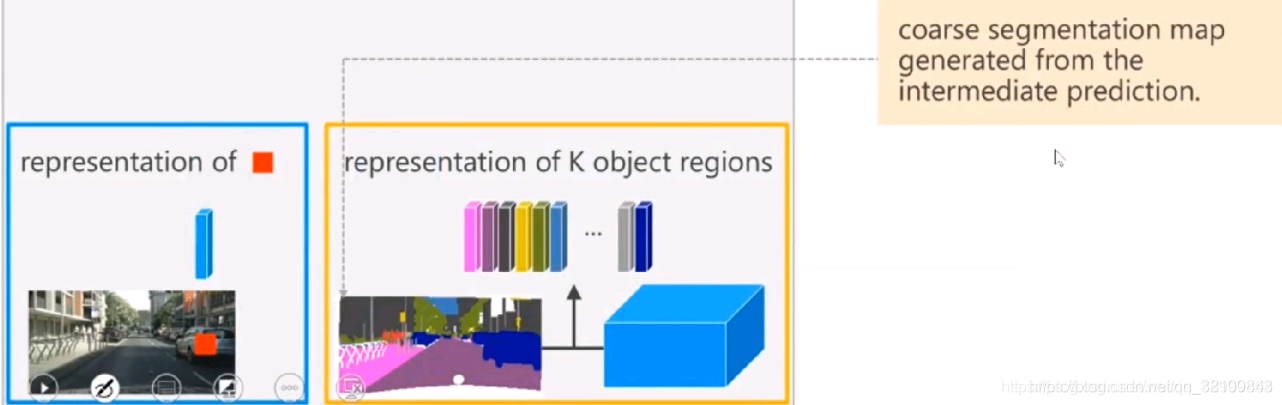
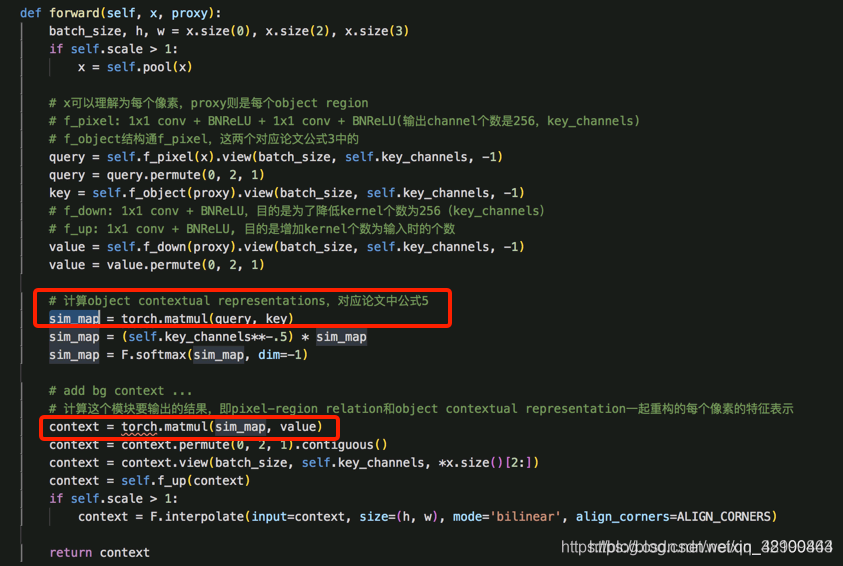
然后, 把红色小方块的的特征经过变换,右边K个区域的特征也经过一个变换,然后计算一下相似度,如下图所示。相似度计算以后,就可以得到红色小方块属于各个类别的可能性。我们根据这个可能性把每个区域的表征进行加权,会得到当前像素增强的特征表示(object-contextual representation)。

ocr整体流程:
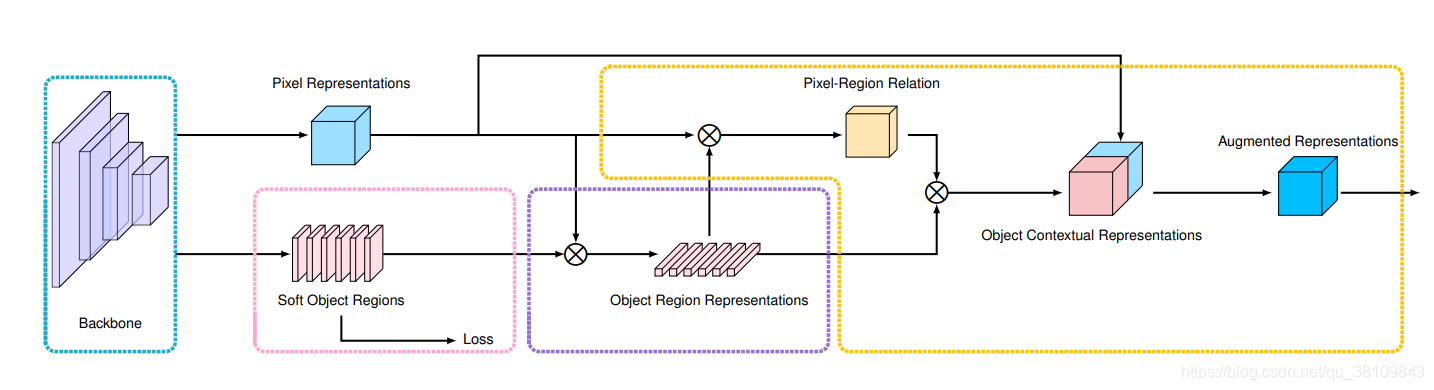
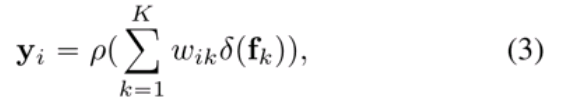
step1: 计算一个coarse的segmentation结果,即文中说的soft object region
实现过程:从backbone(ResNet或HRNet)最后的输出的FM,再接上一组conv操作,然后计算cross-entropy loss
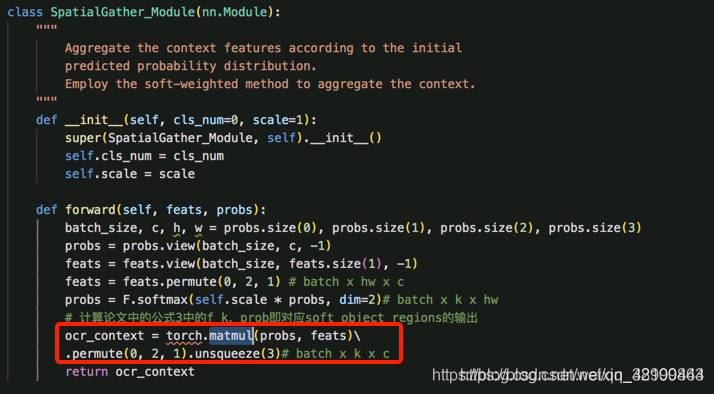
step2: 结合图像中的所有像素计算每个object region representation,即公式中的fk
实现过程:对上一步计算的soft object region求softmax,得到每个像素的类别信息,然后再和原始的pixel representation相乘
step3: 利用object region representation和原始的pixel representation计算得到pixel-region relation,即得到公式中的wik
实现过程:将object region representation和pixel representation矩阵相乘,再求softmax
step4: 计算最终每个像素的特征表示
实现过程:将step3的结果object region representation矩阵相乘,得到带有权重的每个像素的特征表示,并和原始的pixel representation连接到一起

SegFix: Model-Agnostic Boundary Refinement for Segmentation
论文:https://arxiv.org/pdf/2007.04269.pdf
详解参考: https://www.yuque.com/lart/papers/nfkhhz
官方SegFix代码:https://github.com/openseg-group/openseg.pytorch
出发点:
这里的后处理的出发点也很直接,考虑到了分割任务中的难样本的处理,即边缘附近像素的预测结果的优化。边缘附近的预测是大多数深度学习分割方法的共有的痛点之一。文章也简单统计了几个主流模型的误差像素的位置分布。

核心思路:
本文的方法概括起来很简单,就是让边缘区域的像素的预测结果,直接使用其相同类别区域内部像素的预测(因为区域内部的预测一般都很准确)。
所以首要的问题在于:
1.如何确定边缘像素?
2.如何关联边缘像素与内部像素?
这里主要借助于一个边缘预测分支和一个方向预测分支来完成,在获得良好的边界和方向预测之后,就可以直接拿来优化现有方法预测的分割图了。
主体结构:
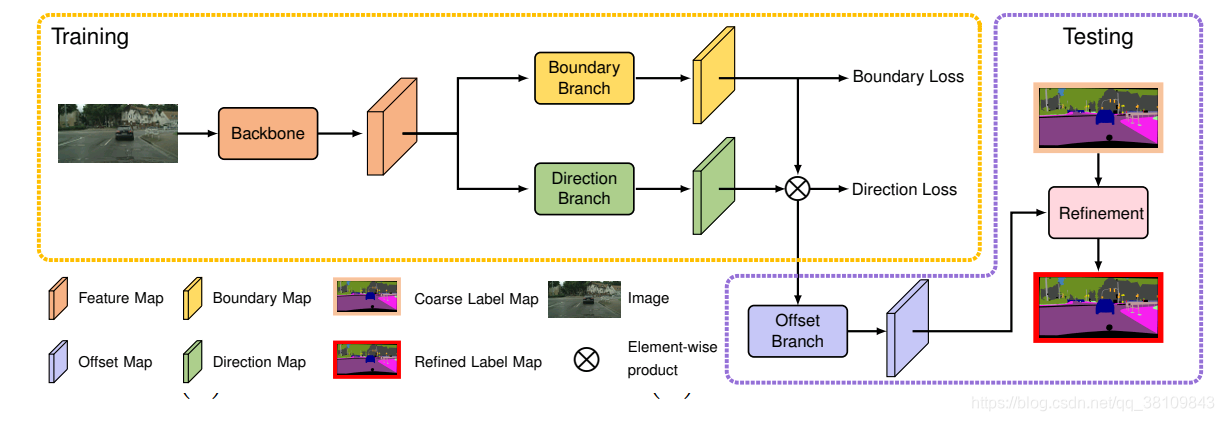
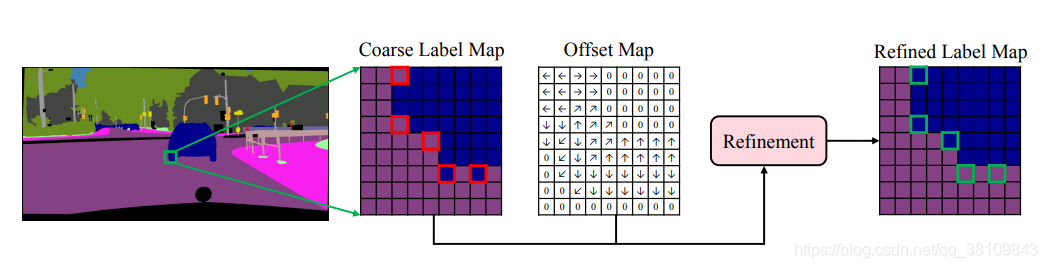
所以另一个问题在于,如何将现有的针对边缘的关联方向的预测应用到实际的预测优化上,这主要借助于一个坐标偏移分支。
获取真值过程:
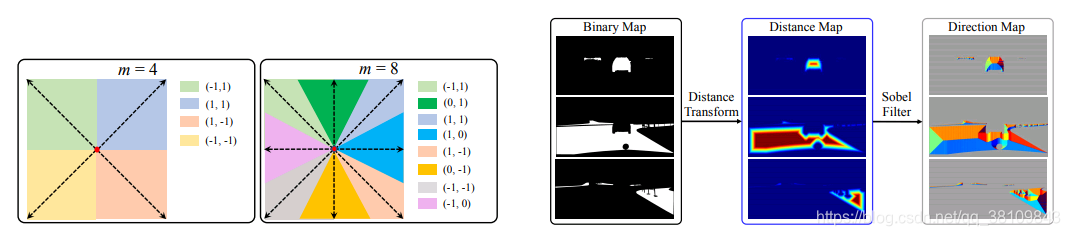
1.都由分割任务的mask来生成(语义分割、实例分割都是如此)
2.需要先生成distance map,再在此基础上生成boundary map和direction map,对于每个像素而言,distance map上都记录了它相距于属于其他类别像素的最小欧式距离,这实际上也表示了像素到边界的距离。
3.首先将真值mask分解成K个binary map (0 or 1),每个map关联着不同的类别(语义类别、实例类别),K表示图像中包含的类别数量。之后在每个binary map上独立计算distance map,这里使用了scipy的函数scipy.ndimage.morphology.distance_transform_edt() 。这个函数用于距离转换,计算图像中非零点到最近背景点(即0)的距离。它被用在每个类别独立的binary mask上,正好计算的就是相距于其他类别(每个binary mask上的0表示的就是“其他类别”)的最小欧氏距离。
4.计算完各个mask之后,我们可以计算一个融合的distance map来实现对于所有的K个distance map的集成
5.boundary map:使用融合后的distance map,对其使用一个预设的阈值进行划分,小于阈值的作为边界区域的像素,大于阈值的认为在特定目标区域内部。因为距离值越小,说明越接近边界
6.direction map:这里在未合并的K层distance map上,分别使用9x9的Sobel滤波器。基于Sobel滤波器的方向是在[0~360°]内,并且每个像素位置的方向都指向邻域内部距离目标边界最远的像素,整个方向范围被均匀划分(量化)成了m类,然后每个像素的方向被赋值成对应的方向类别。
坐标偏移:
Hierarchical Multi-Scale Attention for Semantic Segmentation
论文:https://arxiv.org/pdf/2005.10821.pdf
官方代码:https://github.com/NVIDIA/semantic-segmentation
详解参考:https://blog.csdn.net/m0_47645778/article/details/106279016
语义分割任务就是对每个像素进行分类。在这个任务中有一个权衡,某些类别的预测在较低的推理分辨率下处理得最好,而其他任务在较高的推理分辨率下处理得更好。精细的细节,比如物体的边缘或薄的结构,通常可以通过放大图像尺寸来更好地预测。与此同时,对于需要更多全局背景的大型结构的预测,通常在缩小图像尺寸时做得更好,因为网络的感受野可以观察到更多必要的背景。我们把后一个问题称为类别混淆。下图给出了这两种情况的示例。
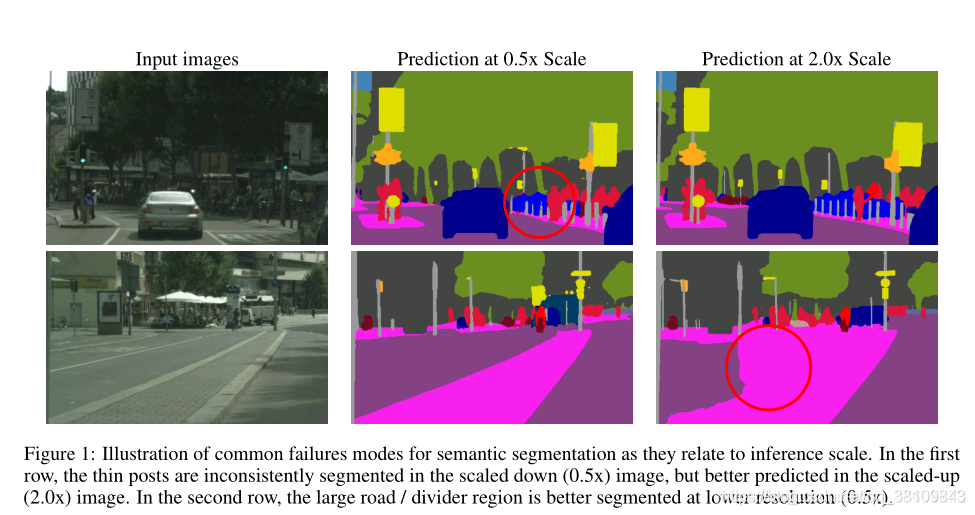
使用多尺度推断是解决这种权衡的常见做法。使用一定范围内的尺度进行预测,结果可以通过平均池化或最大池化来进行。使用平均结合多个尺度通常可以提高结果,但会有将最好的预测与较差的预测结合起来的问题。比如说,如果对于某个给定的像素,最好的预测结果来自于2x scale,一个相比差很多的预测结果来自于0.5X scale,然后对这两个结果进行取平均,这样最优的结果可能就是对不同尺度进行不同权重的结合。
为了解决这个问题,本文提出一种attention机制来预测如何结合不同尺度的预测结果。本文提出一种多层级的attention机制,通过让网络来学习一个相邻尺度之间的相关权重,由于分层级的属性,在训练的pipeline中只增加了一个额外的尺度。而且,本文提出的多层级机制也会提供在预测时选择额外scale尺度作为对比的灵活性。
SOLO
论文:https://arxiv.org/abs/1912.04488
代码:https://github.com/WXinlong/SOLO
解析:https://blog.csdn.net/sanshibayuan/article/details/103895058
SOLOv2
论文:https://arxiv.org/abs/2003.10152
代码:https://github.com/WXinlong/SOLO
解析:https://zhuanlan.zhihu.com/p/120263670
Panoptic FCN
论文:https://arxiv.org/abs/2012.00720
代码:https://github.com/ywcmaike/PanopticFCN
解析:https://zhuanlan.zhihu.com/p/360354321
K-Net
论文:https://arxiv.org/pdf/2106.14855.pdf
代码:https://github.com/ZwwWayne/K-Net/
解析:https://blog.csdn.net/weixin_47196664/article/details/118644126

















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









