







树莓派学习之旅(2)— 使用USB声卡进行录音
一、USB声卡的接入
在插入USB声卡之前,我们使用 lsusb命令查看一下USB设备:

然后把USB声卡插上,再使用lsusb查看一下,可以看到,多出来的那个就是USB声卡:

然后使用arecord -l可以列出所有录音设备,可以看到,我们的USB声卡设备

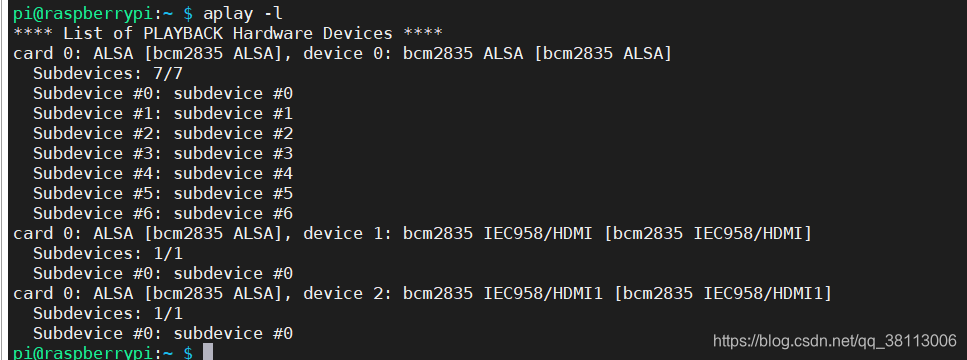
而使用aplay -l可以列出所有播放设备
参考自:https://segmentfault.com/a/1190000013854294
二、USB声卡的使用
直接执行Linux自带的录音命令,录制一段5秒的声音进行测试
arecord -D "plughw:1,0" -f S16_LE -r 16000 -d 5 -t wav test.wav
其中 hw:1,0 表示card 1 , device 0,即我们的USB声卡,arecord 其他的参数如下:
| 指令 | 含义 | 本指令含义 |
|---|---|---|
| -D | 选择设备名称 | 使用外接USB声卡"plughw:1,0" |
| -f | 录音格式 | S16_LE代表有符号16位小端序 |
| -r | 采样率 | 16000是16KHz采样 |
| -d | 录音时长 | 录音5秒 |
| -t | 录音格式 | wav格式 |
| test.wav | 文件名,可以包含路径 | 文件名字叫test.wav |
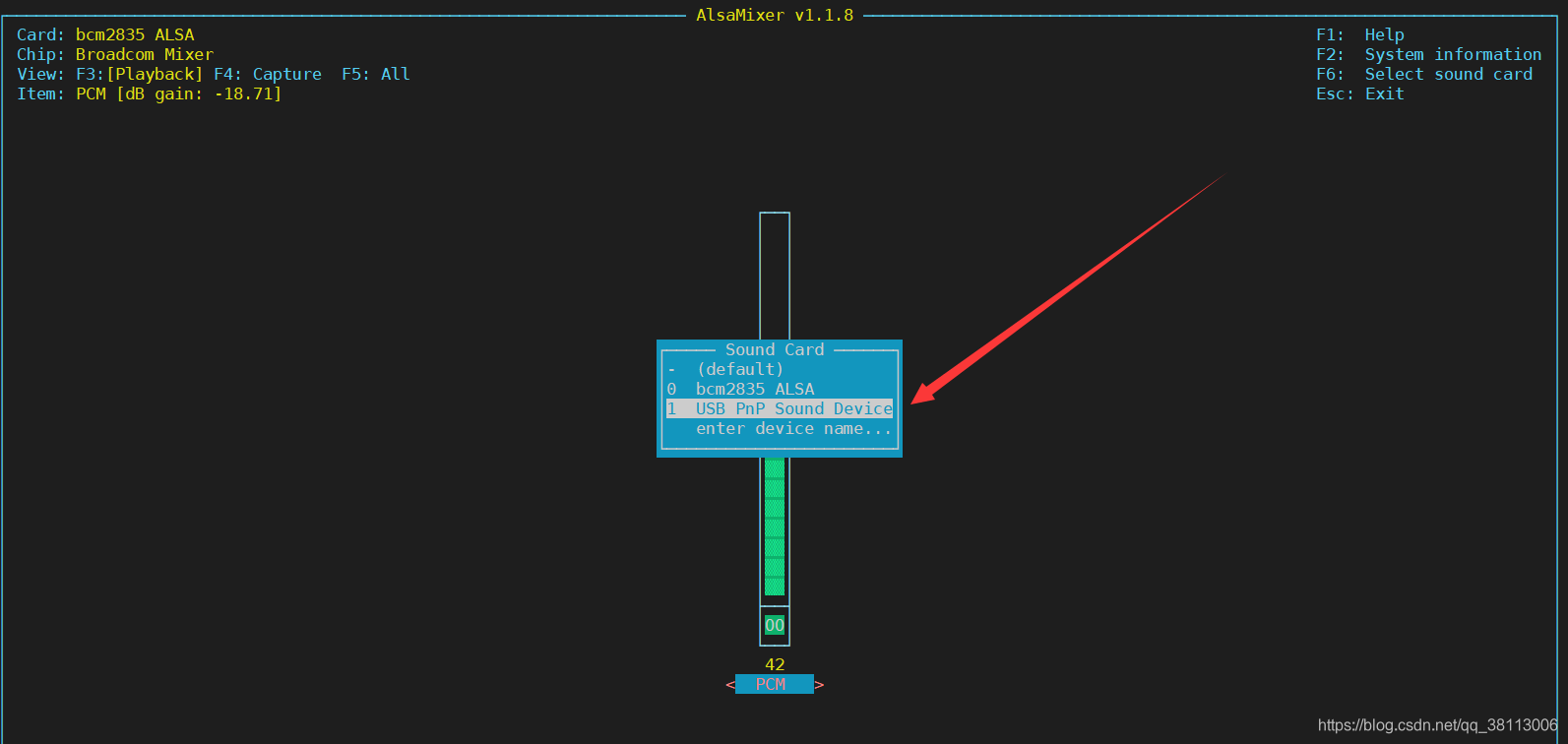
如果声音过小,输入命令 alsamixer,来对音量进行调整,按下F6,选择USB声卡,
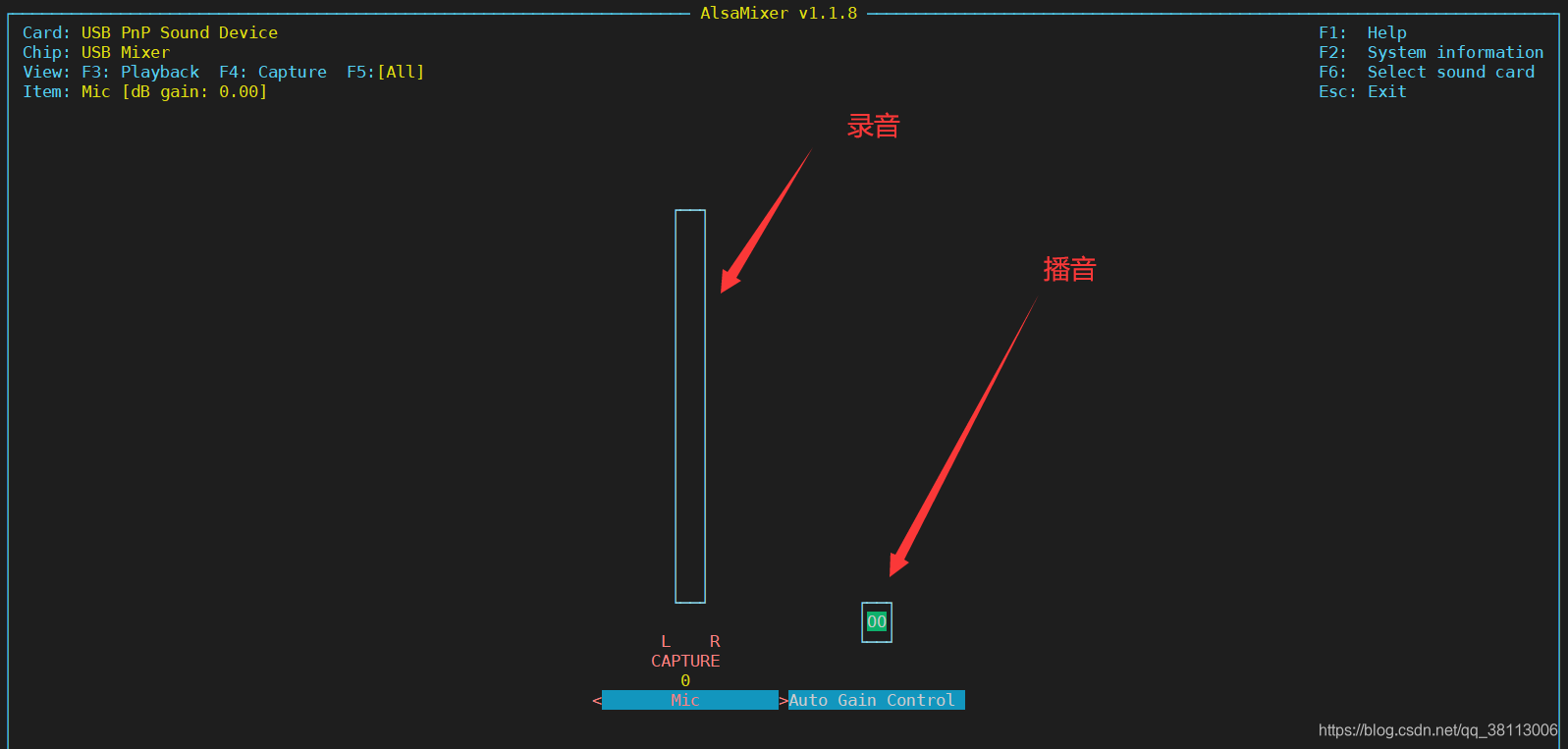
然后按下F5,将录音和播音设备都展示出来,因为我的USB声卡只支持录音,所以播音的音量无法调整,我们将录音的音量按上键调高
然后使用aplay命令来播放
aplay -D "plughw:0,0" test.wav
如果录音有问题,可能是缺少一些录音软件
sudo apt-get install alsa-utils ulseaudio
三、PyAudio安装即配置
如果没有安装pip3,使用如下命令安装
sudo apt-get install python3-pip
需要安装一些依赖库:
sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0 pulseaudio
sudo apt-get install libatlas-base-dev alsa-utils alsa-tools alsa-tools-gui alsamixergui -y
然后我们指定清华的源进行安装pyaudio,如果想要长期换源,可以参考:https://blog.csdn.net/qq_38113006/article/details/103541595#t7
pip3 install pyaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
在使用时我们需要配置默认使用的声卡,在$HOME下新建.asoundrc,

然后输入以下内容,其中,hw:1,0表示card 1 device 0,即我们的USB声卡
pcm.!default {
type asym
playback.pcm {
type plug
slave.pcm "plughw:0,0"
}
capture.pcm {
type plug
slave.pcm "plughw:1,0"
}
参考自:树莓派使用USB声卡设置
四、使用Pyaudio录音
参考我的Python博客:https://blog.csdn.net/qq_38113006/article/details/105694458#t3 编写Pyaudio录音程序:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: William
#使用pyaudio实现录音
import pyaudio,wave,sys
from tqdm import tqdm
TIME = 5 #录音时间
# 如果没有参数,就将输出文件设置为'01.wav'
if len(sys.argv) == 1:
file_name = "01.wav"
else:
file_name = sys.argv[1]
def main():
# 实例化一个PyAudio对象
pa = pyaudio.PyAudio()
# 打开声卡,设置 采样深度为16位、声道数为2、采样率为16K、输入、采样点缓存数量为2048
stream = pa.open(format=pyaudio.paInt16, channels=1, rate=16000, input=True, frames_per_buffer=2048)
# 新建一个列表,用来存储采样到的数据
record_buf = []
# 开始采样
for i in tqdm(range( 8 * 5 )): # 录音5秒
audio_data = stream.read(2048) # 读出声卡缓冲区的音频数据
record_buf.append(audio_data) # 将读出的音频数据追加到record_buf列表
wf = wave.open(file_name, 'wb') # 创建一个音频文件,名字为“01.wav"
wf.setnchannels(1) # 设置声道数为2
wf.setsampwidth(2) # 设置采样深度为2个字节,即16位
wf.setframerate(16000) # 设置采样率为16000
# 将数据写入创建的音频文件
wf.writeframes("".encode().join(record_buf))
# 写完后将文件关闭
wf.close()
# 停止声卡
stream.stop_stream()
# 关闭声卡
stream.close()
# 终止pyaudio
pa.terminate()
if __name__ == '__main__':
main()

















 3175
3175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









