







在实验室做的方向时是异构加速,基于FPGA加速CNN,用xilinx的hls和sdsoc环境,但是找工作方向这两开发环境真就没啥企业在用,所以就近学学cuda,gpu加速。为什么是先做矩阵乘法是基于做了挺长一段时间的CNN加速来考虑的 矩阵乘法是神经网络的核心所在 https://blog.csdn.net/lanchunhui/article/details/74838635 。
cpu计算矩阵乘法
首先考虑在CPU上计算矩阵乘法的过程就挺简单,代码如下,矩阵a[Rc][Wa] b[Wa][Cc]作为输入,通过矩阵乘法可以得到矩阵c[Rc][Cc]。也就是矩阵c的元素(i,j)由向量a(i,0:Wa)和向量b(0:wa,j)的转置做点积之后得到。
#define Wa 2048
#define Rc 1024
#define Cc 1024
// A[Rc][Wa]*B[Wa][Cc] = C[Rc][Cc]void matrix_mutiply_cpu(float *a,float*b, float*c)
{
for (size_t i = 0; i < Rc; i++)
{
for (size_t j = 0; j < Cc; j++)
{
c[i*Cc + j] = 0;
for (size_t k = 0; k < Wa; k++)
{
c[i*Cc + j] += a[i*Wa + k] * b[k*Cc + j];
}
}
}
}写了一个时延测试类,可以循环跑个几次然后测试平均时间这样稍微更好一点,并简单测试了一下cpu(i7-3770 3.4Ghz)计算矩阵乘法的时间
class timer
{
public:
void start()
{
this->_start = clock();
}
void stop()
{
this->_duration += (clock() - this->_start);
this->_count++;
}
double get_avg_sec()
{
return this->_duration / (this->_count*CLOCKS_PER_SEC + 1.0);
}
private:
long _count = 0;
long _start = 0;
long _duration = 0;
};
![]()
时间是14.1394s
GPU计算矩阵乘法
比较简单的思路:
1 在GPU全局内存上申请a,b,c三个矩阵的空间
2 把输入矩阵a,b拷贝到GPU全局内存上去
3 gpu kernel读全局中的内存并且计算c
4 把c从gpu全局内存拷贝到主机内存中去
基于以上的思路可以写GPU kernel和测试程序(__global__表示可以被host调用,__device__的kernel则只能在gpu上调用)。
可以看到kernel中没有类似于cpu中的最外两层for循环,这是因为GPU中用多个线程来计算。grid参数设置GPU中的线程块数量,也就是有多少个block。dim3 block参数设置每个线程块中的线程数量。每个线程都会指向kernel,所以以下的kernel中策略是在GPU中申请Rc*Cc个线程,每个线程负责计算c中的一个元素。
这样的作法会计算效率会受到带宽的限制,分析:
ctc(compute to comunication) ratio = total ops/(total global mem access Bytes)
因为对于每个线程的CTC ratio都是一样的,所以ctc = 单个线程ops/单个线程访问全局内存则ctc = Wa*2 / (Wa*2*4) = 1/4 ( float :4 Bytes)含义:每一次计算,需要从外部读取4个字节的数字。
测试GPU全局内存:位宽 64 频率900MHz,即带宽为8*900 = 7.2GB/s。
total ops = Wa*2*Rc*Cc = 1024*1024*2*2048 = 4G。所以需要的内存访问量为4G/ctc = 16GB,计算能力受到带宽限制,理论需要时间 16GB/7.2GB = 2.22s

const int threads_num = 32;
dim3 grid(Rc / threads_num, Cc / threads_num);
dim3 block(threads_num, threads_num);
__global__ void kernel(float *dev_a,float *dev_b,float *dev_c)
{
size_t x = blockIdx.x * blockDim.x + threadIdx.x;
size_t y = blockIdx.y * blockDim.y + threadIdx.y;
size_t offset = x* blockDim.x*gridDim.x + y;
float ans = 0;
for (size_t k = 0; k < Wa; k++)
{
ans += dev_a[x*Wa + k] * dev_b[k*Cc + y];
}
dev_c[offset] = ans;
}
void matrix_mutiply_gpu(float *a, float*b, float*c)
{
float *dev_a;
float *dev_b;
float *dev_c;
cudaEvent_t start, stop;
float elapse_time;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
cudaMalloc((void**)&dev_a,Rc*Wa * sizeof(float));
cudaMalloc((void**)&dev_b, Wa*Cc * sizeof(float));
cudaMalloc((void**)&dev_c, Rc*Cc * sizeof(float));
cudaMemcpy(dev_a, a, Rc*Wa * sizeof(float),cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, Wa*Cc * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_c, c, Rc*Cc * sizeof(float), cudaMemcpyHostToDevice);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapse_time, start, stop);
cout << "gpu memcpy time:" << elapse_time << "ms" << endl;
cudaEventRecord(start, 0);
kernel<<<grid, block >>> (dev_a, dev_b, dev_c);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapse_time, start, stop);
cout << "gpu kernel time:" << elapse_time << "ms" << endl;
cudaEventRecord(start, 0);
cudaMemcpy(c, dev_c, Rc*Cc * sizeof(float), cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapse_time, start, stop);
cout << "memcopy back time:" << elapse_time << "ms" << endl;
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
cudaEventDestroy(start);
cudaEventDestroy(stop);
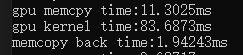
}运行代码,测试运行时间2.5s多,和理论值有点差距,可能是写地址耗费了一定的时间,写回计算结果矩阵c也占了一些内存。
![]()
GPU计算矩阵乘法-tile算法
之前的方法,每次计算一个元素就要读A的一行元素,B的一列元素,导致带宽成为算力的瓶颈。对矩阵计算过程分析,不难发现C中的每一行元素都只需要A中的固定一行,B也有相似的道理。在cuda中每个block有一块共享内存,block中的threads可以共享内存提高数据的利用率(矩阵C中每一个元素都由一个线程负责,也就是C中相邻的部分都会使用相同的一部分变量)。如下图中所示计算P中的子矩阵,需要N、M中的列和行(黄色部分)。
kernel 代码如下,将该kernel_tile替换上面函数matrix_mutiply_gpu中的kernel即测试函数。
const int threads_num = 32;
const int BLOCK_SIZE = threads_num;
__global__ void kernel_tile(float *dev_a, float *dev_b, float *dev_c)
{
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
size_t bx = blockIdx.x;
size_t by = blockIdx.y;
size_t tx = threadIdx.x;
size_t ty = threadIdx.y;
size_t Row = by*BLOCK_SIZE + ty;
size_t Col = bx*BLOCK_SIZE + tx;
//累加,得到行*列的值
float cSub = 0.0f;
for (size_t i = 0; i < Wa ; i+= BLOCK_SIZE)
{
As[ty][tx] = dev_a[Row*Wa + i +tx];
Bs[ty][tx] = dev_b[(i+ty)*Cc + Col];
__syncthreads();//计算之前要先同步,要等到block中每个线程都完成了读取的任务
for (size_t k = 0; k < BLOCK_SIZE; k++)
{
cSub += As[ty][k] * Bs[k][tx];
//cSub = b;
}
__syncthreads();//进入下一次之前要同步,避免下一次计算修改了共享内存中的数值
}
dev_c[Cc*Row + Col] = cSub;
}
BLOCK_SIZE = 32,则共享内存的大小为32*32*4 = 4096B < 49152B
ctc分析:对于每个block而言
计算量ops = BLOCK_SIZE*BLOCK_SIZE*2*Wa
访问全局内存量comunication = BLOCK_SIZE*Wa*2*4
ctc= BLOCK_SIZE/4 = 8 ,ctc率提升了32倍!数据利用率提升了。
总计算量还是一样的 total ops = Wa*2*Rc*Cc = 1024*1024*2*2048 = 4G,则需要的数据量d = ops/ctc = 0.5555GB
带宽7.2GB/S,则假如带宽是限制则 理论时间 = 0.5555/7.2 = 0.0771s
测试结果0.0836s,差距0.0065s,还算差不多吧,还是矩阵c的写操作也占用了一定的带宽
总结
gpu tile算法能够直接加速近100倍,还是很强的!GPU可以有非常多的线程,目前的矩阵加速效果都还是受到带宽的限制,GPU的算力瓶颈(最大并行度)该怎么算呢?















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









