







一、什么是反向传播?
通俗解释:
类比几个人站成一排,第一个人看一幅画(输入数据),描述给第二个人(隐层)……依此类推,到最后一个人(输出)的时候,画出来的画肯定不能看了(误差较大)。
反向传播就是:把画拿给最后一个人看(求取误差),然后最后一个人就会告诉前面的人下次描述时需要注意哪里(权值修正)
一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。
目的是更新神经元参数,而神经元参数正是 z=wx+b 中的 (w,b).对参数的更新,利用损失值loss对参数的导数, 并沿着负梯度方向进行更新。
“正向传播”求损失,“反向传播”回传误差
二、反向传播是如何工作的?
1.输入层接收x
2.使用权重w对输入进行建模
3**.每个隐藏层计算输出**,数据在输出层准备就绪
4.实际输出和期望输出之间的差异称为误差
5.返回隐藏层并调整权重,以便在以后的运行中减少此错误
这个过程一直重复,直到我们得到所需的输出。训练阶段在监督下完成。一旦模型稳定下来,就可以用于生产。
三、手推BP
实践:
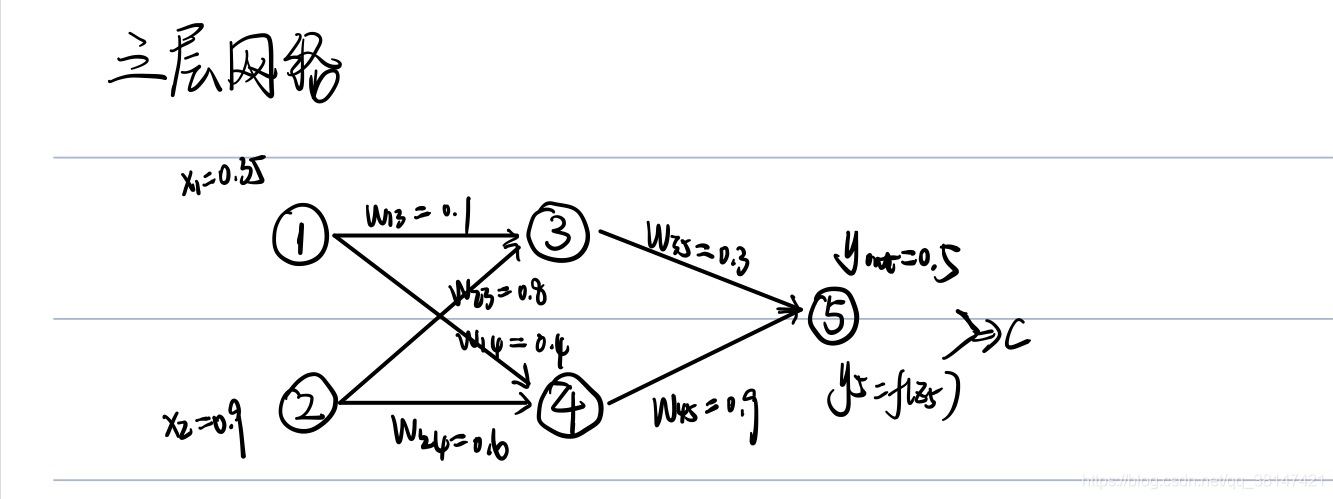

公式推导:



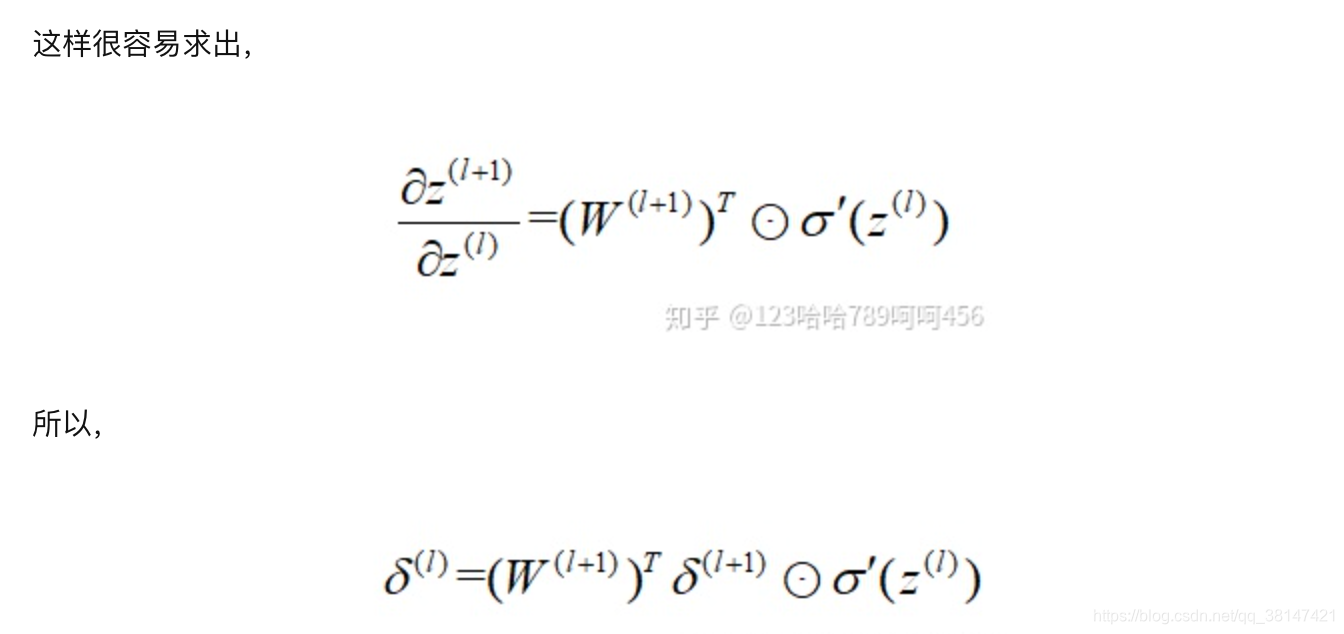

总结:


伪代码:















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









