







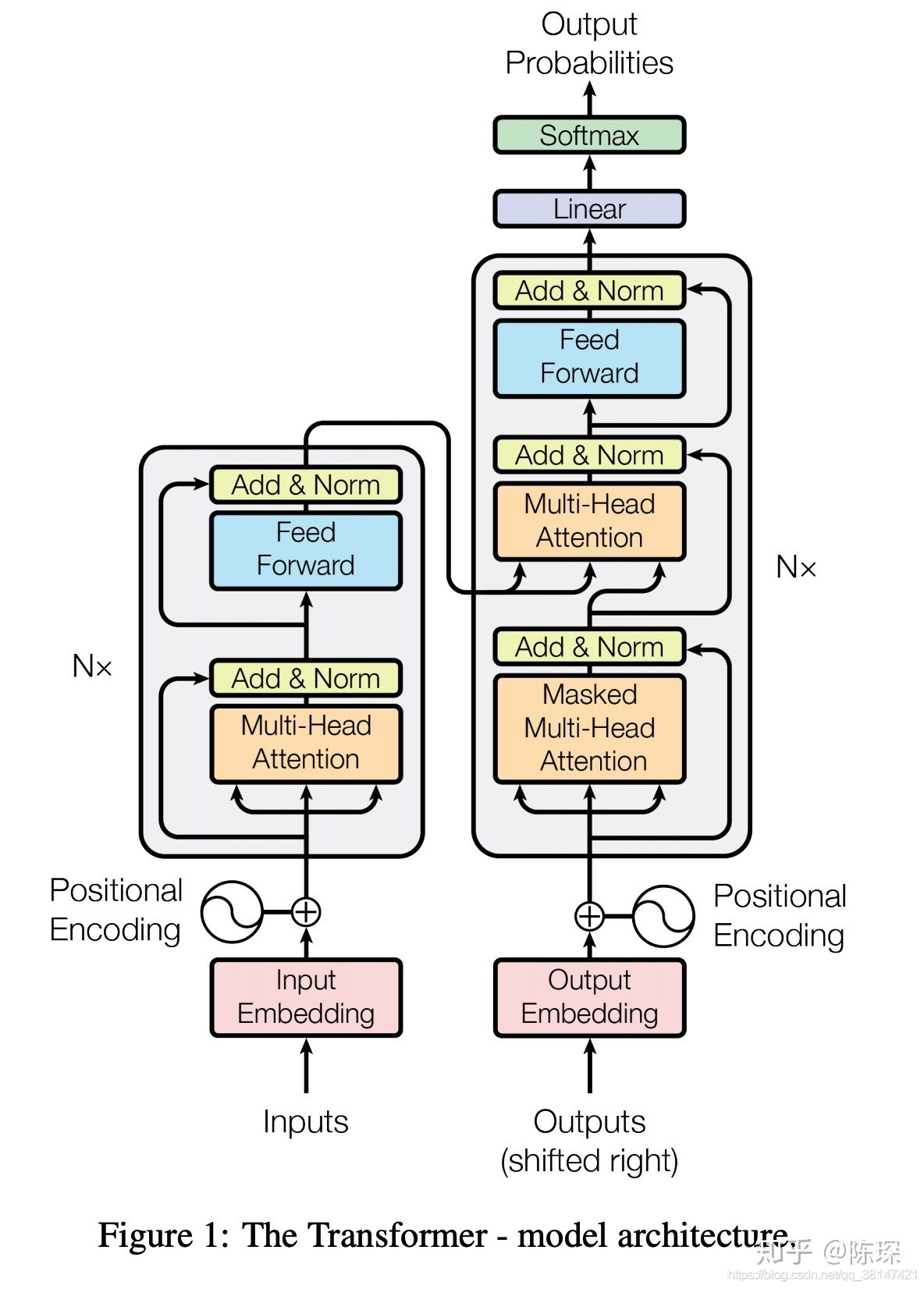
0 模型架构图
举例:中文输入为“我爱你”,通过 Transformer 翻译为 “I Love You”。
1、输入Inputs(图的左侧)部分和输出Outputs(图的右侧)部分
1.1 输入Inputs
1.1.1 Input Embedding
nn.Embedding 包含一个权重矩阵 W,对应的 shape 为 ( num_embeddings,embedding_dim )。num_embeddings 指的是词汇量,即想要翻译的 vocabulary 的长度。embedding_dim 指的是想用多长的 vector 来表达一个词,可以任意选择,比如64,128,256,512等。在 Transformer 论文中选择的是512(即 d_model =512)。
处理 nn.Embedding 权重矩阵有两种选择:
- 使用 pre-trained 的 embeddings 并固化,这种情况下实际就是一个 lookup table。
- 对其进行随机初始化(当然也可以选择 pre-trained 的结果),但设为 trainable。这样在 training 过程中不断地对 embeddings 进行改进。(Transformer √)

d_model = 512,具体实现时,embedding的输出除了经过Pytorch本身的nn.Embedding层,同时还与根号d_model 相乘,最后输出embedding。
1.1.2 Positional Encoding
Transformer 的作者提出了加入 ”positional encoding“ 的方法来解决这个问题。”positional encoding“ 使得 Transformer 可以衡量 word 位置有关的信息。
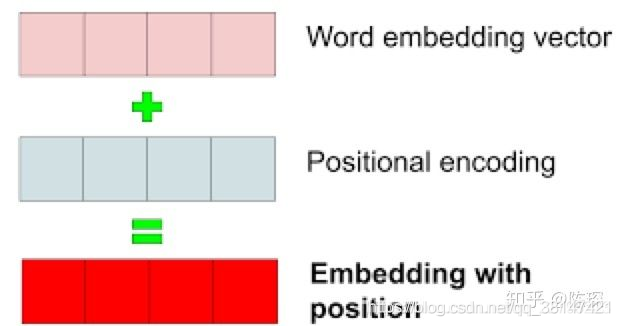
那么具体 ”positional encoding“ 怎么做?为什么能表达位置信息呢?作者探索了两种创建 positional encoding 的方法:
- 1、通过训练学习 positional encoding 向量。
- 2、使用公式来计算 positional encoding向量。(Transformer √)
试验后发现两种选择的结果是相似的,所以采用了第2种方法,优点是不需要训练参数,而且即使在训练集中没有出现过的 句子长度 上 也能用。
计算公式为(要记住):
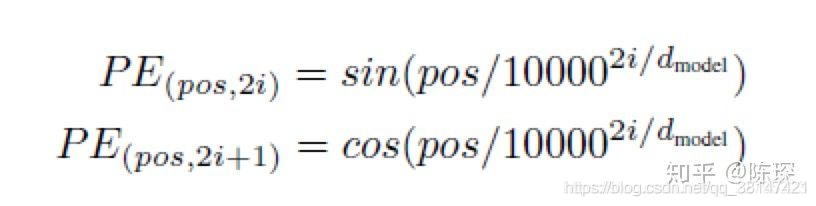
Transformer论文中的positional encoding为什么要使用三角函数来得到?
-
1、首先,需要明确的是,建模位置信息(无论是绝对位置还是相对位置)并不是必须用到三角函数,作者在这里使用正余弦函数,只是根据归纳偏置和一些经验作出的选择罢了。
-
2、具体得来的思路过程:
(1)若用最简单的位置编码计数,即PE = pos = 0,1,2,…,T-1作为每个字的编码。很容易受到数字大小的影响。
(2)在(1)基础上,考虑改进,使用归一化,但是这样的话,每个文本长度是不一样的,会导致位置编码的步长不一致。
(3)所以需要一个平滑的,周期的比较好,所以使用有界的周期性函数。但是光有三角函数,表达能力也是有限的,所以对于奇数偶数使用不同的三角函数,会让位置信息更加丰富,所以最后 有了transformer的位置编码公式。 -
3、至少现在看来:1. 这个函数形式很可能是基于经验得到的,并且应该有不少可以替代的方法;2. 谷歌后期的作品BERT已经换用位置嵌入(positional embedding)了,这可能说明编码的方案有一定的问题(猜测)
再看公式:
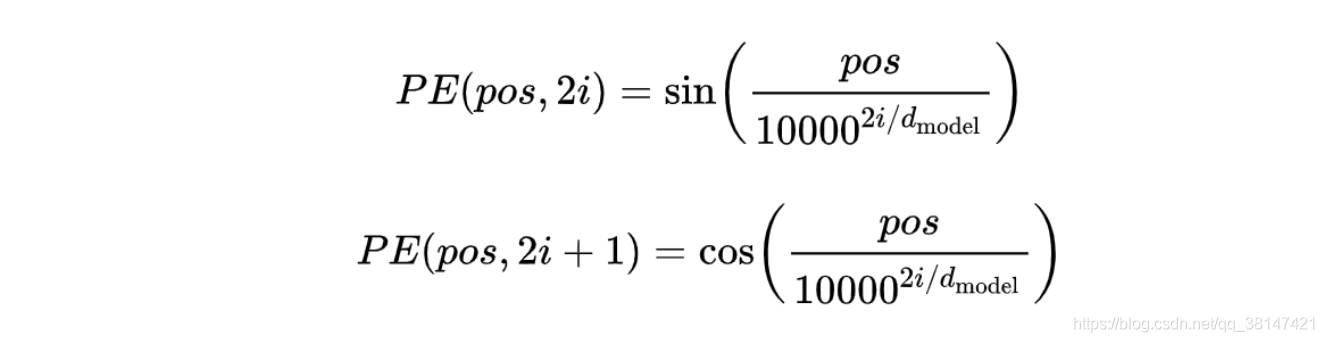
- pos 指的是这个 word 在这个句子中的位置。
- i指的是 embedding 维度。比如选择 d_model=512,那么i就从1数到512,只不过偶数维和奇数维使用不同的函数。
1.2 输出Outputs
Transformer模型中,decoder的第一个输入是什么?
- 一般而言,训练阶段的Transformer的Decoder的第一次输入为起始符 + Positional Encoding,也可能是其他特殊的Token,目的是为了预测目标序列的第一个单词是什么。


1.3、输入输出部分的小结
input部分:
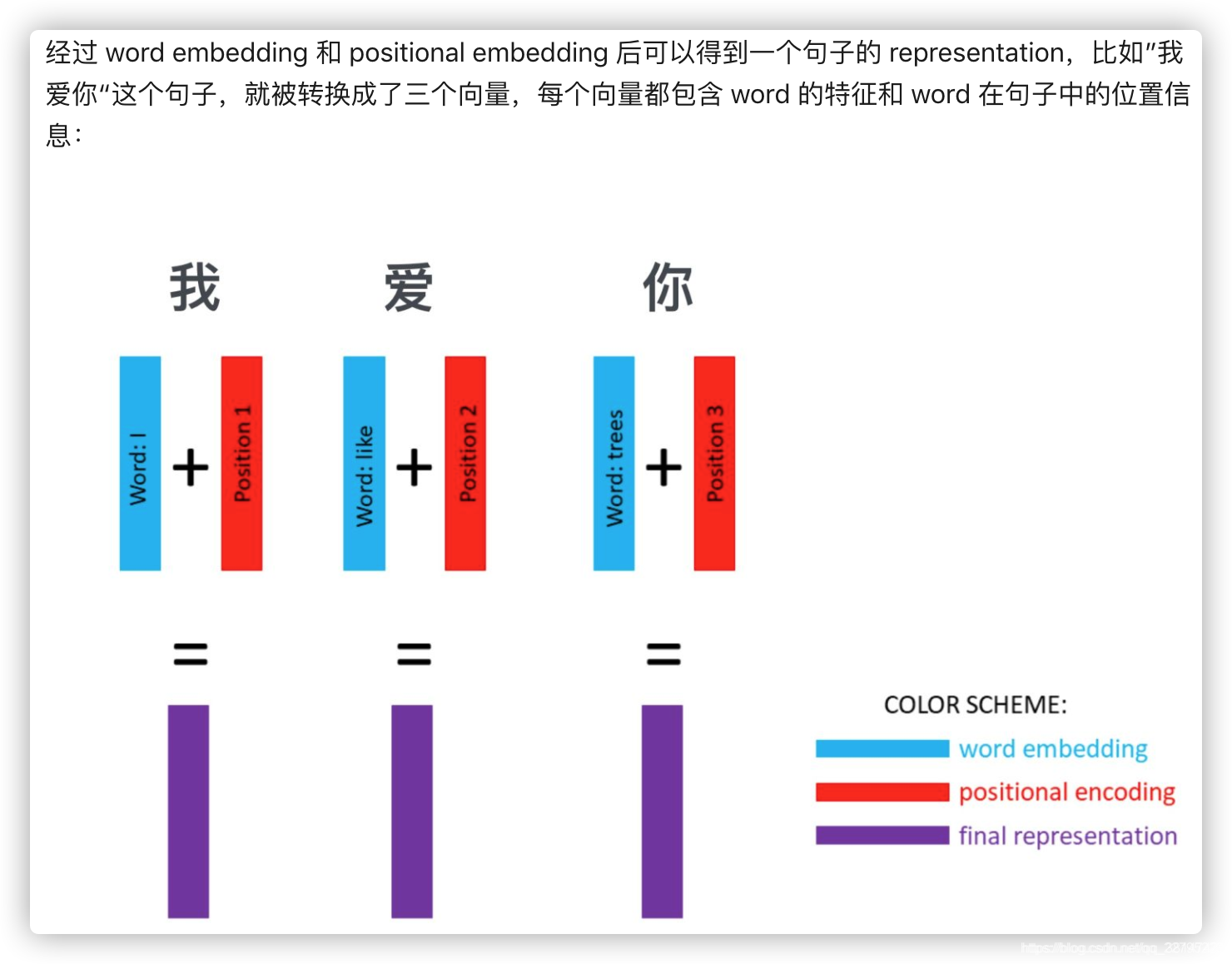
**Outputs(shifted right)**部分,也存在word embedding和positional encoding相加的过程,刚刚上述对此的分析已经很详细了,一定要知道预测/训练过程中,Outputs(shifted right)是如何参与进来的,文章的最后会给出更多预测/训练过程的细节解释。
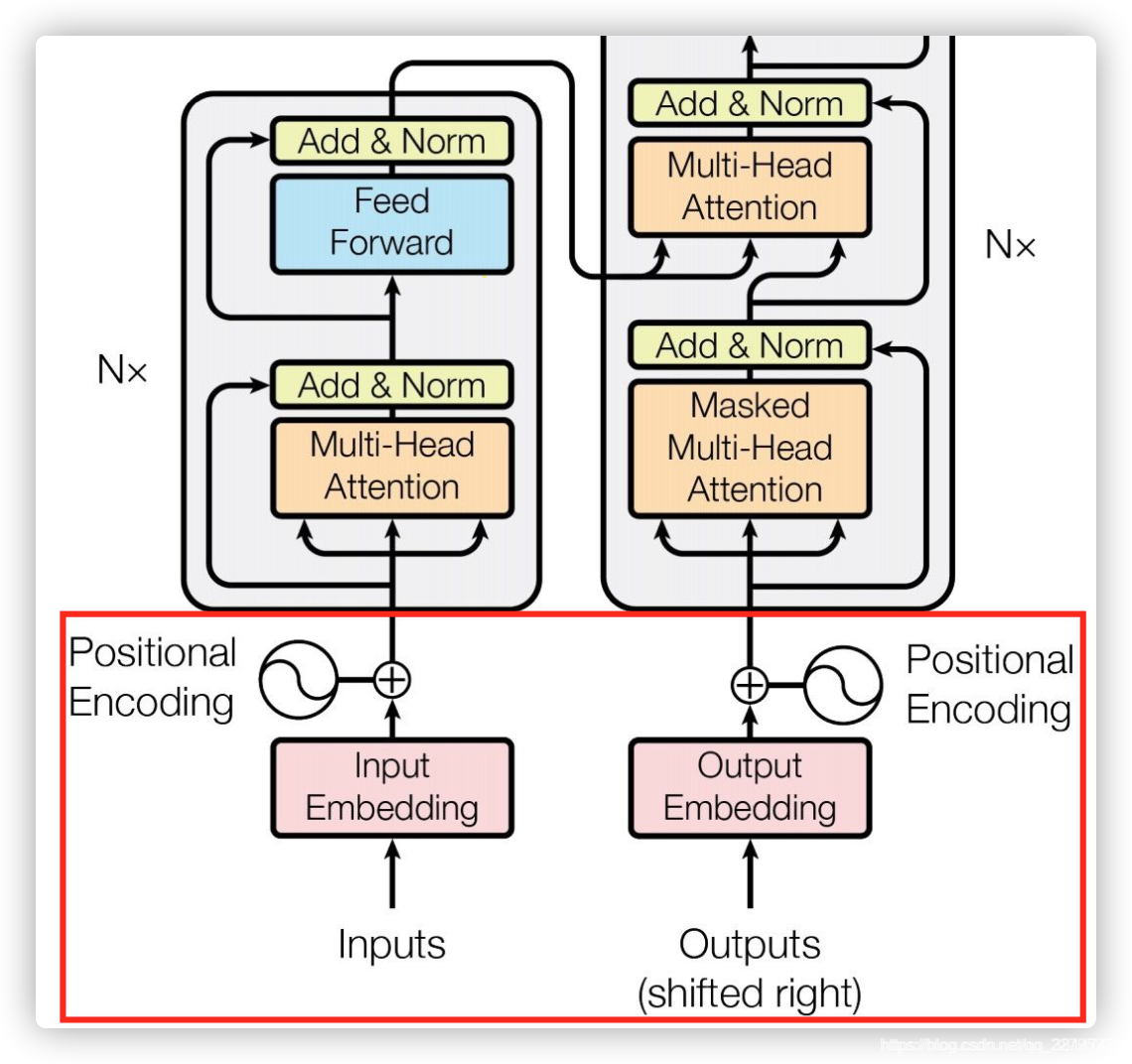
2、Encoder和Decoder部分
2.1 Encoder部分
Encoder 相对 Decoder 会稍微麻烦一些。 Encoder 由 6 个相乘的 Layer 堆叠而成(6并不是固定的,可以基于实际情况修改)。
每个Encoder Layer 包含 2 个 sub-layer:
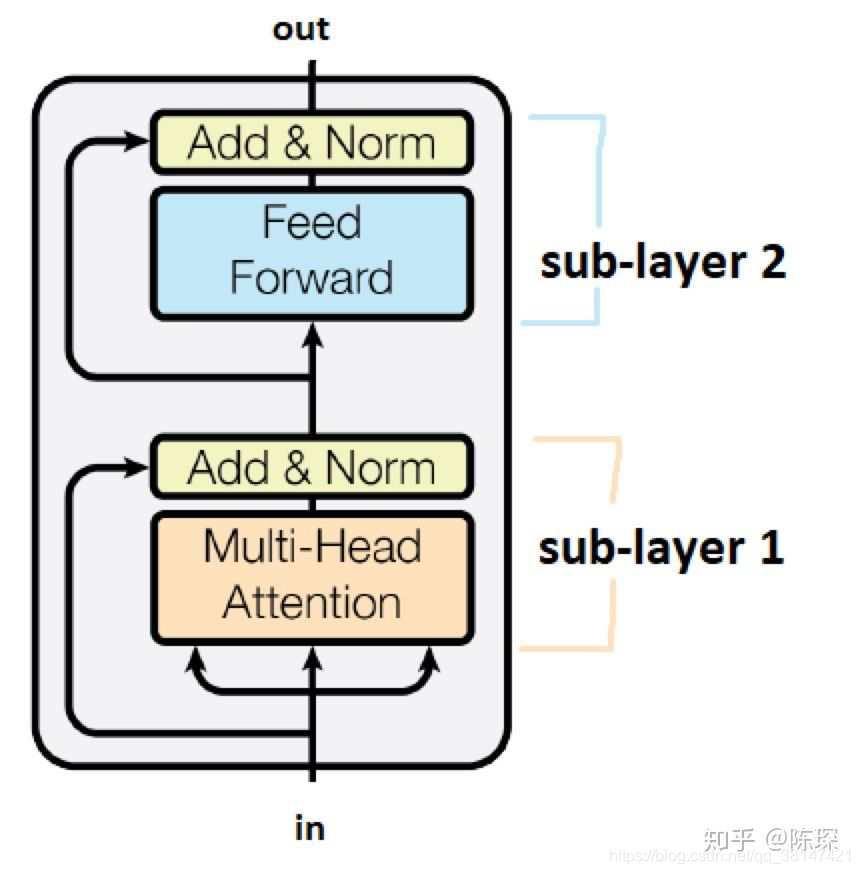
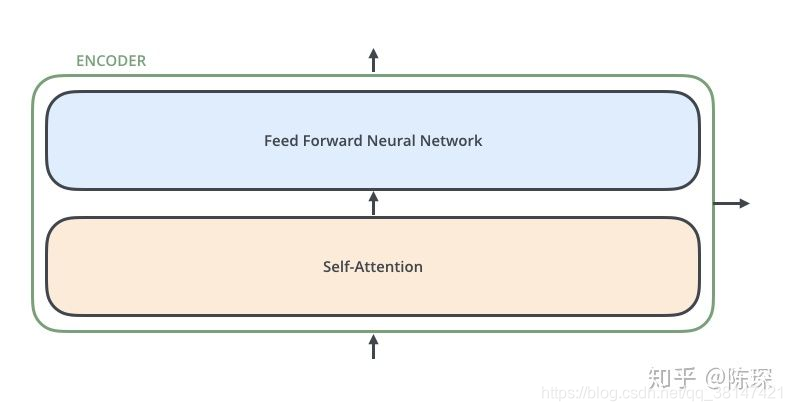
第一个是 multi-head self-attention mechanism(多头自注意力)
第二个是 simple,position-wise fully connected feed-forward network
2.1.1 Encoder Sub-layer 1: Multi-Head Attention Mechanism
理解 Multi-Head Attention 机制对于理解 Transformer 特别重要,并且在 Encoder 和 Decoder 中都有用到。
概述:
我们把该机制的输入定义为 x,x 在 Encoder 的不同位置,含义有所不同。在最开始的输入处(图中的in),x 的含义是final representation。在 EncoderLayer 的各层中间,x 代表前一层 EncoderLayer 的输出。
这里对MultiHeadedAttention实例化后的self_attn()输入三个同样x。
这里的x的shape为[nbatches, L, 512],那么query、key、value同样也是这样的shape。nbatches 对应 batch size,L 对应 sequence length ,512 对应 d_model。
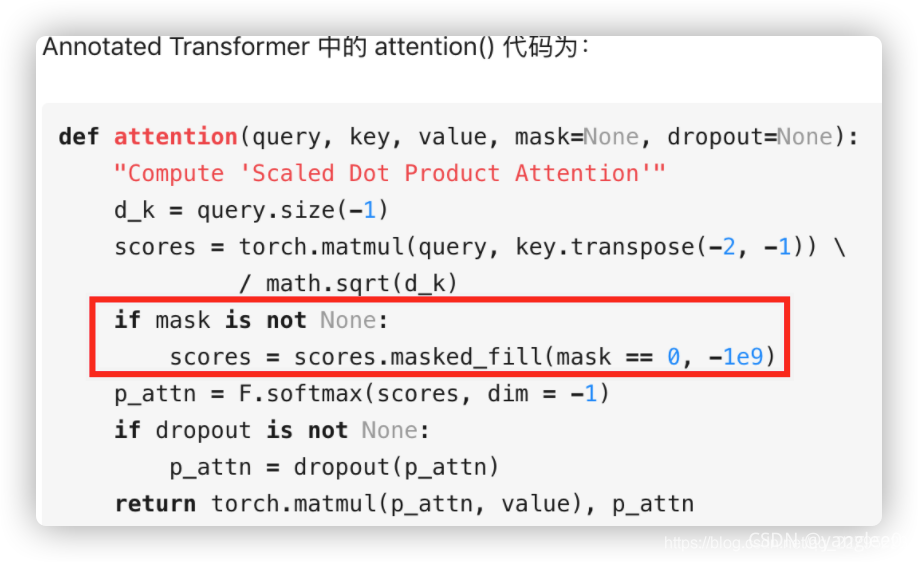
Step(1)对着MultiHeadedAttention实现代码来看步骤
- “query”,“key”和“value”经过线性层,他们的 shape 依然是[nbatches, L, 512]。
对其通过 view() 进行 reshape,shape 变成 [nbatches, L, 8, 64]。这里的h=8对应 heads 的数目,d_k=64 是 key 的维度。 - transpose 交换 dimension1和2,shape 变成 [nbatches, 8, L, 64]。
Step(2):attention函数具体为:
- 相当于在每个头里面的计算方法。
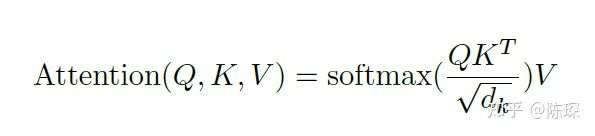
这里除根号dk是为了进行缩放,防止经过softmax进入了饱和状态。
Step(3):MultiHeadedAttention实现的源码
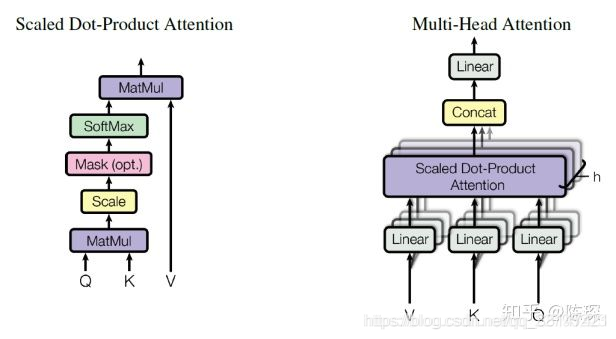
Encoder Sub-layer 1: Multi-Head Attention Mechanism的输入和输出的维度是一致的,输入的shape为[ nbatches, L, 512 ],各种变换后的输出的shape也为[ nbatches, L, 512 ]。
2.1.2 Encoder Sub-layer 2: Position-Wise fully connected feed-forward network
其实就是前馈神经网络。但激活层是relu函数。
从公式可以看出,x 经过 relu 和 线性层 输出为 FFN(x)。
而具体实现中,x 经过线性层 w_1,再经过 relu,再经过 dropout,最后再经过线性层 w_2,输入输出的维度均没有发生变化。
理论和具体代码实现还是有差别的。
2.1 小结
Encoder 总共包含6个 EncoderLayers 。每一个 EncoderLayer 包含2个 SubLayer:
SubLayer-1 做 Multi-Headed Attention
SubLayer-2 做 feedforward neural network
2.2 Decoder部分
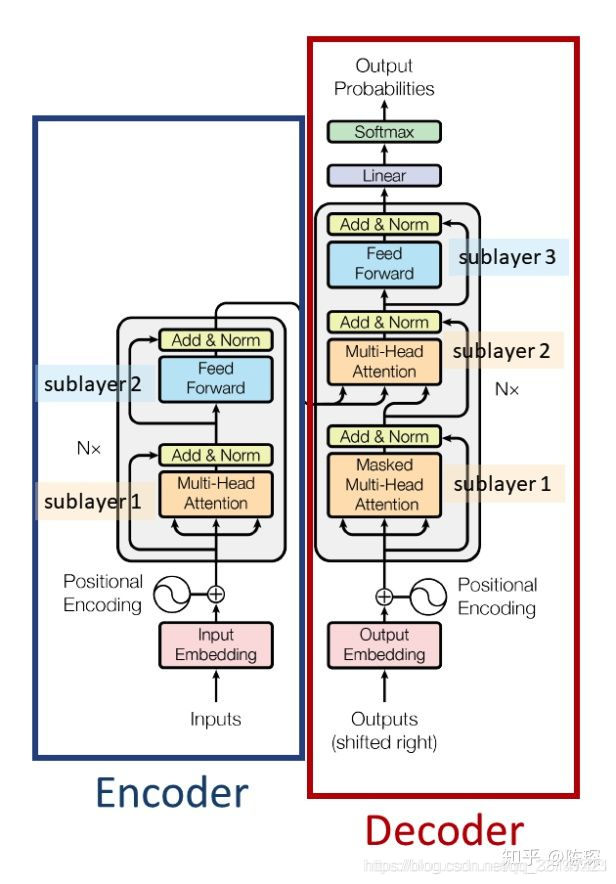
Decoder 也是N层堆叠的结构。被分为3个 SubLayer,可以看出 Encoder 与 Decoder 三大主要的不同:
- Diff_1:Decoder SubLayer-1 使用的是 “masked” Multi-Headed Attention 机制,防止为了模型看到要预测的数据,防止泄露(下面会进行解释)。
- Diff_2:Decoder SubLayer-2 是一个 encoder-decoder multi-head attention。这里的QKV中Q是自己的,KV是encoder给的。
- Diff_3:LinearLayer 和 SoftmaxLayer 作用于 SubLayer-3 的输出后面,来预测对应的 word 的 probabilities 。(注意本文所说的Decoder是包括输出层的!)
2.2.1 Diff_1 : “masked” Multi-Headed Attention
mask 的目标在于防止 decoder “seeing the future”,就像防止考生偷看考试答案一样。mask包含1和0:
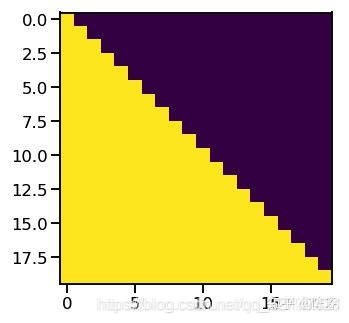
sequence mask:
sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为 1,下三角的值权威0,对角线也是 0。把这个矩阵作用在每一个序列上,就可以达到我们的目的啦。如上图所示.
x和y轴均为对应序列的index,矩阵下三角为0,是我们要进行mask的地方,预测序列的index为0时,什么都看不见;index为1时,可以看见0;以此类推进行处理。
- 对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个 mask 相加作为attn_mask。
- 其他情况,attn_mask 一律等于 padding mask。
为什么mask下三角为0,就看不到未来信息了?
仔细理解下scores是什么
对应代码以及attention的计算公式来看。

为什么mask为0,将scores中mask为0的用很小值替换就看不到未来信息了?
是因为替换了之后,scores经过softmax,所以看不到未来信息了。
2.2.2 Diff_2 : encoder-decoder multi-head attention
这里的QKV中Q是自己的,KV是encoder给的。
2.2.3 Diff_3 : Linear and Softmax to Produce Output Probabilities
2.2 小结

3、补充:
3.1 techer forcing
3.2 Transformer中的Add & Norm

3.3 残差连接
残差网络:残差网络打破了原始网络的对称性,最开始为了解决网络退化的问题而提出来的。
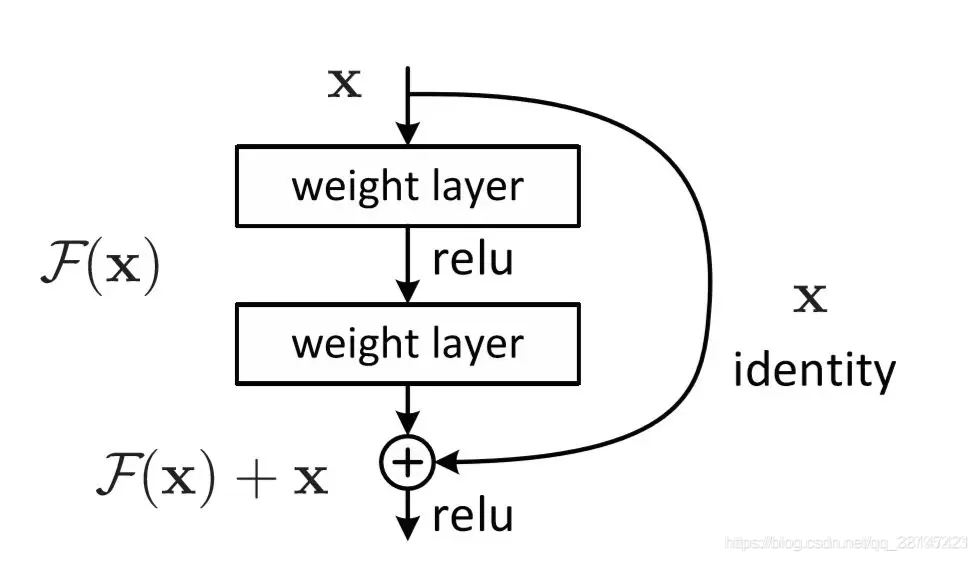
在transformer中使用的原因如下:
- 加入的原因还是往网络退化方面靠。
- 防止网络过深,导致网络退化,同时也可以一定程度缓解梯度消失/梯度爆炸的问题。
3.4 padding mask和sequence mask
面试:
1、介绍下transformer
(1)transformer中为什么用多头?
每个头各自做attention计算的时候,捕获的信息是不同的,也可以表示更多的信息。
(2)多头中每个头学到的东西是一样的吗?
刚开始随机初始化,那么学到的不一样的。
(4)为什么文本用LN呢?
LN可以对单个样本进行标准化。BN是对batch的标准化。
(5)decoder中刚开始多头带mask是干嘛呢?
防止看到未来信息呢
(6)为什么decoder中间的多头不带mask呢?
需要把encoder中输出编码的信息利用上的,对于中间的多头,需要把encoder中的信息充分利用,所以这里没有带mask。
(7)transformer的出现解决了什么问题?
- 解决了特征抽取能力,比如之前的LSTM,(LSTM是一个个进去),transformer相当于是并行的处理,一是高效,另一个包含了之前的语义。
- 也和参数量有关系,参数量大,学习能力也更强一些。最主要还是每个词包含其他词之间的语义。
(8)transformer比lstm优秀在哪里呢?
transformer中attention中的计算也是影响了效果好的原因。















 5385
5385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









