







Python 深度学习AI - 声音克隆、声音模拟
第一章:环境准备与安装
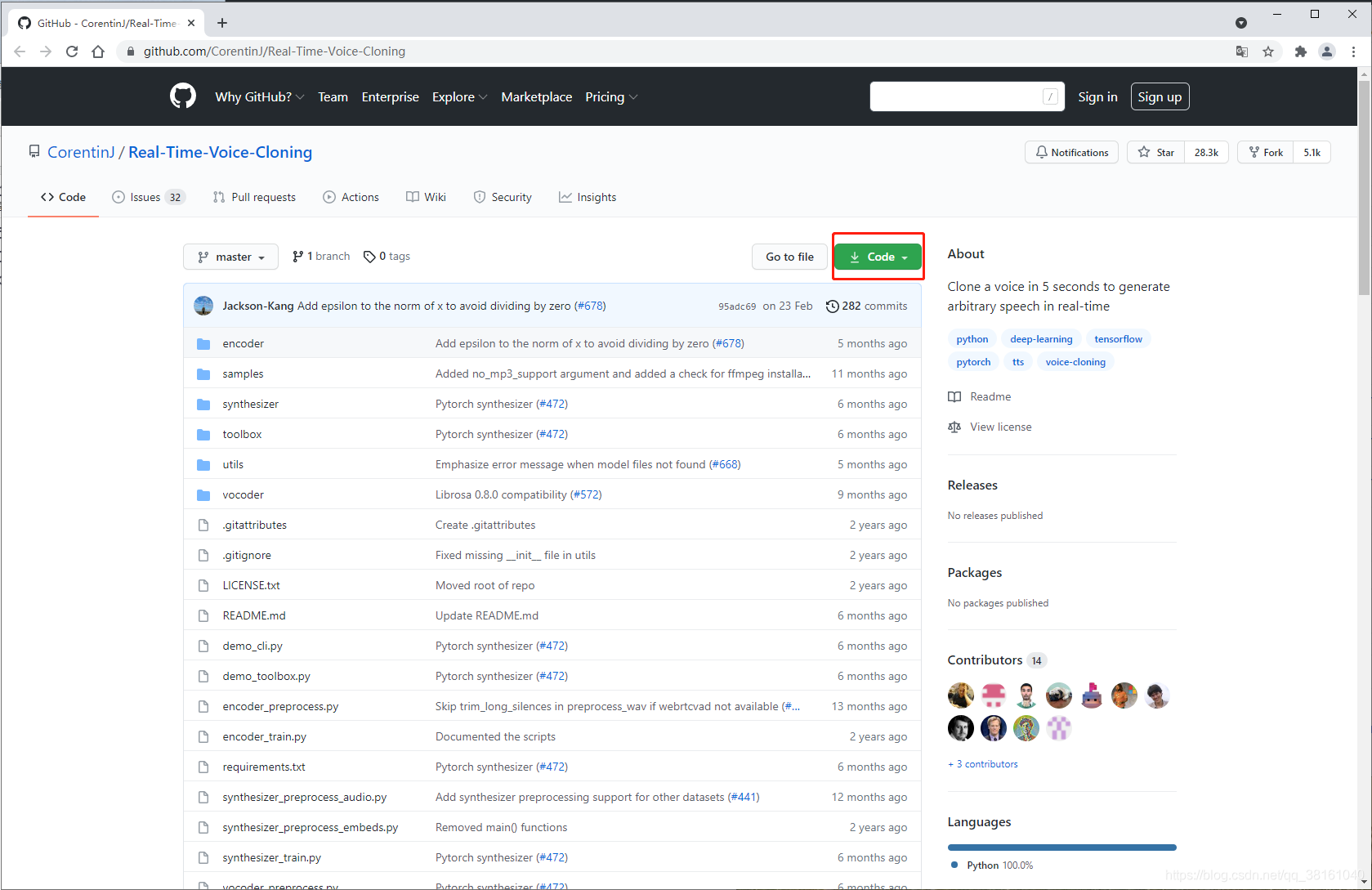
① Real-Time-Voice-Cloning 项目源码下载
获取地址:
github 官方
小蓝枣的 csdn 资源仓库
② requirments 必要库安装
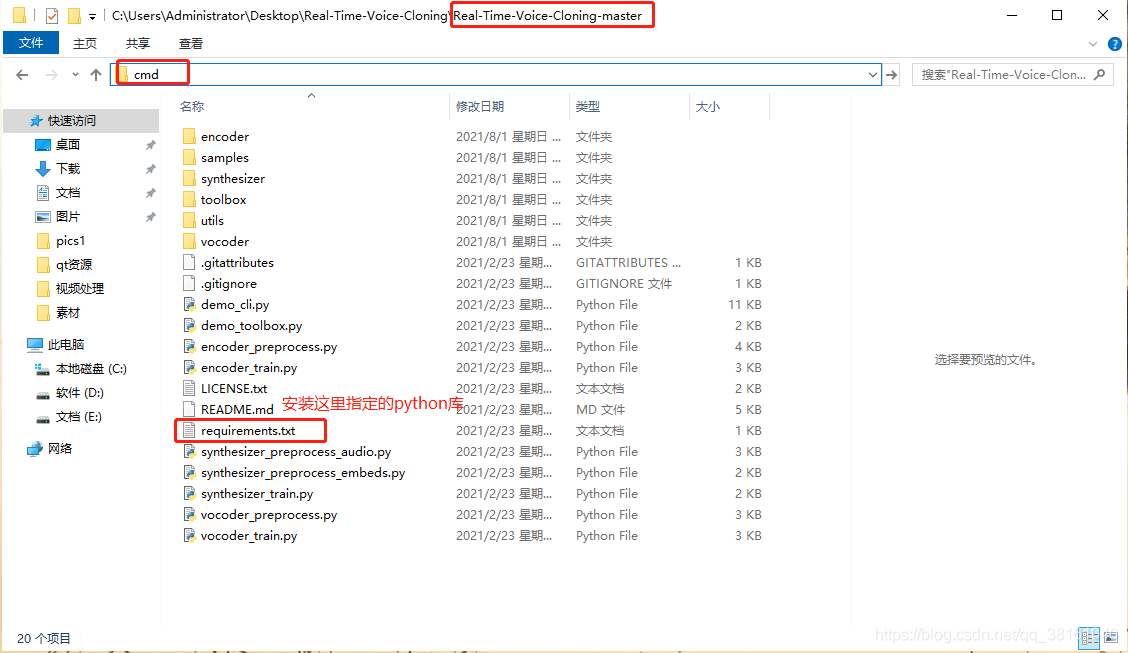
清单如下:
umap-learn
visdom
librosa>=0.8.0
matplotlib>=3.3.0
numpy==1.19.3; platform_system == “Windows”
numpy==1.19.4; platform_system != “Windows”
scipy>=1.0.0
tqdm
sounddevice
SoundFile
Unidecode
inflect
PyQt5
multiprocess
numba
webrtcvad; platform_system != “Windows”
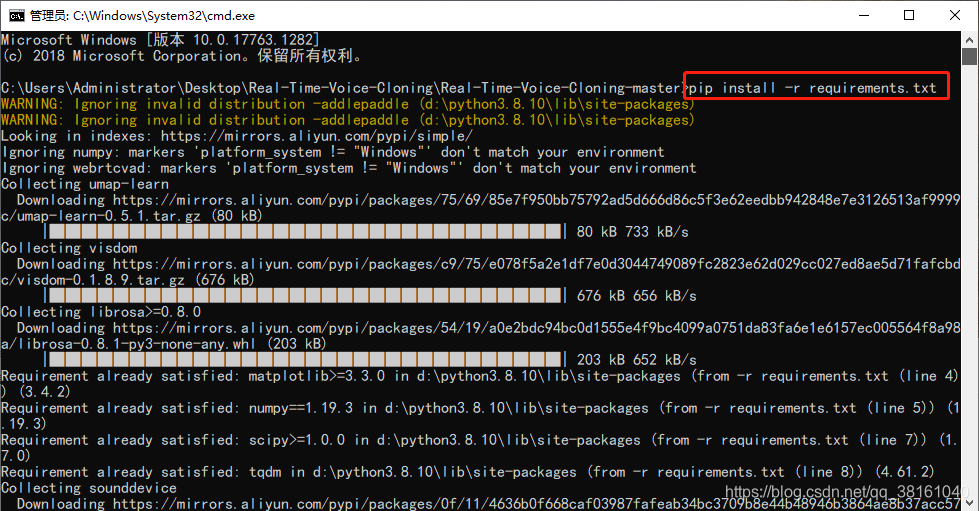
使用命令 pip install -r requirements.txt 进行安装。
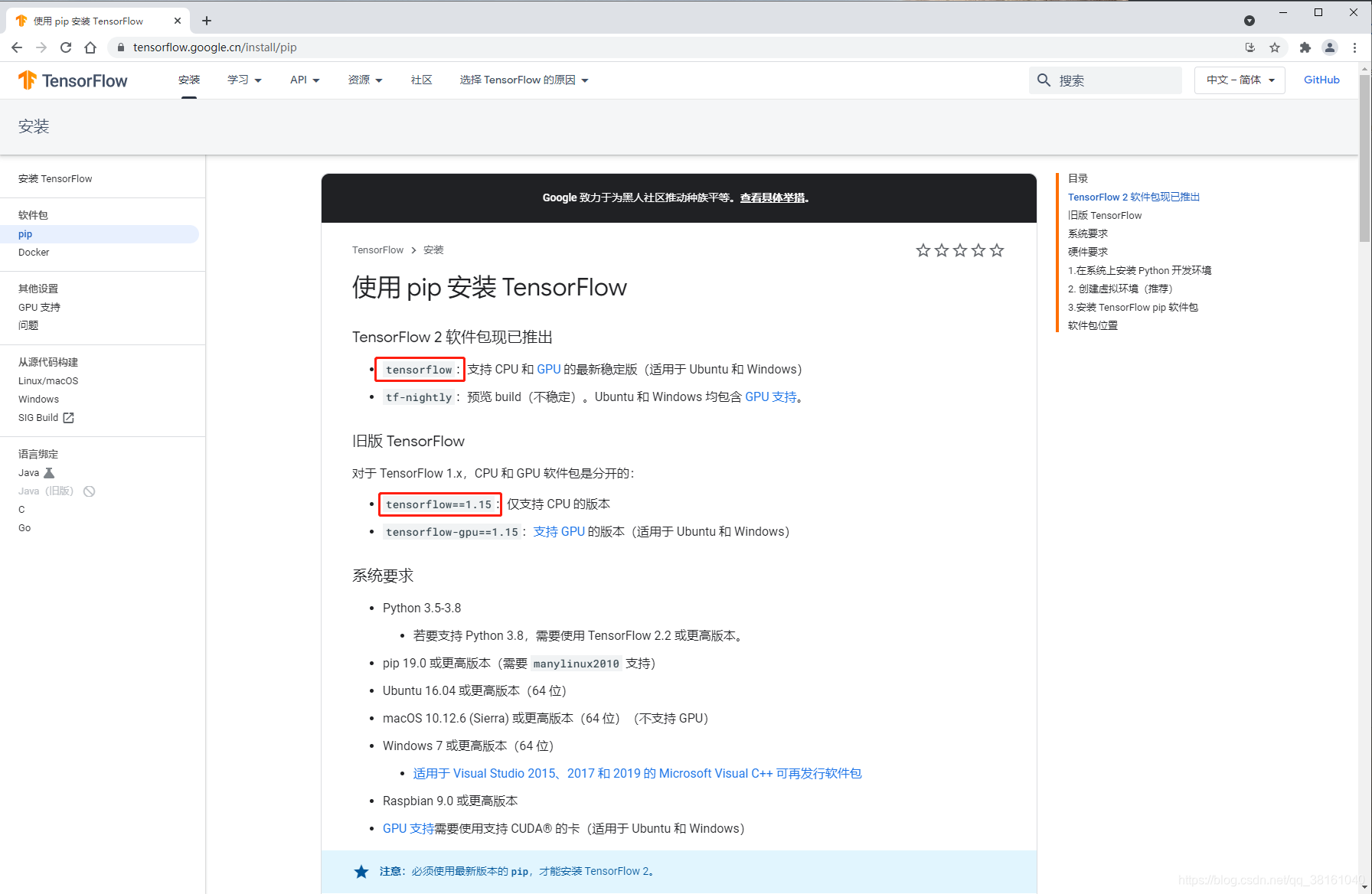
③ TensorFlow 安装
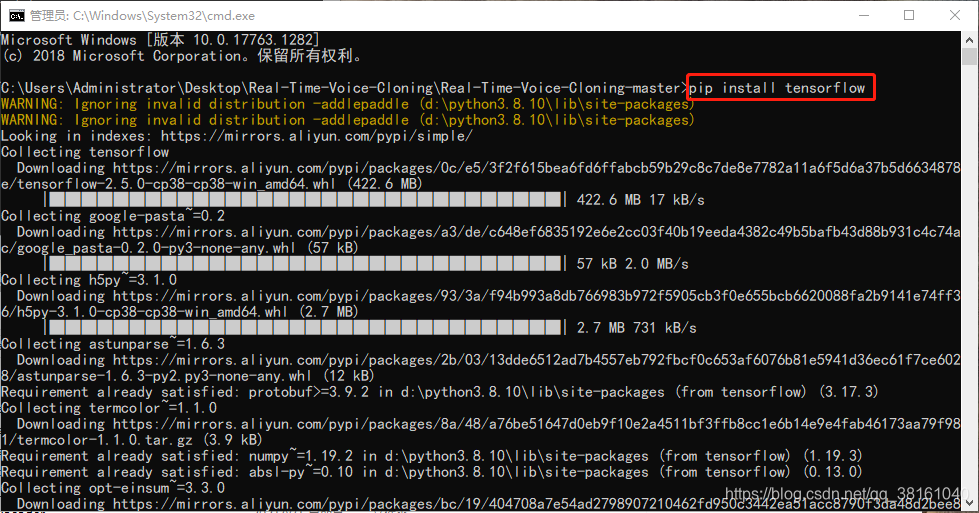
④ PyTorch 安装
PyTorch 官方网站
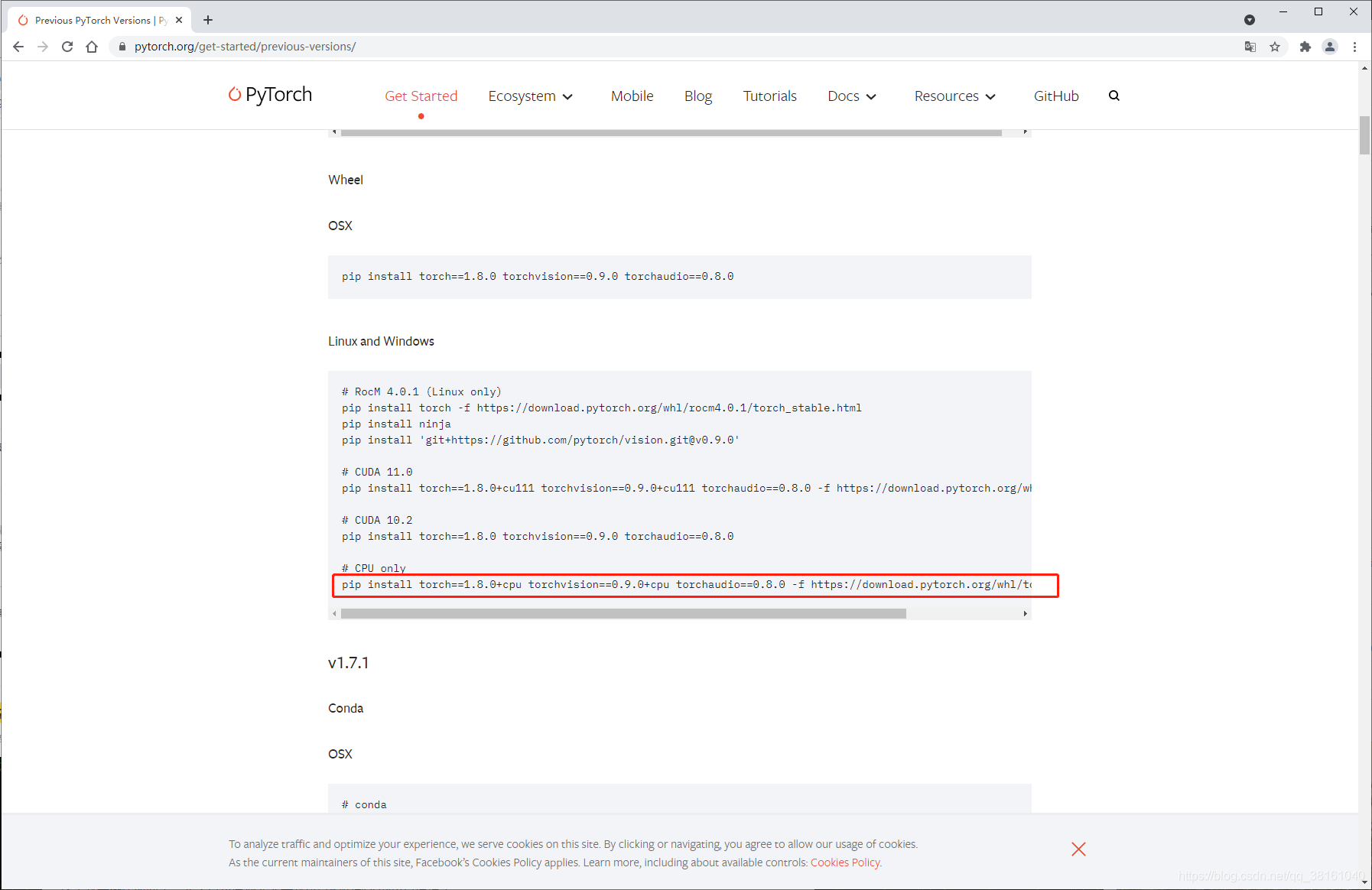
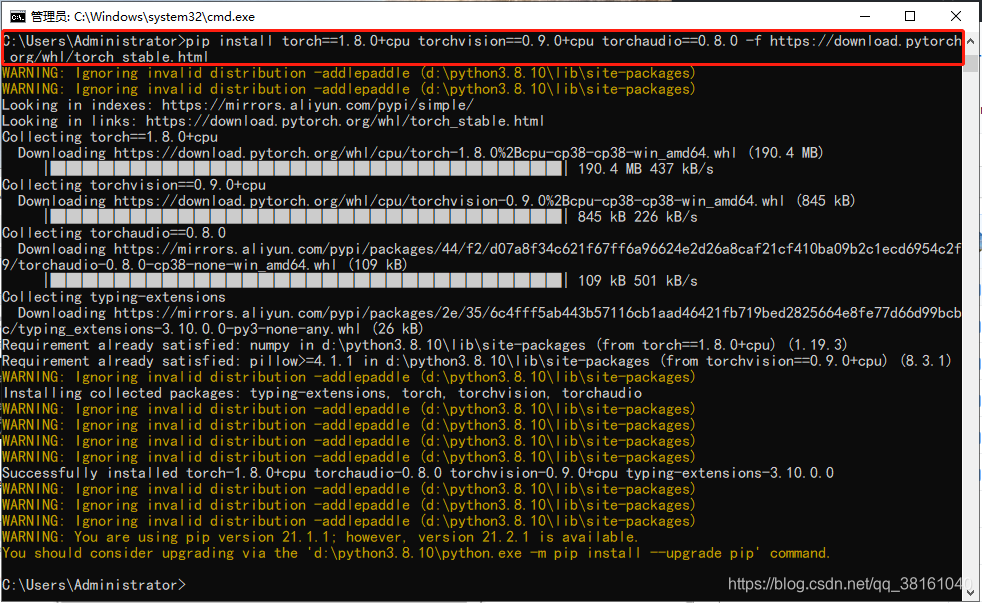
安装命令:pip install torch==1.8.0+cpu torchvision==0.9.0+cpu torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
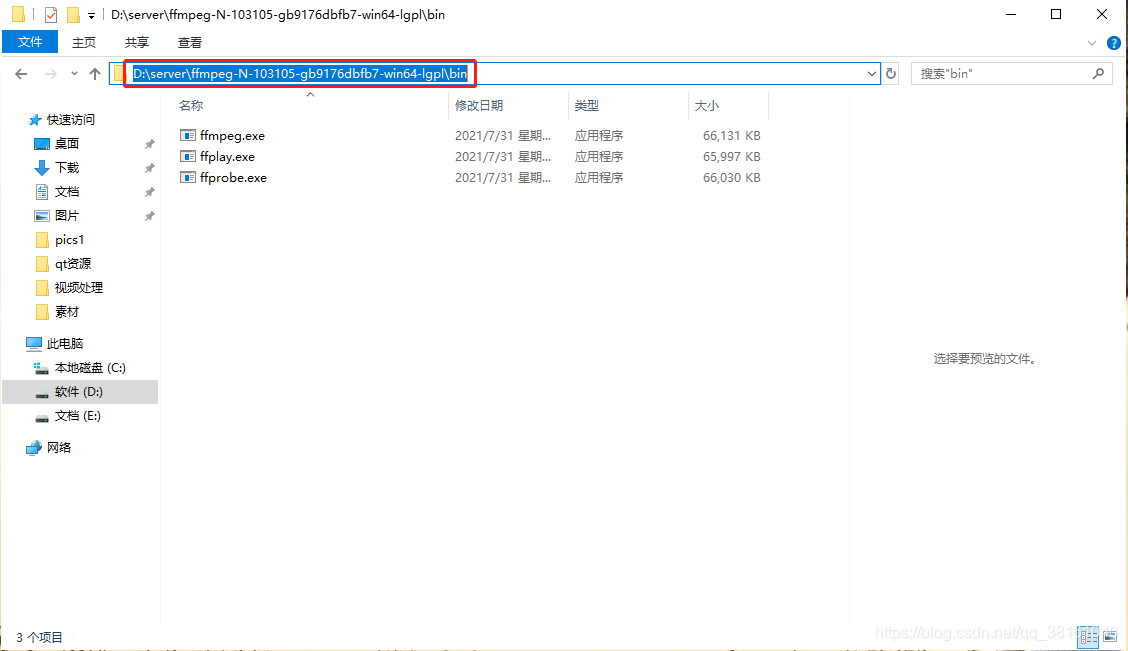
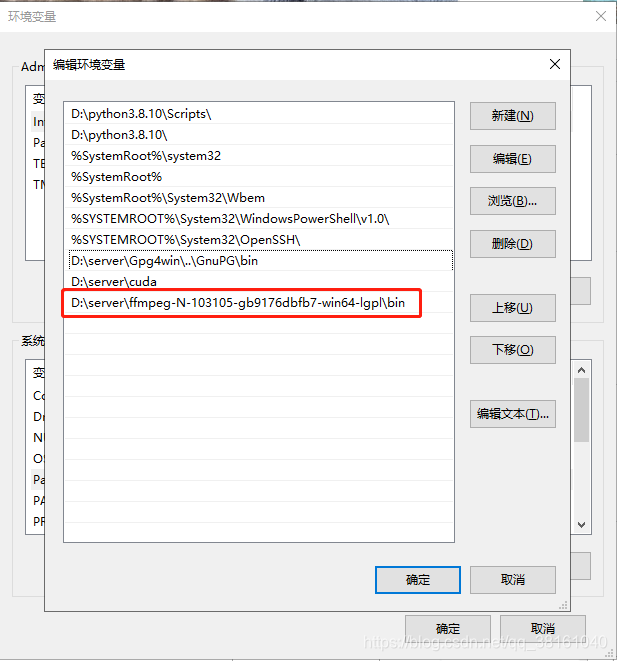
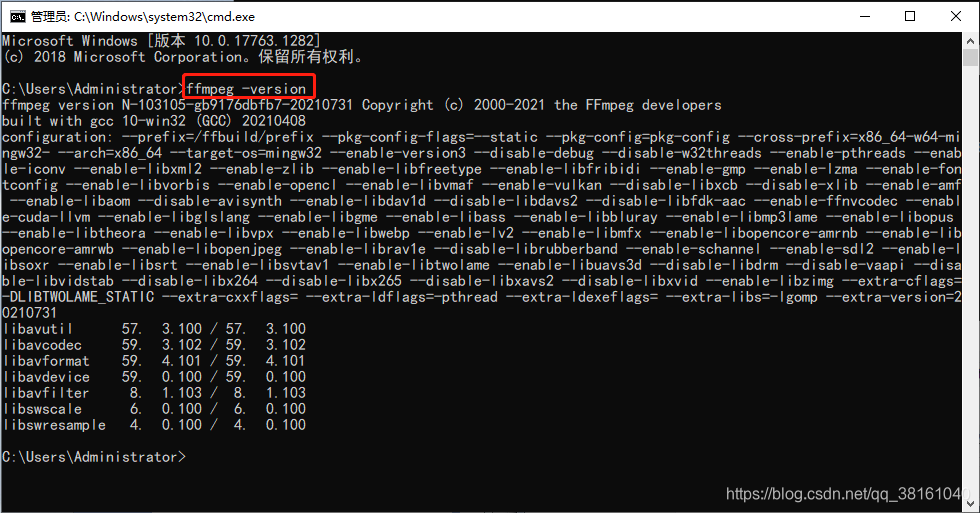
⑤ FFmpeg 下载环境变量配置
github 官方
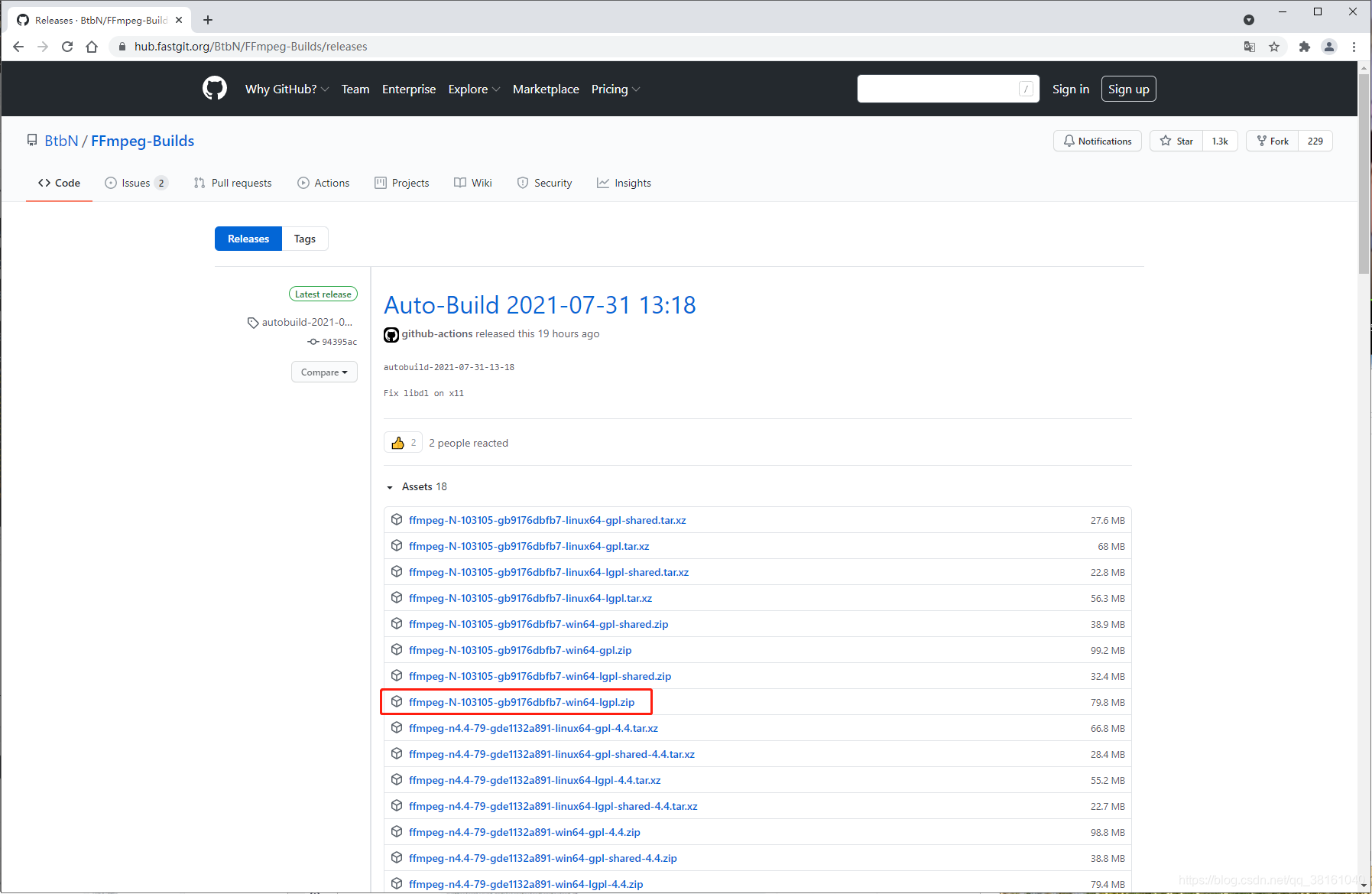
环境变量配置:
⑥ 下载训练包
获取地址:
github 官方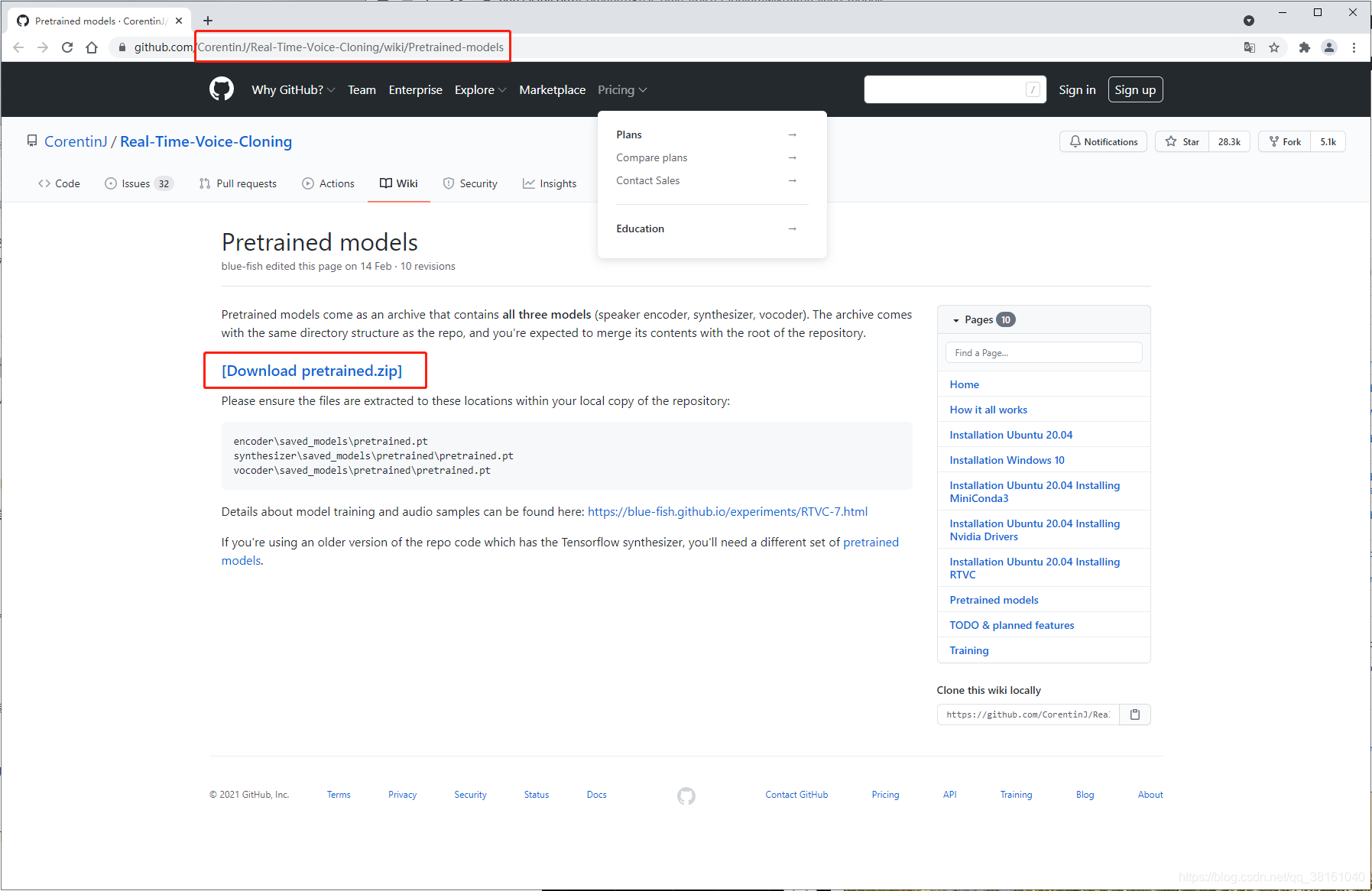
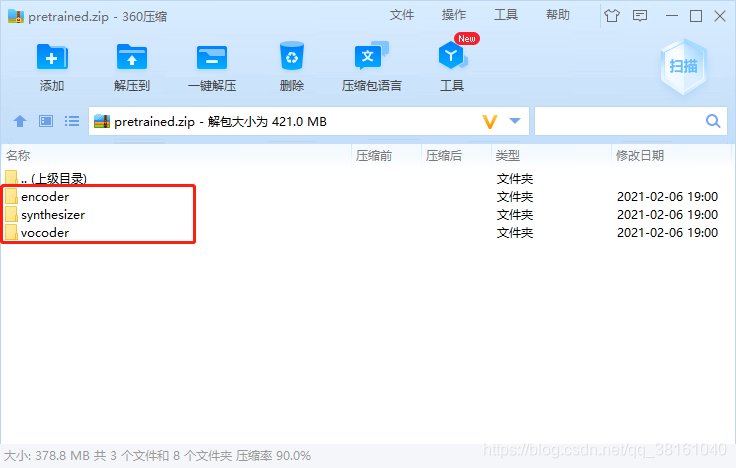
将训练包直接解压到项目根目录下。
第二章:效果测试
① 命令行合成音频测试:输入音频源和文本,合成目标
由于官方提供的训练库是英文版的,所以如果音频源是中文,或者合成中文内容效果不是很好,大家有兴趣的可以找一些中文训练包来进行测试。
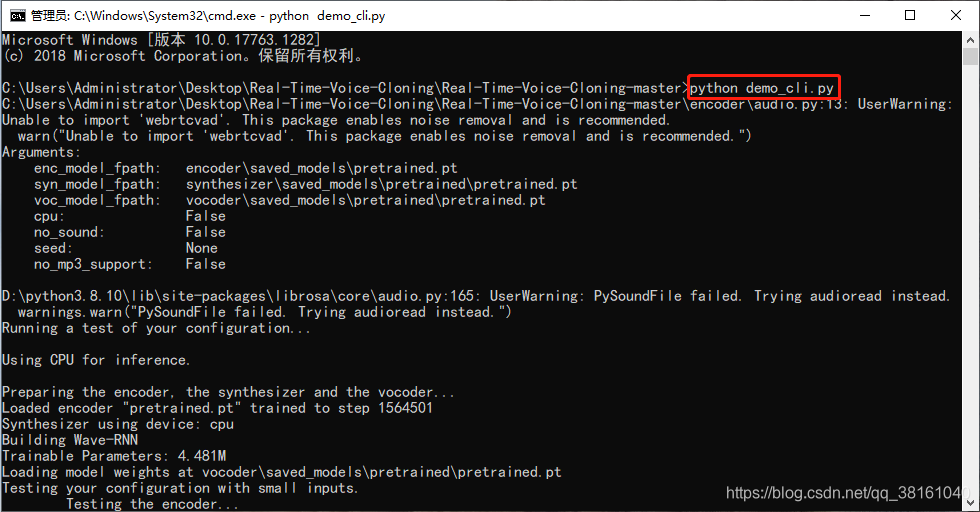
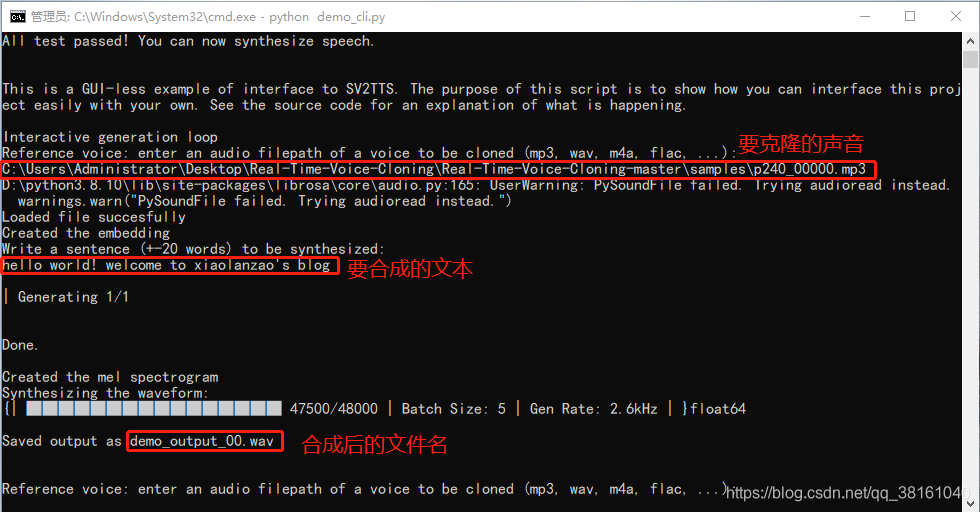
这是项目里给的声音源示例,可以用这个来进行测试。

合成后的音频文件。
② 工具箱合成音频测试,工具箱的使用方法介绍
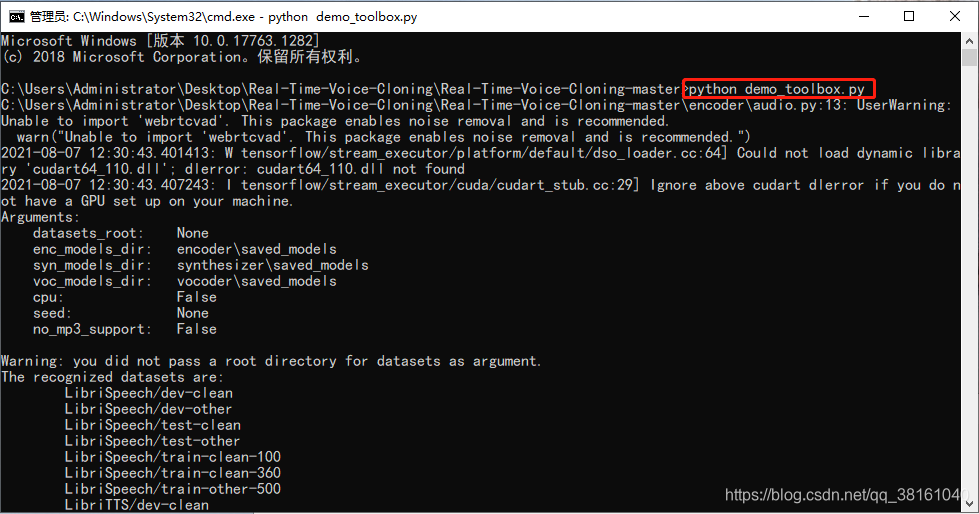
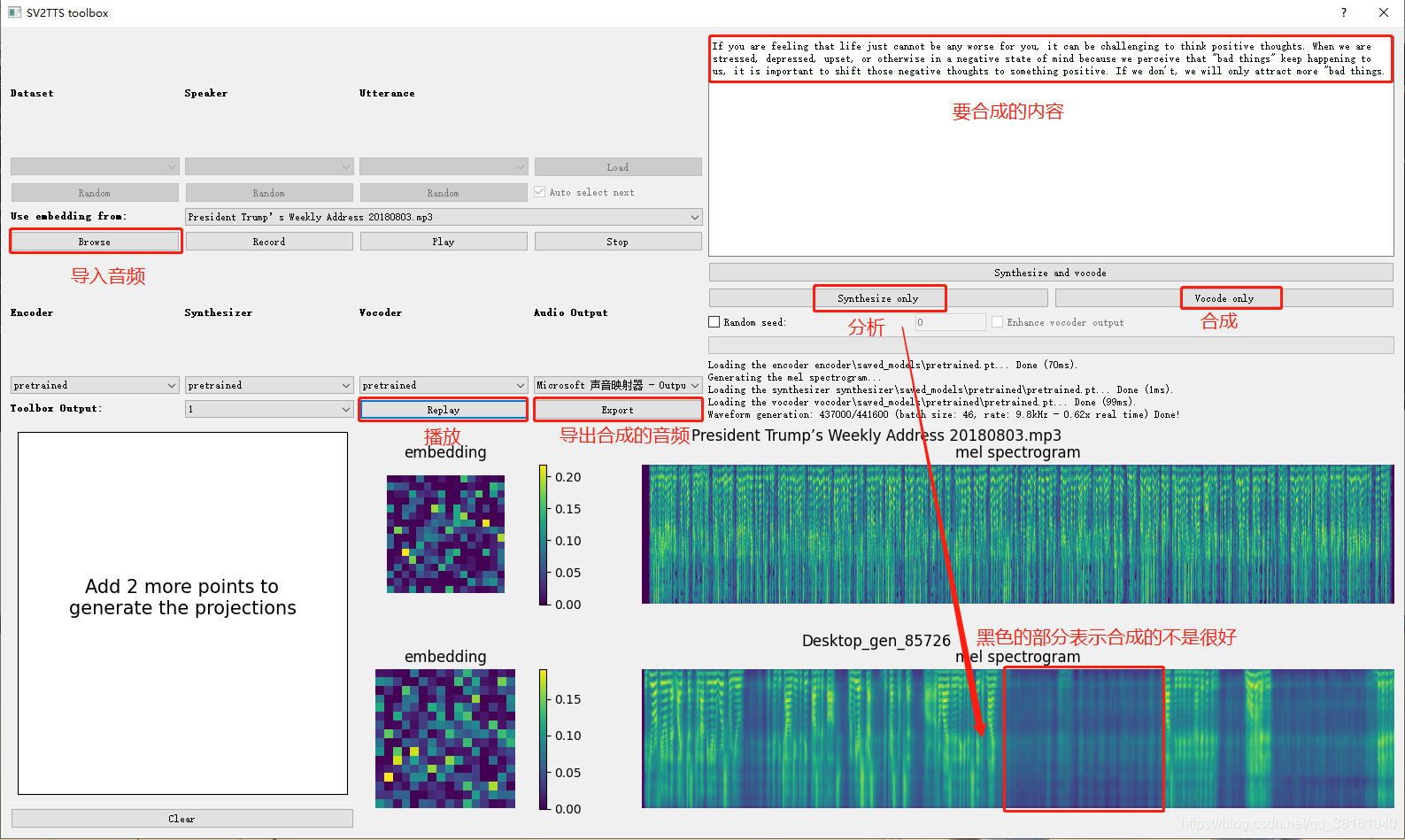
分析后黑色部分合成的不是很好,可以重新再分析一下,每次分析的效果都是不一样的。
③ 特朗普声音克隆,模拟特朗普讲话,特朗普唱《See You Again》
特朗普音频资源获取:
小蓝枣的 csdn 资源仓库
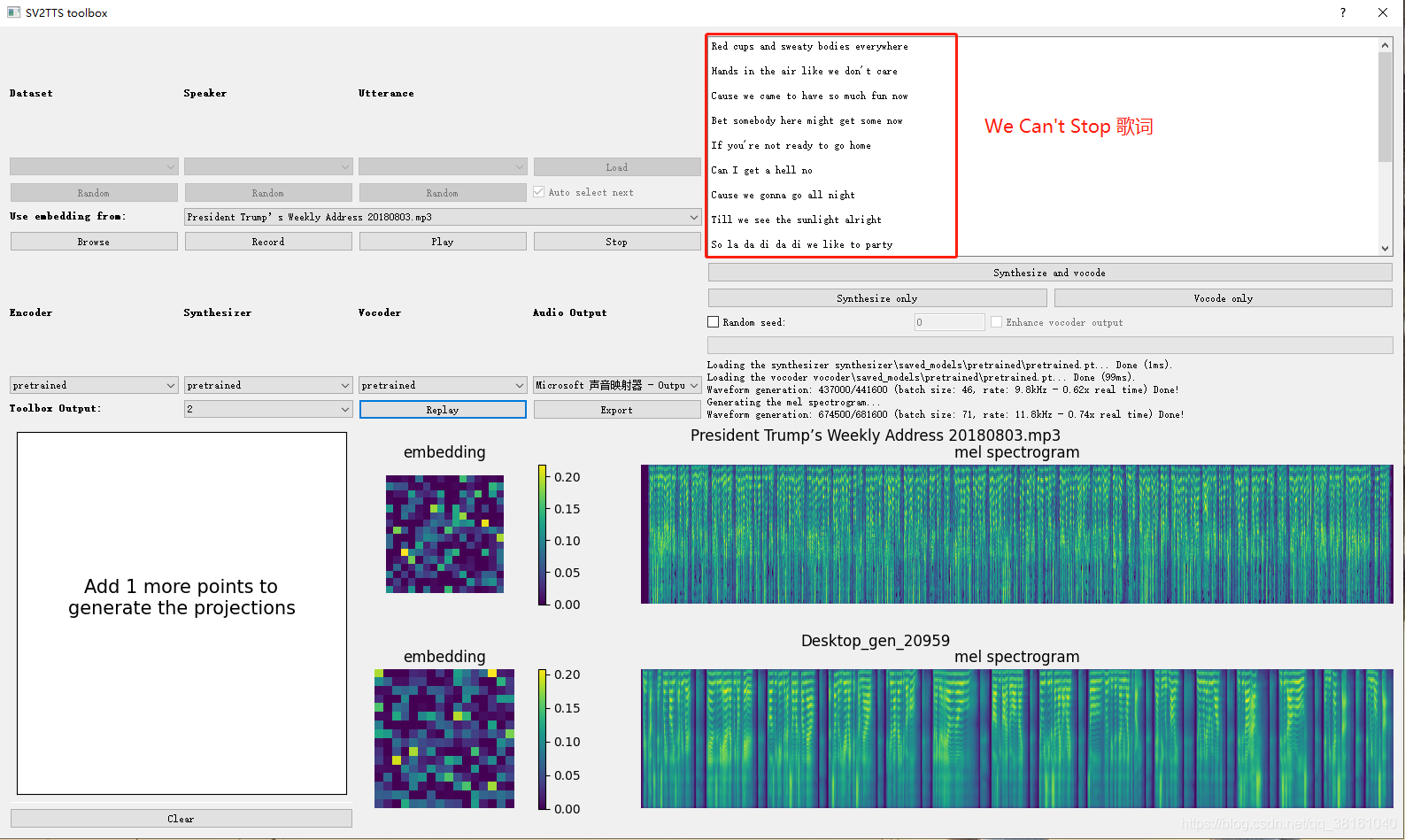
这是歌曲 《We Cant’t Stop》,合成的效果还不错,有的歌涉及断句的,给它加个回车断一下效果会更好,有层次感。
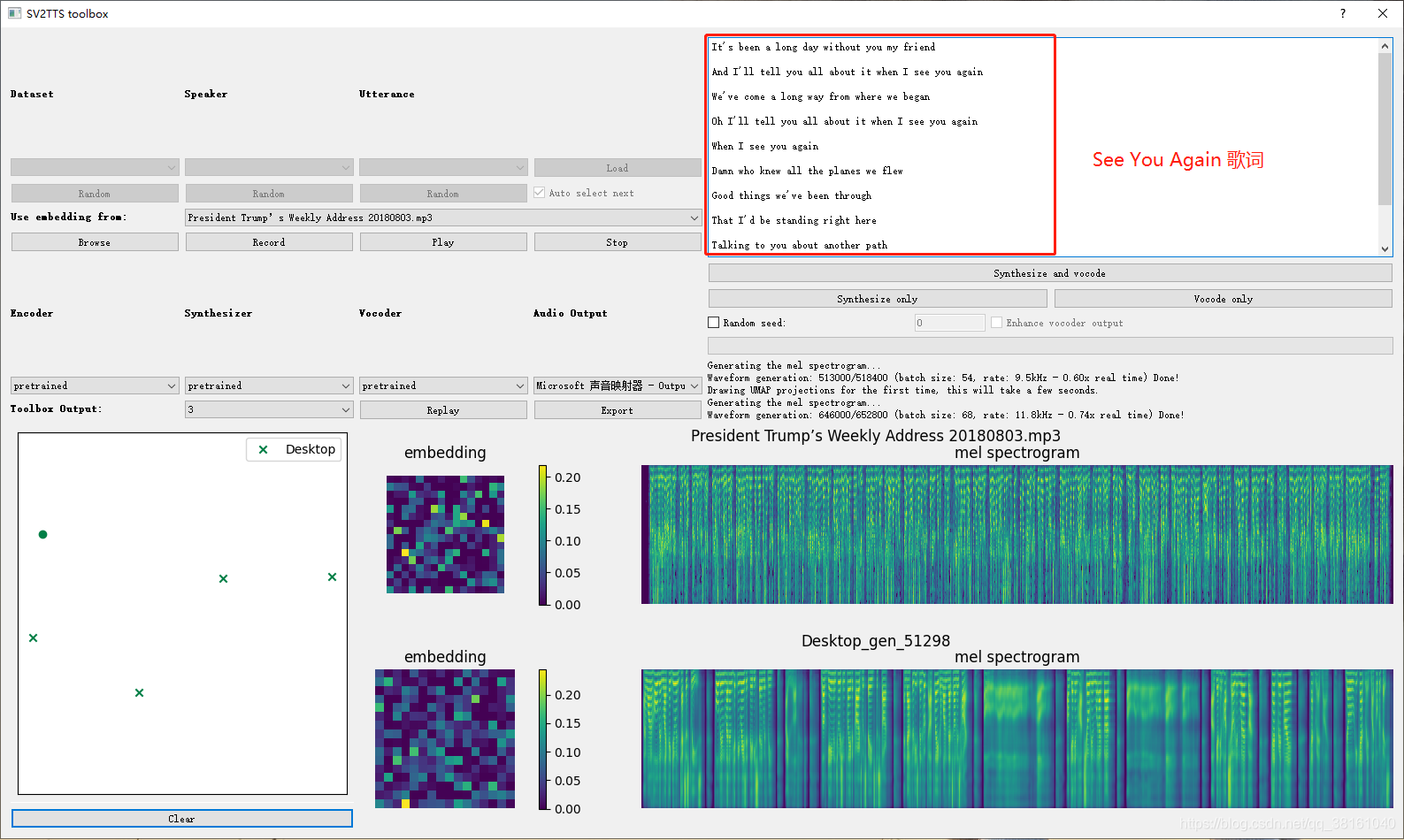
这是歌曲 《See You Again》,合成的效果也还行。
喜欢的点个赞❤吧!


















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











