







(1)什么是过度拟合问题?
在线性回归中的过拟合例子:
图1:是一个线性模型,欠拟合或者叫做高偏差,不能很好地适应我们的训练集;我们看看这些数据,很明显,随着房子面积增大,住房价格的变化趋于稳定或者说越往右越平缓。因此线性回归并没有很好拟合训练数据。
图2:恰当合适的拟合了数据
图3:完美的拟合了训练数据,称之为过拟合或者叫做高方差,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好。
换句话说就是:训练出的假设函数能很好的拟合数据集,可能会使代价函数非常接近零或等于零,千方百计的拟合数据集,就会导致模型预测新样本(没有出现在训练集的样本)的能力降低。

在Logistic回归中的过拟合例子:
图1:欠拟合或者叫做高偏差
图2:恰当合适的拟合了数据
图3:过拟合或者叫做高方差

如果我们发现了过拟合问题,应该如何处理?
(1)减少选取变量的数量,人工选择哪些变量保留哪些变量舍去
(2)正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
(2)正则化是如何运行的,当我们运行正则化的时候,还将写出相应的代价函数
我们从前面的图形可以看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了,所以我们要做的就是在一定程度上减小这些参数 θ 的值,这就是正则化的基本方法。
惩罚:就是指减少参数的大小。
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚(即一些不重要的参数),我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度,这样我们就得到了一个更简单的可以防止过拟合问题的假设:
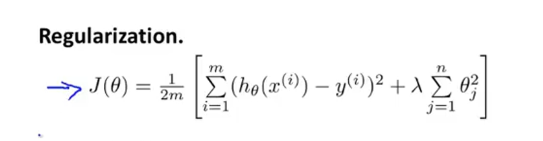
其中 λ 又称为正则化参数,
因为如果我们令 λ 的值很大的话,为了使代价函数 尽可能的小,所有的 θ的值(不包括 θ 0 )都会在一定程度上减小。但若 λ 的值太大了,那么 θ(不包括 θ 0 )都会趋近于0,这样我们所得到的只能是一条平行于 x 轴的直线。
所以对于正则化,我们要取一个合理的 λ 的值,这样才能更好的应用正则化。
(3)线性回归的正则化
正则化线性回归的优化目标/代价函数

正则化代价函数用梯度下降进行最小化
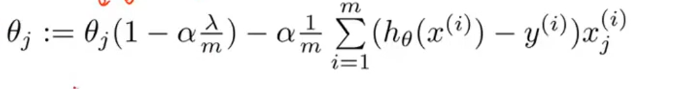
(4)Logistic回归的正则化
正则化Logistic回归代价函数:
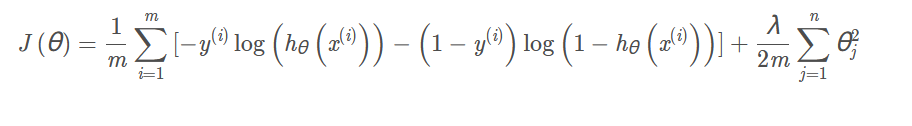
正则化代价函数用梯度下降进行最小化
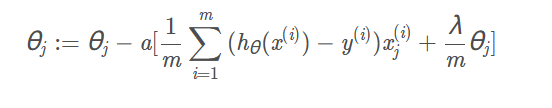
注意:
虽然正则化的Logistic回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的 h θ ( x ) 不同所以还是有很大差别。
θ0不参与其中的任何一个正则化。















 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









