






 该博客介绍了PageRank算法在推荐系统中的应用,用于生成用户推荐列表。算法基于用户在网页浏览行为的模拟,通过迭代计算每个节点(物品)的权重,最终为特定用户推荐权重较高的物品。代码实现了一个PageRank算法的Python版本,并展示了如何为用户A推荐物品。尽管有效,但该方法对每个用户的时间复杂度较高。
该博客介绍了PageRank算法在推荐系统中的应用,用于生成用户推荐列表。算法基于用户在网页浏览行为的模拟,通过迭代计算每个节点(物品)的权重,最终为特定用户推荐权重较高的物品。代码实现了一个PageRank算法的Python版本,并展示了如何为用户A推荐物品。尽管有效,但该方法对每个用户的时间复杂度较高。

上图展示了此算法的原理。一开始这个算法主要是应用于用户浏览网页。
用户随机打开一个网页,之后它可以选择退出或者点击网页里的链接跳转到其他的网页,下一个网页同样还是一样的选择,对于这种情况,用户选择跳转的概率是1/n,n是网页的个数。
把这种情况迁移到用户物品的二分图上,
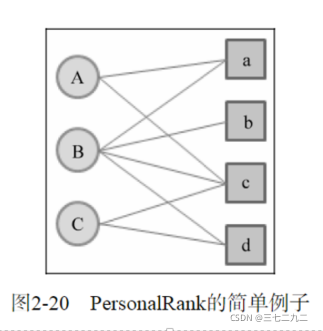
我们认为每个节点被访问的概率可以代表推荐列表中物品的权重。
利用上面的公式迭代,求某一个用户的推荐列表。
下面是代码;
# coding:utf-8
import time
def PersonalRank(G, alpha, root, max_depth):
#rank字典用于存储每个节点和它对应的权值
rank = dict()
#初始值都设为0
rank = {x: 0 for x in G.keys()}
#但是我们要求的用户的权值初始值是1
rank[root] = 1
# 开始迭代
begin = time.time()
#迭代k次
for k in range(max_depth):
#一个暂时存储这次迭代的权值结果的tmp字典
tmp = {x: 0 for x in G.keys()}
# 取出节点i和他的出边尾节点集合ri
for i, ri in G.items():
# 取节点i的出边的尾节点j以及边E(i,j)的权重wij,边的权重都为1,归一化后就是1/len(ri)
for j, wij in ri.items():
#利用公式更新每个节点的权值,注意,rank[i]是上一次迭代时的出节点的权值
tmp[j] += alpha * rank[i] / (1.0 * len(ri))
#更新所求用户的权值
tmp[root] += (1 - alpha)
#把tmp的值赋给rank字典
rank = tmp
end = time.time()
print('use_time', end - begin)
#把rank里的键值对,按照权值降序排列
lst = sorted(rank.items(), key=lambda x: x[1], reverse=True)
for ele in lst:
#既然要求推荐列表,那么用户要略去,此外用户浏览过的那些物品也不能再给用户推了
if(ele[0] not in {'A','B','C'} and ele[0] not in G.get(root)):
#把它们(物品名,权值)打印出来
print("%s:%.3f, \t" % (ele[0], ele[1]))
return rank
if __name__ == '__main__':
alpha = 0.8
G = {'A': {'a': 1, 'c': 1},
'B': {'a': 1, 'b': 1, 'c': 1, 'd': 1},
'C': {'c': 1, 'd': 1},
'a': {'A': 1, 'B': 1},
'b': {'B': 1},
'c': {'A': 1, 'B': 1, 'C': 1},
'd': {'B': 1, 'C': 1}}
PersonalRank(G, alpha, 'A', 50)
运行结果:
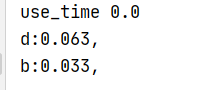
所以,给用户A推荐的物品列表是{d,b}
这种算法的问题:
对于每个用户都得进行一次这个操作,时间复杂度非常高。
(注:代码来自我也不知道是谁的大佬,我修改了一下,
图片来自项亮老师的《推荐系统实战》(也许是实践,我不记得了))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









