









 K同学介绍了基于LSTM的电商评论情感分析,增加了多种评价指标的可视化,并在数据预处理阶段进行了分词、去除停用词、Word2vec处理,同时提供了训练集和测试集的划分。
K同学介绍了基于LSTM的电商评论情感分析,增加了多种评价指标的可视化,并在数据预处理阶段进行了分词、去除停用词、Word2vec处理,同时提供了训练集和测试集的划分。
- 🔗 运行环境:python3
- 🚩 作者:K同学啊
- 🥇 精选专栏:《深度学习100例》
- 🔥 推荐专栏:《新手入门深度学习》
- 📚 极品专栏:《Matplotlib教程》
- 📔 选自专栏:《自然语言处理NLP-实例教程》
- 🧿 优秀专栏:《Python入门100题》
大家好,我是K同学啊!
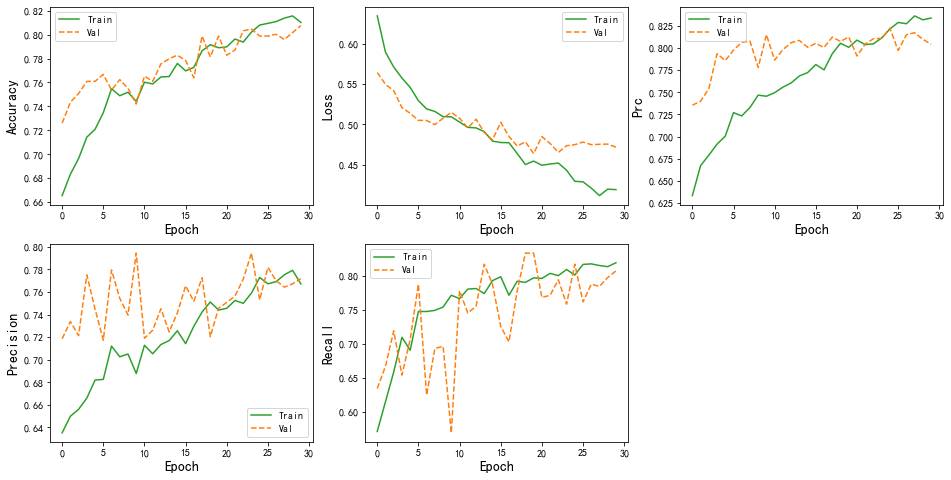
在上一篇文章中,我使用LSTM对电商评论做了一个较为复杂的情感分析,本文就继续上次的工作做进一部分的分析。本次主要是在评价指标metrics处增加了Precision、Recall、AUC等值,实现了训练模型的同时记录这些指标,是实现方式上与以往也有所不同。与此同时,本次全连接层Dense的输出也被设置为1,之前很少这样操作的,可以对这块针对性学习一下。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 4238
4238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











